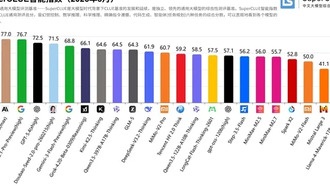
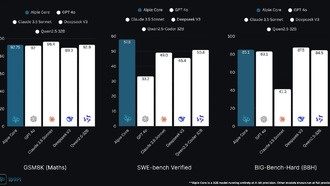
Опубликованы результаты ежемесячного эталонного тестирования китайских больших языковых моделей SuperCLUE за март 2026 года. В соревновании приняли участие 22 ведущие модели со всего мира.Модель Doubao-Seed-2.0-pro-260215(high) от ByteDance набрала 71.53 балла, заняв первое место среди китайских
Читать дальше →
В сети появилась информация о новой крупной языковой модели, что вызвало оживлённые обсуждения. Ранее ходили слухи о скором выходе самой ожидаемой на внутреннем рынке модели DeepSeek V4, но этого не произошло.Новая модель снова была замечена на платформе OpenRuter. Было представлено два алгоритма.
Читать дальше →
На прошлой неделе ходили слухи о выпуске крупной языковой модели DeepSeek V4, но этого не произошло. Вместо этого компания DeepSeek опубликовала на своём официальном сайте облегчённую версию, которую пользователи сети окрестили DeepSeek V4 Lite.Согласно данным, DeepSeek V4 Lite имеет 200 миллиардов
Читать дальше →
Хотя в период китайского Нового года полноценная модель DeepSeek V4 не была представлена, компания DeepSeek 11 февраля выпустила новую версию под названием DeepSeek V4 Lite. Её особенностью является относительно небольшой размер — всего 200 миллиардов параметров.Основной особенностью DeepSeek V4
Читать дальше →
Китайская компания DeepSeek официально подтвердила тестирование новой архитектуры языковой модели с увеличенной длиной контекста. Как сообщается, веб-версия и мобильное приложение сервиса получили обновление, которое позволяет модели обрабатывать до 1 миллиона символов контекста.Это представляет
Читать дальше →
В сети с нетерпением ждали выпуска новой крупной языковой модели DeepSeek V4, однако компания представила не мажорное обновление, а существенно улучшенную версию текущей модели.Согласно официальной информации, ключевым нововведением стало значительное увеличение длины контекста — теперь модель
Читать дальше →
Пока западный технологический мир следит за обновлениями от OpenAI и Anthropic, на Востоке состоялся релиз, который может перевернуть рынок с ног на голову. Группа Alibaba официально представила свою новейшую языковую модель Qwen-3.5.Это не просто очередная итерация успешной серии, а мощный удар по
Читать дальше →
Сегодня организация SuperCLUE опубликовала ежегодный отчёт за 2025 год о бенчмарке больших языковых моделей для китайского языка.В оценке приняли участие 23 модели из Китая и других стран, которые были протестированы по шести ключевым направлениям: математические рассуждения, научные рассуждения,
Читать дальше →
В то время как лидерами в области ИИ-технологий остаются США и Китай, другие страны стремятся занять свою нишу в этой технологической гонке. Недавно индийская компания 169PI представила языковую модель Alpie, которую уже окрестили «индийской версией DeepSeek».Модель с открытым исходным кодом
Читать дальше →
В Лхасе, столице Тибетского автономного района на юго-западе Китая, в среду была представлена первая в стране большая языковая модель на тибетском языке SunshineGLM V1.0 с сотнями миллиардов параметров.На мероприятии запуска в Тибетском университете Ньима Таши, главный научный сотрудник
Читать дальше →
Многие из нас испытывали смутное подозрение, что читаемый текст был написан большой языковой моделью, но доказать это оказывается на удивление сложно. В прошлом году все вдруг стали убеждены, что такие слова, как «углубляться» или «подчеркивать», выдают модели, но доказательства сомнительны, а с
Читать дальше →
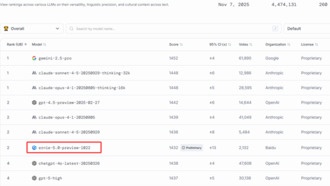
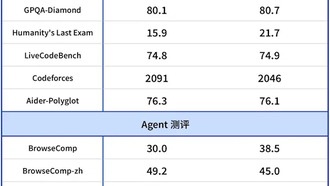
Сегодня в обновленном рейтинге LMArena, крупнейшей площадки для тестирования языковых моделей, новая модель ERNIE 5.0-Preview-1022 от Baidu заняла второе место в мировом рейтинге текстовых возможностей и первое — в Китае.Модель продемонстрировала выдающиеся результаты в креативном письме,
Читать дальше →
Компания DeepSeek сегодня объявила о выпуске обновленной версии своей языковой модели — DeepSeek V3.1 Terminus.В настоящее время обновление уже доступно в официальном приложении, веб-версии, мини-программах и через API DeepSeek.Это обновление сохраняет все возможности предыдущей версии, но
Читать дальше →
Китайская компания Baidu официально представила новую версию своей языковой модели Ernie X1.1 (文心大模型X1.1) на конференции WAVE SUMMIT 2025, посвященной разработчикам в области глубокого обучения.Как сообщил представитель компании Ван Хайфэн, модель Ernie X1.1 основана на Ernie 4.5 и использует
Читать дальше →
Китайская компания DeepSeek, специализирующаяся на искусственном интеллекте, представила версию 3.1 своей флагманской языковой модели. Обновление увеличило окно контекста до 128 000 токенов, а количество параметров достигло 685 миллиардов. О релизе компания сообщила 19 августа через группу в WeChat,
Читать дальше →
Согласно внутренним тестам OpenAI, новые версии ChatGPT стали чаще «галлюцинировать» — выдавать ложную информацию. Проблема усугубляется, и причины этого пока неясны.Исследование показало, что модель GPT o3 (самая мощная на данный момент) ошибалась в 33% случаев при ответах на вопросы о публичных
Читать дальше →