Исследование MIT: как языковые модели вели себя во время выборов 2024 года

Исследователи из Массачусетского технологического института (MIT) провели масштабное исследование, чтобы выяснить, как большие языковые модели (LLM) реагируют на вопросы, связанные с выборами. В течение четырёх месяцев, с июля по ноябрь 2024 года, команда ежедневно тестировала 12 современных моделей, используя более 12 000 различных запросов. В результате был собран уникальный набор данных, содержащий свыше 16 миллионов ответов ИИ.
Учёные отмечают, что выборы 2024 года стали первыми, которые прошли после широкого распространения LLM в ноябре 2022 года. В отличие от социальных сетей, влияние которых уже изучено, языковые модели способны на более тонкое и потенциально манипулятивное поведение: они могут льстить, вводить в заблуждение или укреплять определённые идеи.
Исследование выявило несколько интересных закономерностей. Например, LLM демонстрировали сильные ассоциации между кандидатами и их личностными чертами, такими как «компетентность» или «вспыльчивость». Эти ассоциации менялись со временем. После того как Камала Харрис была официально выдвинута кандидатом от Демократической партии 5 августа, оценки Джо Байдена почти по всем параметрам, кроме «некомпетентности», снизились. Некоторые из его утраченных ассоциаций, такие как «харизматичный» и «сострадательный», перешли к Харрис, а «компетентный» и «заслуживающий доверия» — к Дональду Трампу.
Модели также по-разному уклонялись от ответов. На вопросы о чертах кандидатов варианты «Другое» или «Не уверен» часто превышали 40%. Прилагательные вроде «этичный», «слабый» и «некомпетентный» с высокой вероятностью вызывали отказ от ответа. Модели GPT-4 и Claude чаще уклонялись, в то время как Perplexity отвечала более прямо.
Кроме того, LLM предсказывали настроения избирателей. На вопрос о том, будет ли жизнь следующего поколения американцев лучше нынешней, модели прогнозировали, что сторонники Харрис более оптимистичны, а сторонники Трампа — более пессимистичны. Интересно, что модели были непоследовательны: в вопросах о налогах и инфляции GPT-4o неявно указывала на сторонников Трампа как на более репрезентативных, а в вопросах об образовании и расовом равенстве — на сторонников Харрис.
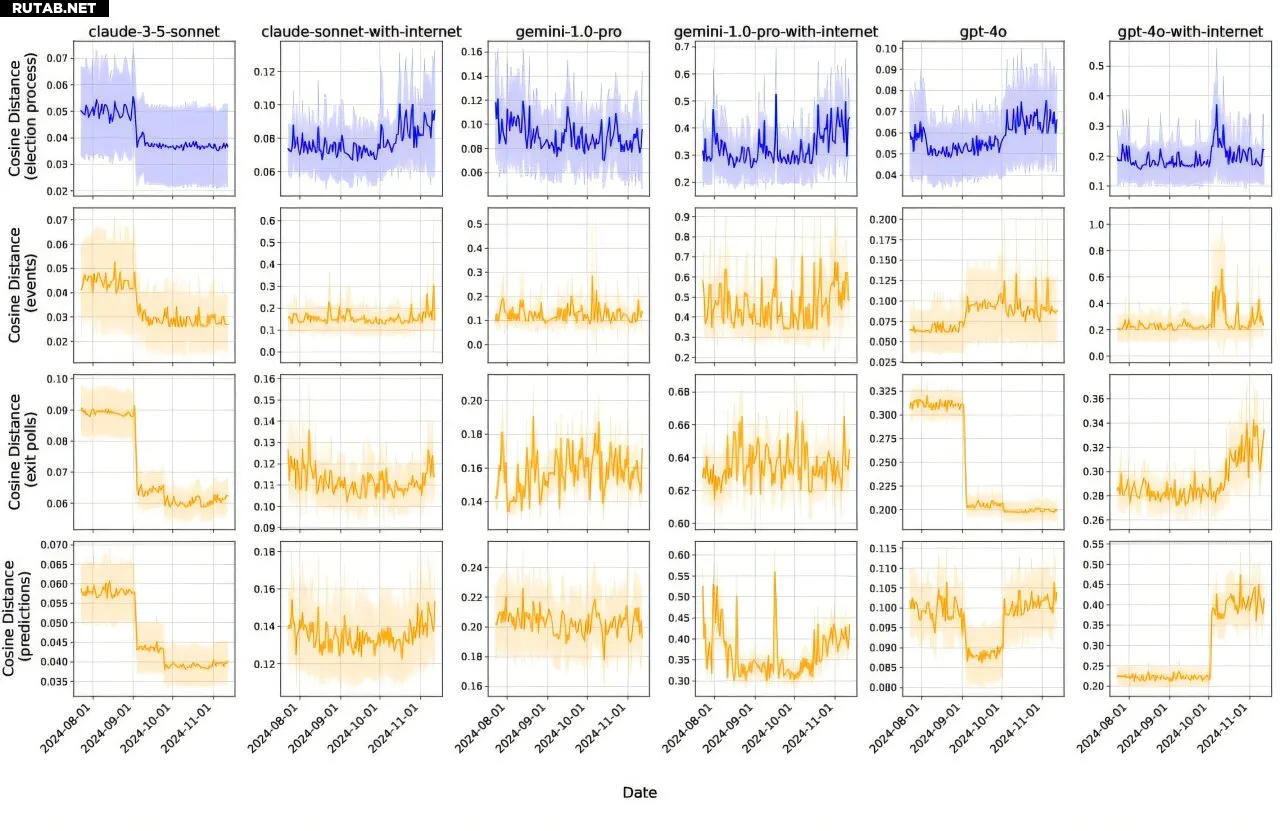
Исследование также показало, что даже детерминированные офлайн-модели демонстрировали резкие изменения в ответах в определённые даты, что может быть связано с обновлениями или внутренними процессами, невидимыми для пользователей. Формулировка запроса и указание политических предпочтений или пола пользователя также значительно влияли на выводы моделей.
Цель проекта, по словам ведущего автора Сары Сен и старших авторов Александра Мэдри и Хара Подомата, — предоставить методологию и данные для изучения поведения ИИ в политически чувствительных контекстах. В будущем команда планирует сравнить выводы моделей с реальными опросами и расширить исследования на другие демократии.

0 комментариев