Ученые все чаще используют ChatGPT для написания научных статей, особенно в компьютерных науках
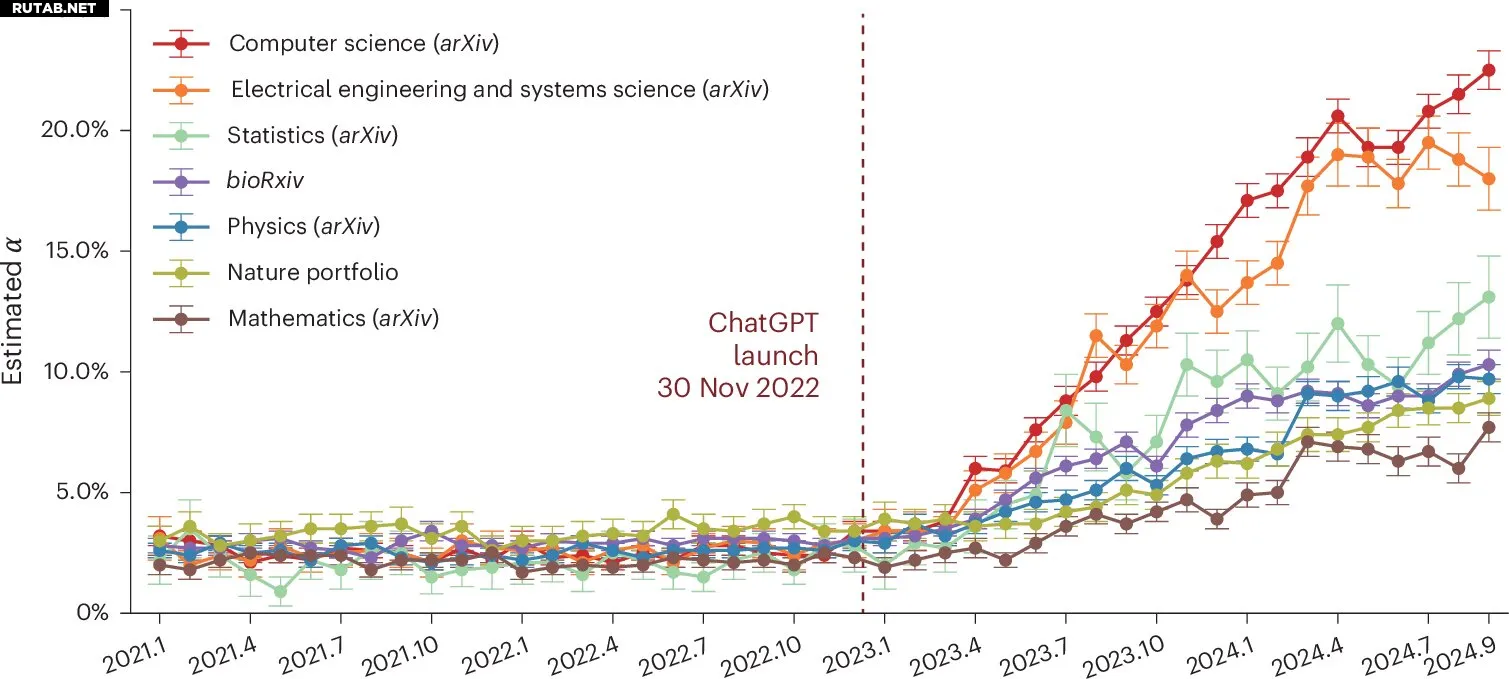
Оценочная доля предложений, измененных ИИ, в научных статьях по разным дисциплинам с течением времени. Источник: Nature Human Behaviour (2025). DOI: 10.1038/s41562-025-02273-8
С момента своего появления в ноябре 2022 года ChatGPT и другие большие языковые модели (LLM) стали активно использоваться в самых разных сферах — от написания речей до составления контрактов. Неудивительно, что ученые тоже начали применять эти инструменты для ускорения публикации своих исследований.
Пока мало известно о том, как использование ИИ-генерации влияет на разнообразие, качество и достоверность научных работ. Кроме того, из-за новизны и постоянного развития этих технологий надежных методов обнаружения LLM-контента пока не существует, а многие институты только разрабатывают политики по ограничению их применения.
Чтобы лучше понять масштабы использования ChatGPT в научных публикациях, группа исследователей проанализировала 1 121 912 статей и препринтов из arXiv, bioRxiv и журналов Nature. Исследование, опубликованное в Nature Human Behaviour, использовало новый метод анализа частоты слов для оценки роста LLM-контента с января 2020 по сентябрь 2024 года.
Результаты показали, что чаще всего ИИ используется в аннотациях и введениях, тогда как разделы с методами и экспериментами остаются менее затронутыми — вероятно, из-за ограниченных возможностей LLM по обработке технических данных. Наибольший рост применения ChatGPT зафиксирован в компьютерных науках — дисциплине, тесно связанной с ИИ.
К сентябрю 2024 года доля статей по компьютерным наукам с вероятным использованием LLM составила 22,5% для аннотаций и 19,5% для введений. Для сравнения, в ноябре 2022 года эти показатели не превышали 2,4%. Высокие темпы роста также отмечены в электротехнике и системных науках (18,0% и 18,4% соответственно).
В то же время в таких областях, как математика, применение ИИ оставалось относительно низким — 7,7% для аннотаций и 4,1% для введений. В журналах Nature рост был еще скромнее — 8,9% и 9,4% соответственно.
Исследование также выявило корреляцию между частотой публикации препринтов, объемом статей и географическим регионом. Авторы, публикующие препринты чаще, чаще используют LLM — возможно, из-за давления необходимости быстрого выпуска публикаций. Более короткие статьи (менее 5000 слов) и работы в конкурентных областях, таких как компьютерные науки, также чаще содержали следы ИИ.
Обнаружение ИИ-текста в неанглоязычных регионах сложнее, и предыдущие методы критиковали за предвзятость против авторов, для которых английский не является родным. Данное исследование показало более активное использование LLM в статьях из Китая и континентальной Европы по сравнению с Северной Америкой и Великобританией, но во многом это связано с помощью в написании на английском.
Авторы исследования подчеркивают важность дальнейшего изучения влияния ИИ на научную коммуникацию: «Наши наблюдения поднимают множество вопросов. Как такие статьи соотносятся по точности, креативности или разнообразию? Как читатели воспринимают LLM-генерацию? Как цитирование таких работ отличается от традиционных? Как доминирование коммерческих компаний в сфере LLM повлияет на независимость науки?»
«Мы надеемся, что наши результаты и методология вдохновят дальнейшие исследования и дискуссии о том, как обеспечить прозрачность, разнообразие и качество научных публикаций», — заключают авторы.
Дополнительная информация: Weixin Liang et al, Quantifying large language model usage in scientific papers, Nature Human Behaviour (2025). DOI: 10.1038/s41562-025-02273-8

0 комментариев