Nvidia представила CUDA Tile — новый подход к программированию для будущих архитектур
Nvidia выпустила обновление CUDA 13.1, которое вводит новый подход к программированию под названием CUDA Tile. Эта модель смещает фокус разработчиков с управления отдельными потоками (SIMT) на работу с блоками структурированных данных — «тайлами», что закладывает основу для эффективной работы на архитектурах Blackwell и будущих поколениях, таких как Rubin и Feynman.
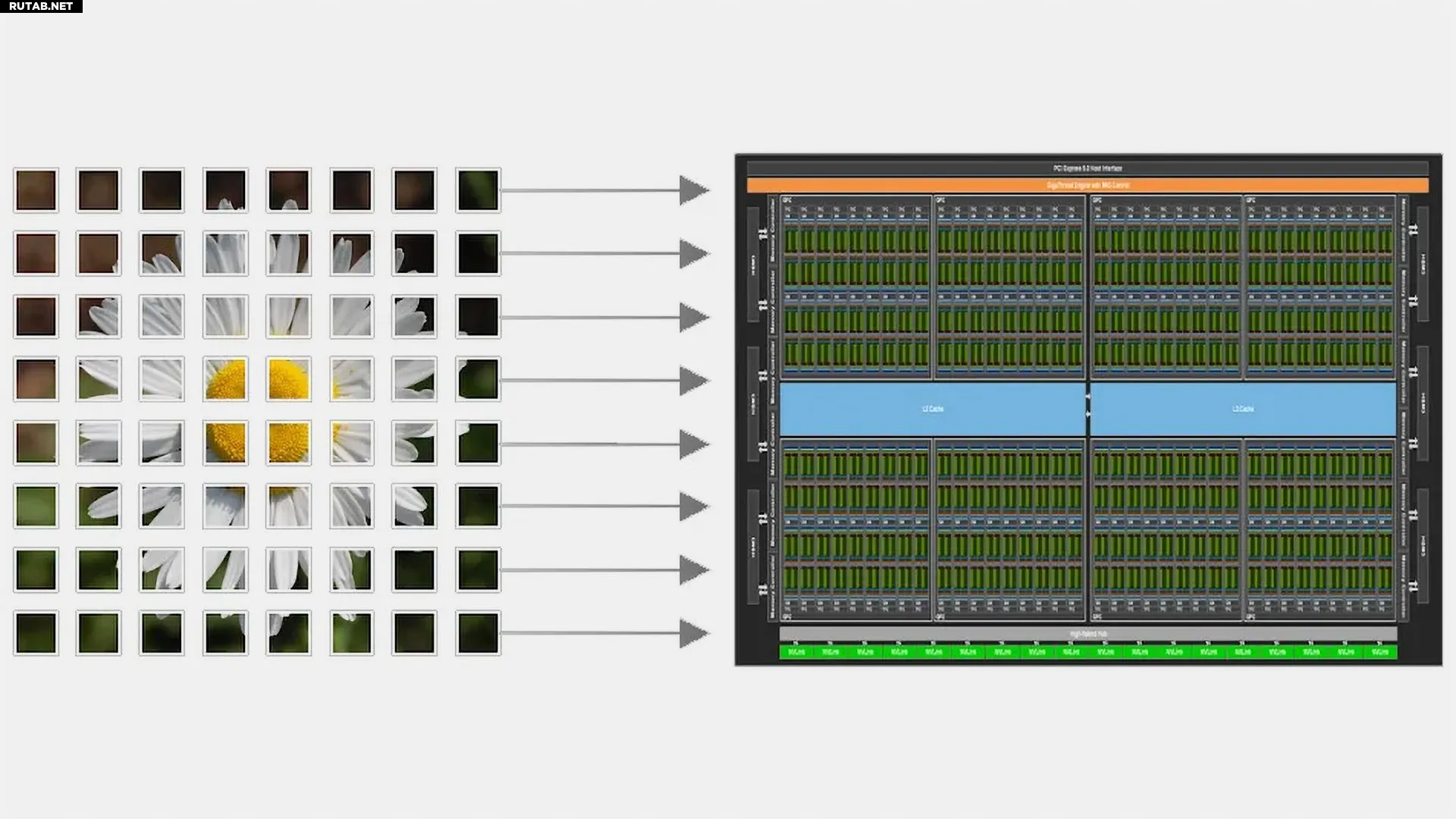
Традиционная модель CUDA требует от программиста детального управления потоками, блоками и шаблонами доступа к памяти для оптимизации под конкретное аппаратное обеспечение. Новая модель CUDA Tile позволяет описывать вычисления на уровне операций с тайлами (например, подматрицами), а компилятор и среда выполнения автоматически распределяют задачи по потокам, тензорным ядрам и ускорителям памяти.

Этот шаг обусловлен эволюцией архитектуры GPU, где тензорные операции становятся основными, а аппаратные реализации тензорных ядер и ускорителей памяти (TMA) меняются от поколения к поколению. Абстракция на уровне тайлов обеспечивает переносимость и масштабируемость производительности.
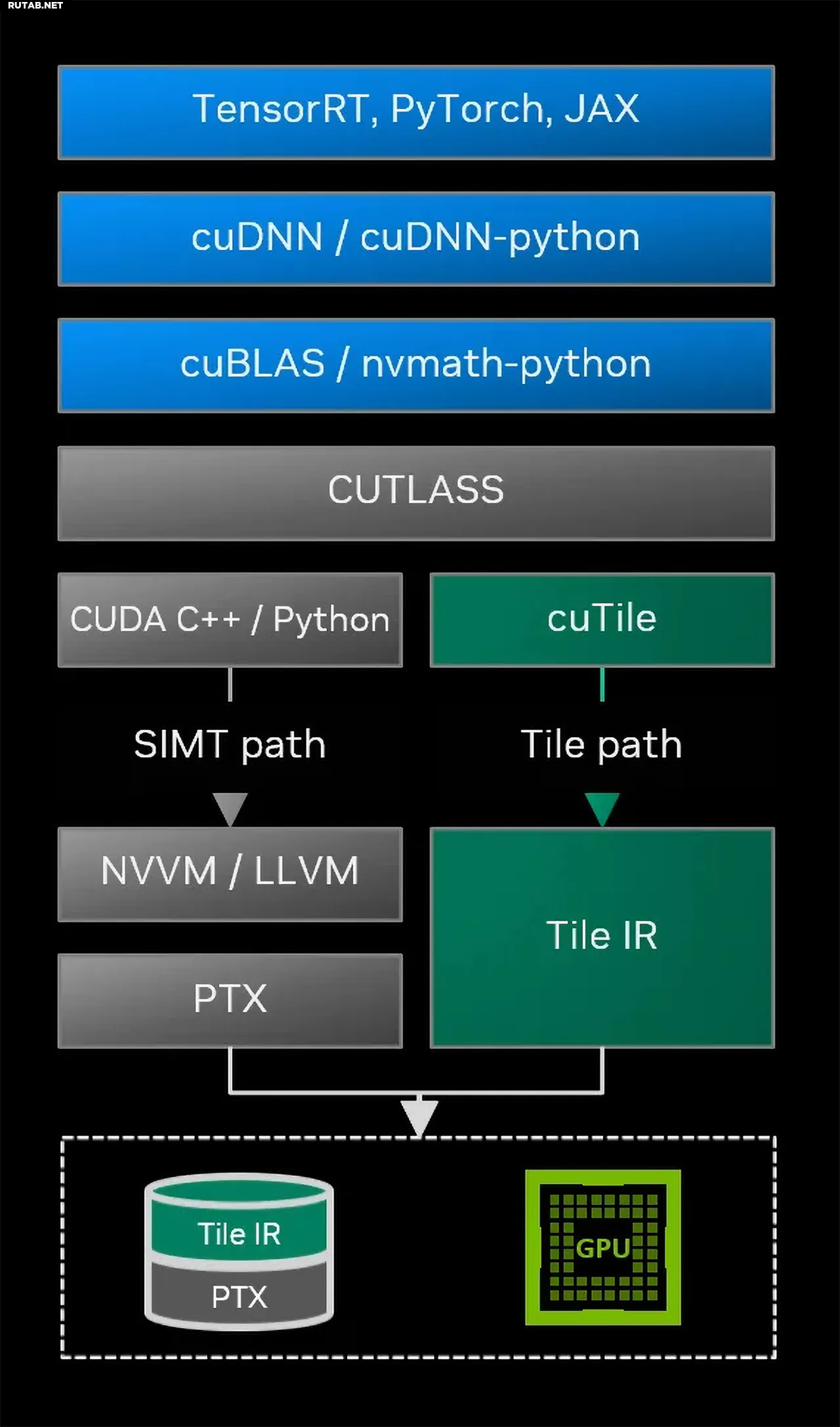
Ключевым компонентом новой системы стал CUDA Tile IR — виртуальный набор инструкций для тайловых вычислений, аналогичный PTX для SIMT. Он обеспечивает стабильность для кросс-платформенной разработки. Также представлен cuTile Python — предметно-ориентированный язык для написания тайловых ядер прямо на Python.

Изначально поддержка CUDA Tile доступна для GPU архитектуры Blackwell. В будущем её планируется расширить на другие архитектуры. Этот подход позиционируется как стратегический шаг для упрощения программирования и автоматического извлечения производительности из будущих тензорно-ориентированных GPU.






0 комментариев