Создан инструмент для систематизации знаний о металлоорганических каркасах
Исследователи из Университета Торонто разработали открытый инструмент MOF-ChemUnity, который систематизирует знания о металлоорганических каркасах (MOF) — классе материалов с применением в доставке лекарств, катализе, захвате углерода и других областях.
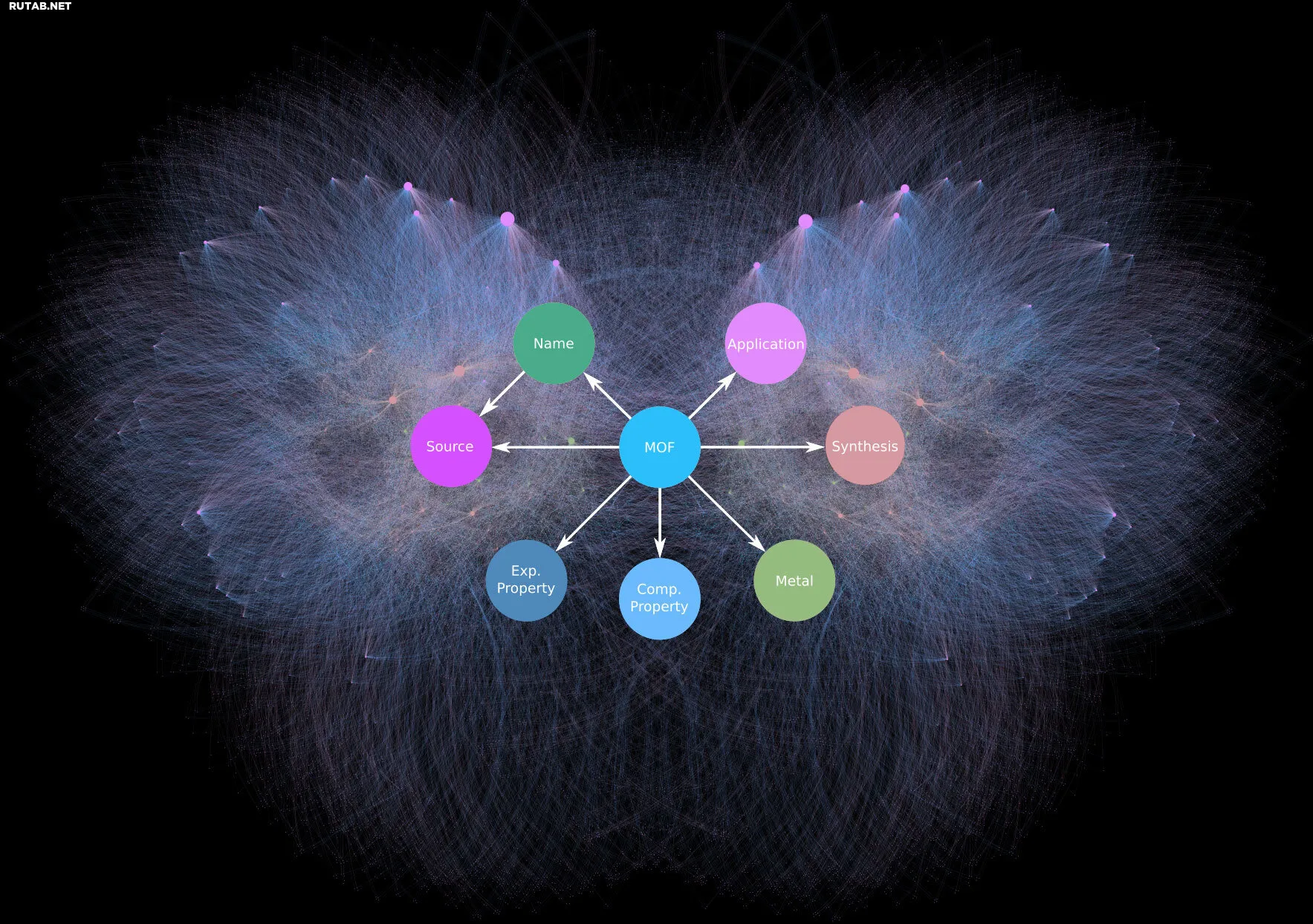
Граф знаний MOF-ChemUnity содержит около 0,5 миллиона точек данных и связей для более чем 15 000 металло-органических каркасов. На переднем плане показаны примеры типов информации, с которой может быть связан каждый материал, включая свойства, применение, методы синтеза и другое. Автор: Томас Пруин
Металлоорганические каркасы отличаются сверхвысокой площадью поверхности (до 7000 м²/г) и точно настраиваемой химией. Это позволяет использовать их в качестве молекулярных сит для захвата CO₂, детекторов молекул, катализаторов и систем доставки лекарств.
Растущая важность MOF-материалов подтверждается тем, что они стали темой Нобелевской премии по химии 2025 года. Однако с ускорением исследований в более чем 25 областях применения отслеживание быстро растущего объема знаний становится все более сложной задачей.
Команда профессора Мохамада Мусави разработала систему, использующую граф знаний для систематического извлечения и связывания информации из научных статей, репозиториев кристаллических структур и вычислительных баз данных.

Слева направо: профессор Мохамад Мусави, Томас Майкл Пруин и Амро Асвад — часть команды, создавшей MOF-ChemUnity. Фото: Тайлер Ирвинг / Университет Торонто
«Граф знаний соединяет фрагменты информации подобно паутине, связывая такие вещи, как MOF, его металлический узел, протокол синтеза и адсорбционные свойства через их отношения», — объясняет Мусави.
Система также была интегрирована с большими языковыми моделями для создания литературно-информированного ИИ-ассистента. В слепых оценках эксперты оценили ответы ассистента как более точные и надежные по сравнению с базовыми LLM, такими как GPT-4o.
«Этот подход снижает галлюцинации, что является одним из основных препятствий в применении больших языковых моделей в научных областях», — говорит Мусави.
Команда сделала набор данных и код открытыми на GitHub, чтобы поддержать прогресс в материаловедении и исследованиях с использованием ИИ.



0 комментариев