Рейтинг больших языковых моделей для китайского языка: лидируют зарубежные, но китайские показывают хорошие результаты
Сегодня организация SuperCLUE опубликовала ежегодный отчёт за 2025 год о бенчмарке больших языковых моделей для китайского языка.
В оценке приняли участие 23 модели из Китая и других стран, которые были протестированы по шести ключевым направлениям: математические рассуждения, научные рассуждения, генерация кода и другим.
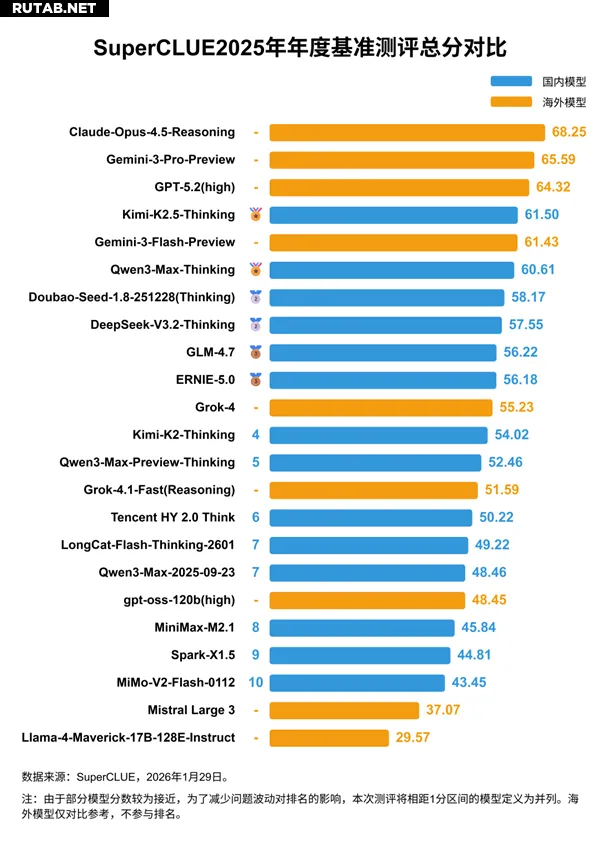
Результаты показывают, что лидирующие позиции по-прежнему занимают зарубежные проприетарные модели. Модель Claude-Opus-4.5-Reasoning от компании Anthropic набрала 68.25 баллов и заняла первое место.
За ней следуют Gemini-3-Pro-Preview от Google с 65.59 баллами и GPT-5.2(high) от OpenAI с 64.32 баллами, замкнув тройку лидеров.
Однако китайские модели активно сокращают отставание. Лучшая китайская открытая модель Kimi-K2.5-Thinking и лучшая проприетарная модель Qwen3-Max-Thinking (千问3-Max-Thinking) набрали 61.50 и 60.61 баллов, заняв четвёртое и шестое места в мировом рейтинге соответственно.
В некоторых узких задачах китайские модели показали выдающиеся результаты. Например, Kimi-K2.5-Thinking заняла первое место в задаче генерации кода с 53.33 баллами, а Qwen3-Max-Thinking в задаче математических рассуждений набрала 80.87 баллов, разделив первое место с моделью Gemini-3-Pro-Preview от Google.
В целом, наблюдается значительная разница между открытыми и проприетарными моделями внутри Китая и за его пределами. В проприетарном сегменте лидируют зарубежные разработки, а китайские модели их догоняют. В открытом сегменте, наоборот, доминируют китайские модели, в то время как зарубежные отстают: пять лучших китайских открытых моделей существенно опережают зарубежные аналоги.
0 комментариев