NVIDIA представила новый LPU с 500 МБ кэша и в 7 раз большей пропускной способностью, чем у HBM4
Семейство специализированных процессоров пополнилось новым участником. NVIDIA анонсировала создание нового чипа — LPU (Language Processing Unit), или языкового процессора.
Это специализированный чип для ускорения AI-инференса, разработанный на основе технологий компании Groq, которую NVIDIA приобрела в прошлом году. LPU сфокусирован на низкоуровневом декодировании и интерактивном выводе, дополняя GPU, которые в основном предназначены для обучения и общих вычислений. Вместе они поддерживают полный цикл работы с искусственным интеллектом — от обучения до развёртывания.
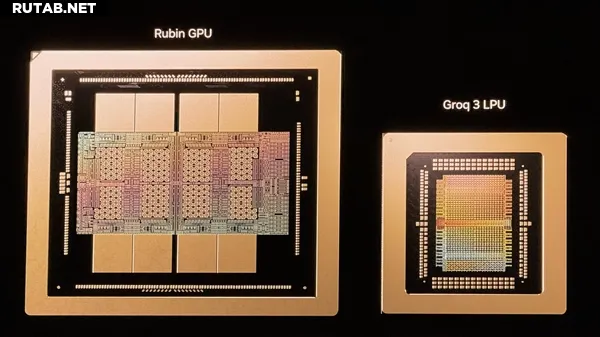

Новый чип Groq 3 LPU содержит 98 миллиардов транзисторов. Его ключевая особенность — огромный объём встроенной SRAM-памяти (статической оперативной памяти) размером 500 МБ, которая используется как кэш.
Хотя по ёмкости 500 МБ сильно уступают 288 ГБ памяти HBM4, пропускная способность LPU составляет колоссальные 150 ТБ/с. Это более чем в 7 раз выше, чем у HBM4 с её 22 ТБ/с.
Поскольку операции декодирования в AI чрезвычайно требовательны к пропускной способности памяти, Groq 3 идеально подходит для таких задач, обеспечивая при этом гораздо меньшую задержку. Вычислительная производительность чипа в точности FP8 достигает 1.2 PFLOPS (1.2 квадриллиона операций в секунду).

На основе этого чипа NVIDIA создала серверную стойку Groq 3 LPX, которая объединяет 256 чипов Groq 3 LPU. Суммарный объём SRAM-кэша в такой стойке достигает 128 ГБ, а совокупная пропускная способность — ошеломляющих 40 ПБ/с.
Стойки соединяются между собой с помощью специального интерфейса с пропускной способностью 640 ТБ/с. Общая производительность системы для AI-инференса составляет 315 PFLOPS (315 квадриллионов операций в секунду).
Groq LPX позиционируется как сопроцессор для платформы Rubin Vera. Он предназначен для ускорения обработки каждого токена в каждом слое AI-модели, что повышает производительность декодирования. Система также готова к работе с мультиагентными системами, которые считаются следующим рубежом в развитии ИИ и требуют выполнения вывода на триллионных моделях с контекстом в миллионы токенов при сохранении интерактивности.
Совместное использование GPU Rubin и LPU Groq позволит увеличить текущую пропускную способность генерации текста примерно со 100 токенов в секунду до 1500 токенов в секунду и более, что идеально подходит для сценариев взаимодействия с AI-агентами.

0 комментариев