NVIDIA планирует использовать 3D-стэкинг в архитектуре Feynman с LPU для ускорения AI-инференса
Хотя NVIDIA в настоящее время доминирует в области обучения искусственного интеллекта, компания готовит «секретное оружие» для удовлетворения растущего спроса на мгновенный инференс (AI-вывод).
Согласно данным AGF, NVIDIA планирует в архитектуре Feynman (Фейнман), выход которой ожидается в 2028 году, интегрировать LPU (языковой процессорный блок) от компании Groq, чтобы значительно повысить производительность AI-инференса.
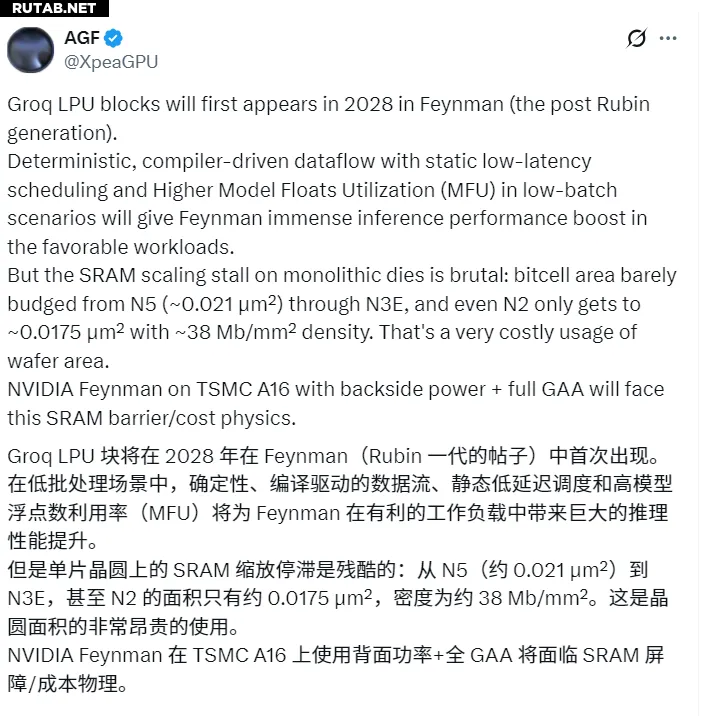
Архитектура Feynman придет на смену Rubin и будет производиться по самому передовому техпроцессу TSMC A16 (1.6 нм). Чтобы преодолеть физические ограничения полупроводников, NVIDIA планирует использовать технологию гибридной сборки SoIC от TSMC для вертикального стэкинга (укладки) специализированного блока LPU прямо поверх GPU.
Эта концепция похожа на технологию 3D V-Cache от AMD, но NVIDIA будет накладывать не обычный кэш, а специальный блок для ускорения инференса.
Ключевая логика такого дизайна — решение проблемы масштабирования SRAM. На уровне 1.6 нм интеграция большого объема SRAM непосредственно в основной кристалл становится чрезвычайно дорогой и занимает много места. С помощью стэкинга NVIDIA может оставить вычислительные ядра на основном чипе, а требующий большой площади SRAM выделить в отдельный слой.
Одной из особенностей техпроцесса A16 от TSMC является поддержка технологии питания с обратной стороны (BSPDN). Она освобождает место на лицевой стороне чипа, которое можно выделить под вертикальные соединения, обеспечивая высокоскоростной обмен данными между слоями с минимальным энергопотреблением.
В сочетании с «детерминированной» логикой выполнения LPU, будущие GPU NVIDIA смогут обеспечить качественный скачок в скорости обработки задач с мгновенным AI-откликом, таких как голосовые диалоги или перевод в реальном времени.
Однако существуют и два потенциальных вызова: проблемы с отводом тепла и совместимостью с CUDA. Добавление дополнительного слоя чипа поверх и без того плотного GPU создает серьезные инженерные трудности для предотвращения перегрева. Кроме того, LPU, требующий точного управления памятью и детерминированного порядка выполнения, должен будет безупречно работать в экосистеме CUDA, построенной на аппаратной абстракции, что потребует высочайшего уровня программной оптимизации.

Архитектура Feynman станет частью долгосрочной стратегии NVIDIA по созданию специализированных решений для разных этапов работы с ИИ. Ранее компания Groq, чью технологию LPU планирует использовать NVIDIA, привлекла внимание благодаря своим чипам, демонстрирующим рекордную скорость обработки языковых моделей, что делает такое партнерство логичным шагом.
0 комментариев