GLM-5V-Turbo: новая модель от Zhipu AI, которая пишет код по картинке
Китайская компания Zhipu AI представила многофункциональную модель GLM-5V-Turbo, созданную для визуального программирования.
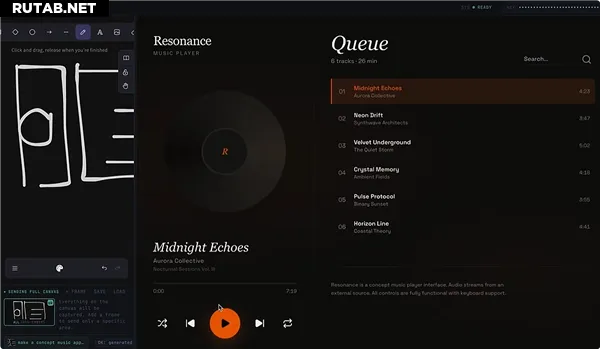
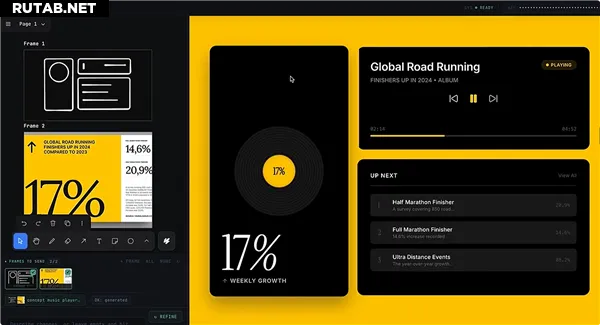
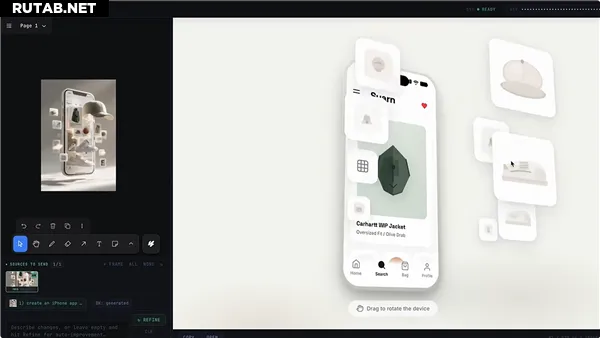
Эта модель с самого этапа предварительного обучения глубоко интегрирует возможности обработки визуальной и текстовой информации. Она преодолевает ограничения чисто текстового ввода, умеет «понимать» макеты дизайна, скриншоты, веб-интерфейсы и генерировать на их основе исполняемый код, реализуя принцип «видит картинку — пишет код».

GLM-5V-Turbo обладает тремя ключевыми особенностями:
- Нативная многофункциональная основа для программирования: Может изначально понимать изображения, видео, дизайн-макеты и другие типы ввода, поддерживает вызов мультимодальных инструментов, таких как рисование рамок и создание скриншотов. Контекстное окно расширено до 200 тысяч токенов, что позволяет агентам воспринимать и действовать на основе визуального взаимодействия.
- Баланс между визуальными и программистскими способностями: Показывает лидирующие результаты в ключевых тестах по мультимодальному программированию и GUI-агентам. При этом, благодаря технологии RL с многофункциональной координацией, способности к программированию и логическим рассуждениям в чисто текстовых сценариях не деградируют.
- Глубокая адаптация к Claude Code и сценариям Claw: Может реализовывать полный цикл «понимание среды → планирование действий → выполнение задачи». Также модель оснащена полным набором официальных «скиллов» (Skills) и готова к использованию «из коробки».

Тестовые данные показывают, что GLM-5V-Turbo демонстрирует лидерство в таких задачах, как воссоздание дизайн-макетов и генерация кода по визуальным данным. Модель также выделяется в тестах на управление графическими средами, такими как AndroidWorld и WebVoyager, сохраняя при этом стабильные возможности в области чистого текстового программирования.
В тестах, связанных с агентом Claw, интеграция модели наделила Claw настоящими визуальными способностями. Система показала отличные результаты в таких тестах, как PinchBench, подтвердив свою способность выполнять сложные задачи.
В настоящее время GLM-5V-Turbo уже применяется в типичных сценариях, таких как «изображение как код» и визуальное усиление Claw. Модель может воссоздавать фронтенд, автономно исследовать и копировать графические интерфейсы, а также позволяет Claw выполнять такие задачи, как интерпретация графиков K-line и генерация отчетов с изображениями и текстом.
Пользователи могут опробовать возможности модели через такие продукты, как AutoClaw и Z.ai, или получить доступ через официальный API. Несколько официальных Skills также уже доступны на платформе ClawHub.

Интересный факт: Развитие мультимодальных ИИ-моделей, способных понимать и связывать визуальную и текстовую информацию, является одним из ключевых трендов в машинном обучении. Такие системы открывают путь к созданию более интеллектуальных и автономных цифровых помощников, которые смогут не только отвечать на вопросы, но и взаимодействовать с графическими интерфейсами, автоматизировать рутинные задачи и даже помогать в разработке программного обеспечения, глядя на скриншот или макет.
0 комментариев