DeepSeek V4 Lite: компактная модель с 200 млрд параметров догоняет лидеров
Хотя в период китайского Нового года полноценная модель DeepSeek V4 не была представлена, компания DeepSeek 11 февраля выпустила новую версию под названием DeepSeek V4 Lite. Её особенностью является относительно небольшой размер — всего 200 миллиардов параметров.
Основной особенностью DeepSeek V4 Lite изначально была поддержка контекста длиной в 1 млн токенов. Первые тесты пользователей показали, что, за исключением работы с очень длинными текстами, модель не демонстрировала выдающихся результатов, что объяснялось её скромным по современным меркам размером.
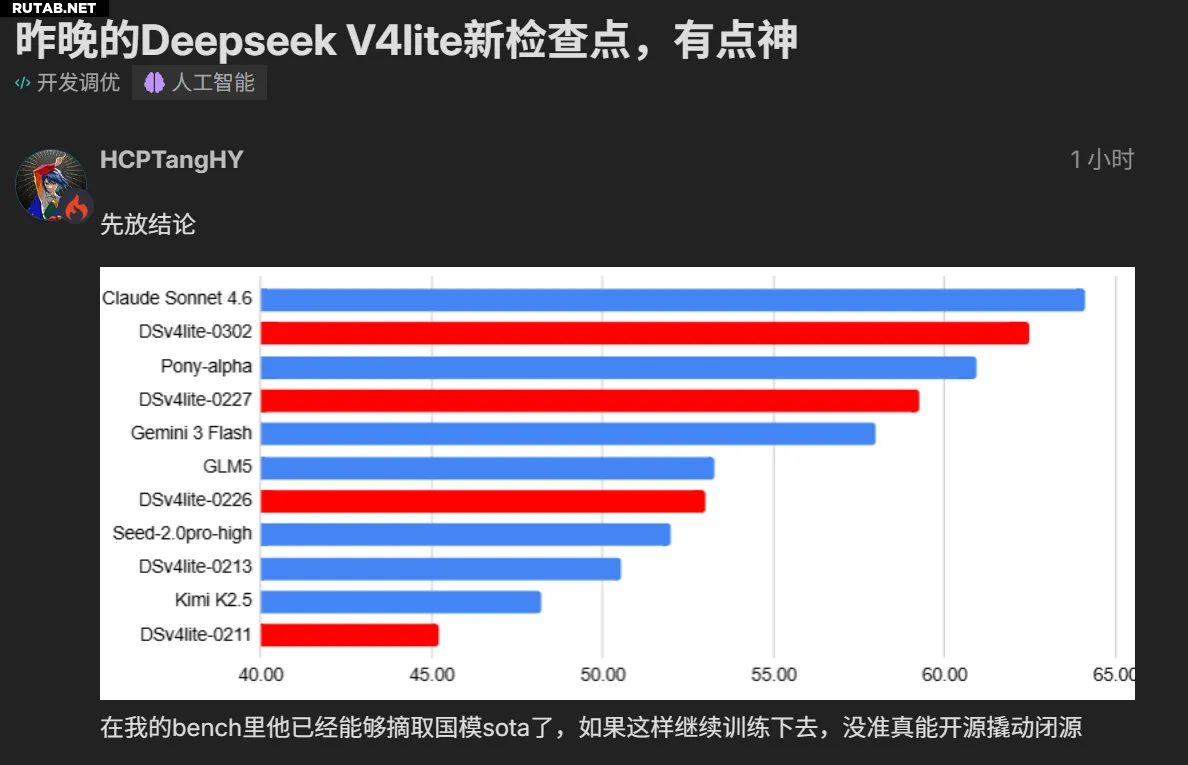
Однако после релиза модель начала «тихо» обновляться. Уже 27 февраля пользователи заметили значительный рост её производительности. Вчерашнее обновление, протестированное пользователем HCPTangHY в сообществе Linux Do, вызвало удивление. Тестировщик назвал модель «почти волшебной», отметив, что в его тестах она уже показывает лучшие в стране результаты (SOTA).
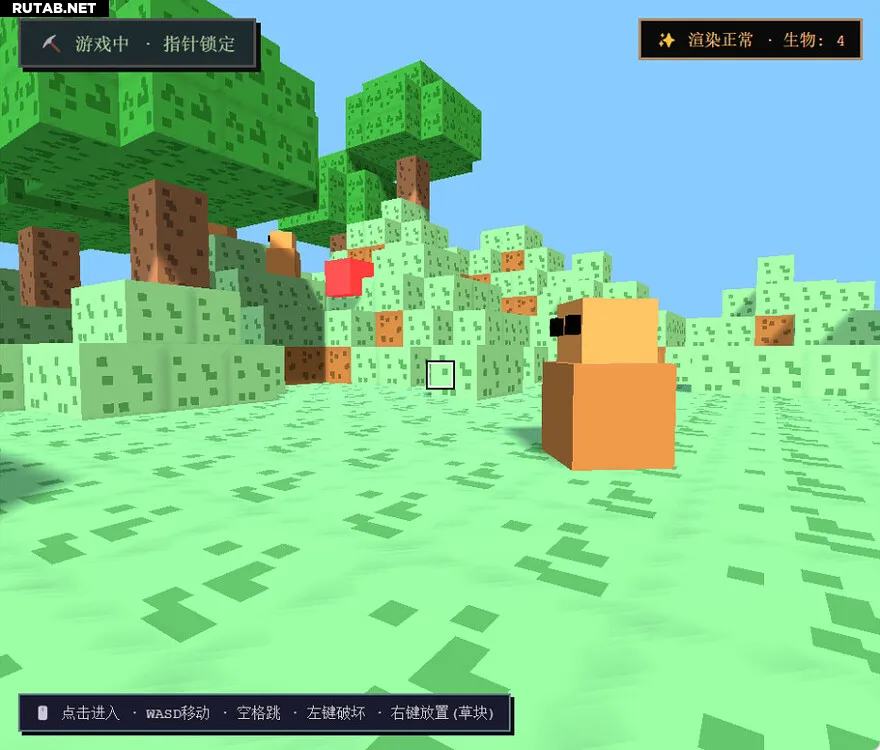
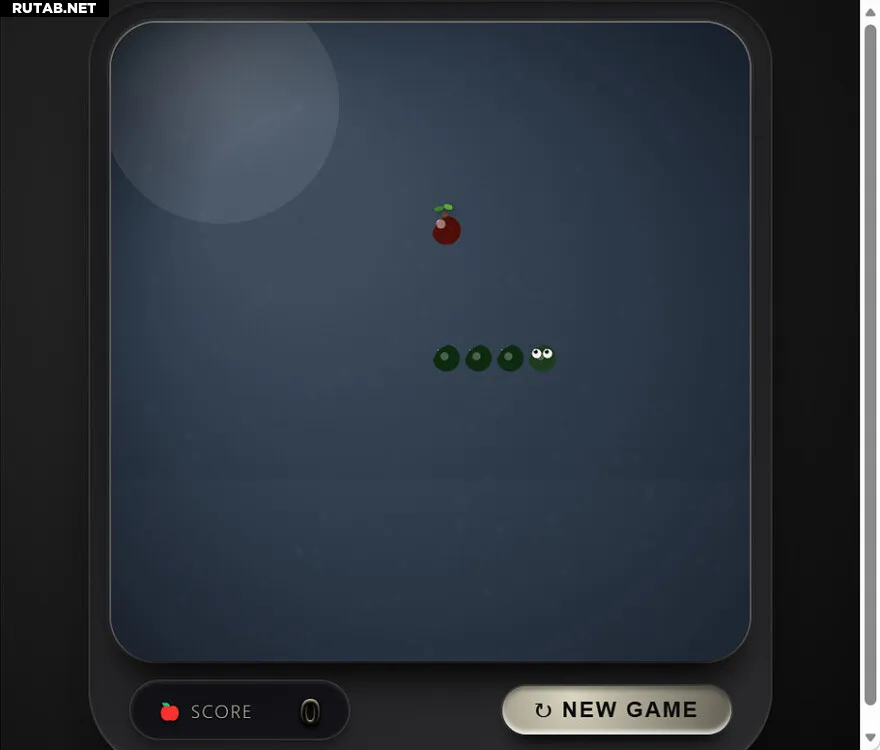
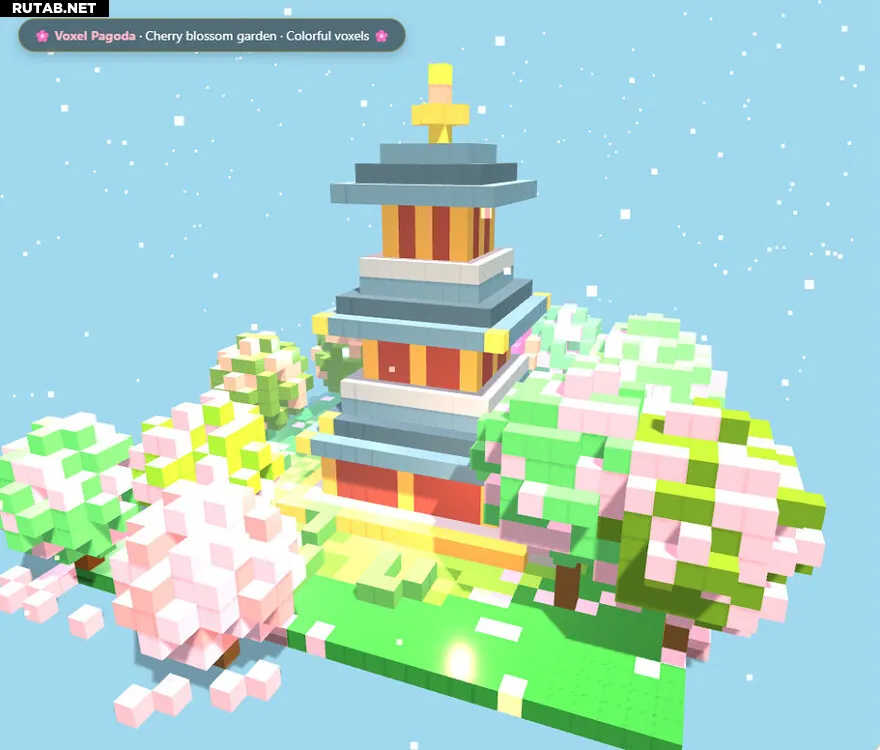
Согласно тестам, версия DeepSeek V4 Lite от 2 марта набрала более высокие баллы, чем версия от 27 февраля, и вплотную приблизилась к производительности одного из ведущих мировых моделей — Sonnet 4.6. Модель также хорошо проявила себя в других тестах, включая популярный «тест погодной карточки», продемонстрировав хороший вкус и функциональность.

Анализируя развитие больших языковых моделей за последний год, можно отметить, что китайские модели в области диалогов уже почти не уступают закрытым аналогам. Однако разрыв сохраняется в таких областях, как мультимодальность, программирование, математика и создание AI-агентов. Недавние релизы, такие как GLM5, MiniMax 2.5 и серия Qwen 3.5, сократили отставание, но выпуск новых моделей от Anthropic, OpenAI и Google вновь увеличил дистанцию.
Китайские компании в гонке за лидерами сталкиваются с рядом трудностей: меньшие инвестиции, нехватка вычислительных мощностей и менее обширные данные по сравнению с такими гигантами, как Google и OpenAI, которые обладают многолетними наработками и огромной пользовательской базой. Для иллюстрации масштаба усилий приводится пример: компания Anthropic, как сообщалось, для сбора данных скачивала книги с пиратских сайтов и была приговорена к выплате 15 миллиардов долларов в качестве компенсации.
DeepSeek уже зарекомендовала себя как технологический лидер. Если компактная модель с 200 миллиардами параметров показывает такие впечатляющие результаты, то полноценный DeepSeek V4, выход которого ожидается, может оказать серьёзное влияние на мировой рынок искусственного интеллекта.
Интересный факт: Термин SOTA (State-of-the-Art) в машинном обучении означает модель, которая в данный момент показывает наилучшие результаты по конкретному набору тестов или задач. Достижение статуса SOTA даже в рамках одной страны является значимым технологическим прорывом, особенно для модели с относительно небольшим количеством параметров, что делает её более эффективной и доступной для развёртывания.
0 комментариев