Команда из Нанкайского университета разработала прорывную систему для обнаружения текста, созданного ИИ
Исследовательская группа Нанкайского университета в Тяньцзине совершила значительный прорыв в обнаружении текста, сгенерированного искусственным интеллектом, разработав систему, которая значительно сокращает количество ложных срабатываний и пропусков — проблему, преследовавшую многие существующие инструменты.
Исследовательская работа команды о системе была принята на ACM Multimedia 2025, одну из ведущих мировых конференций по компьютерным наукам. Их функция обнаружения теперь интегрирована в Paper-Mate, помощника для исследований на основе ИИ, разработанного профессорами Нанкайского университета Ли Чжунъи и Го Чуньлэ, и доступна бесплатно.
По словам члена команды Фу Цзячэня, система насчитывает более 1000 активных пользователей в месяц, включая преподавателей и студентов из нескольких университетов, таких как Пекинский университет, Чжэцзянский университет и Университет Сунь Ятсена.
«Многие пользователи предоставили обратную связь, указывая, что PaperMate превосходит аналогичные инструменты на рынке с точки зрения ложных срабатываний и пропусков, предлагая более точные и надежные результаты обнаружения», — сказал Фу.
«Текущие инструменты обнаружения ИИ для академических работ часто ложно обвиняют авторов. Например, мой старший коллега, работая над своей диссертацией, использовал существующие инструменты обнаружения ИИ и обнаружил, что часть его оригинального контента была ошибочно помечена как сгенерированная ИИ», — добавил он.
Объясняя причины ошибочных идентификаций текущими методами обнаружения текста ИИ, Фу сказал:
«Если мы уподобим обнаружение текста ИИ экзамену, то обучающие данные детектора подобны повседневным тренировочным вопросам. Существующие методы обнаружения склонны механически запоминать фиксированные шаблоны ответов, и их точность значительно падает при столкновении с совершенно новыми проблемами.
В теории для достижения универсального обнаружения нам потребовалось бы обучаться на данных всех основных моделей, что практически невозможно, учитывая быструю итерацию этих моделей сегодня».
Повышение способности обнаружения к обобщению и возможность применения детектором принципов в различных сценариях крайне важно для улучшения производительности обнаружения текста ИИ.
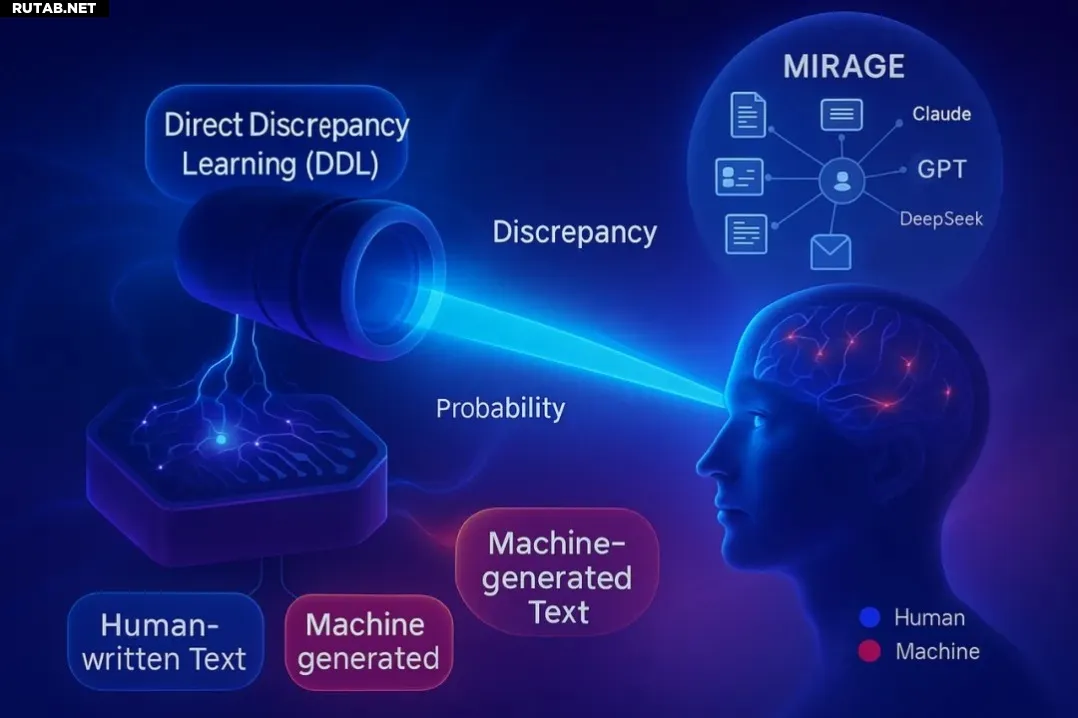
Лаборатория медиавычислений Школы компьютерных наук Нанкайского университета не только выявила ограничения производительности существующих методов обнаружения ИИ с оценочной точки зрения, но и предложила стратегию оптимизации «Прямое обучение расхождению».
Эта стратегия учит ИИ различать текст, написанный человеком и сгенерированный машиной, достигая значительного прорыва в производительности обнаружения.
«По сути, мы повышаем точность алгоритма обнаружения, чтобы снизить уровень ложных срабатываний», — пояснил Фу.
Он также представил MIRAGE, эталонный набор данных команды.
«Мы собрали тексты, написанные людьми, а затем поручили большим моделям ИИ доработать эти тексты, получив набор оригинальных человеческих текстов и текстов, сгенерированных ИИ. Применяя как существующие алгоритмы, так и наш алгоритм к этим текстам, MIRAGE записывает точность обнаружения», — объяснил он.
Результаты тестирования набора данных показывают, что точность существующих детекторов упала с 90% до примерно 60%, в то время как детекторы, обученные с помощью Прямого обучения расхождению, сохранили точность более 85%. По сравнению с DetectGPT Стэнфордского университета, производительность улучшилась более чем на 70%, сообщил он.
Ли Чжунъи, возглавляющий Лабораторию медиавычислений Школы компьютерных наук Нанкайского университета, заявил, что результаты исследования выявляют фундаментальные недостатки многих современных систем обнаружения и предлагают практический путь вперед.
«Поскольку контент, генерируемый ИИ, развивается так быстро, мы будем продолжать итеративно улучшать нашу технологию и эталонные показатели, чтобы добиться более быстрого, точного и экономически эффективного обнаружения, — сказал Ли. — Наша цель — использовать сам ИИ, чтобы каждая работа сияла».
Лю Тиньюй внесла вклад в эту статью.
ИИ: Разработка эффективных инструментов для различения человеческого и ИИ-генерированного текста становится всё более критичной в эпоху повсеместного использования больших языковых моделей. Подход команды из Нанкайского университета, фокусирующийся на обобщении и снижении ложных срабатываний, выглядит многообещающе для академической и других сфер, где важна аутентичность авторства.
0 комментариев