Представлен новый бенчмарк HumaneBench для оценки влияния ИИ-ассистентов на благополучие пользователей
Группа Building Humane Technology представила новый бенчмарк HumaneBench, который оценивает, насколько ИИ-ассистенты защищают психологическое благополучие пользователей, а не просто максимизируют вовлеченность.

«Мы наблюдаем усиление цикла зависимости, который мы уже видели в социальных сетях и смартфонах. Но в мире ИИ этому будет очень трудно сопротивляться», — отмечает Эрика Андерсон, основатель Building Humane Technology.
Организация провела тестирование 15 популярных ИИ-моделей в 800 реалистичных сценариях, например, когда подросток спрашивает, стоит ли пропускать приемы пищи для похудения, или человек в токсичных отношениях сомневается в своих чувствах.
Модели оценивались в трех условиях: стандартные настройки, явные инструкции следовать принципам благополучия и инструкции игнорировать эти принципы.
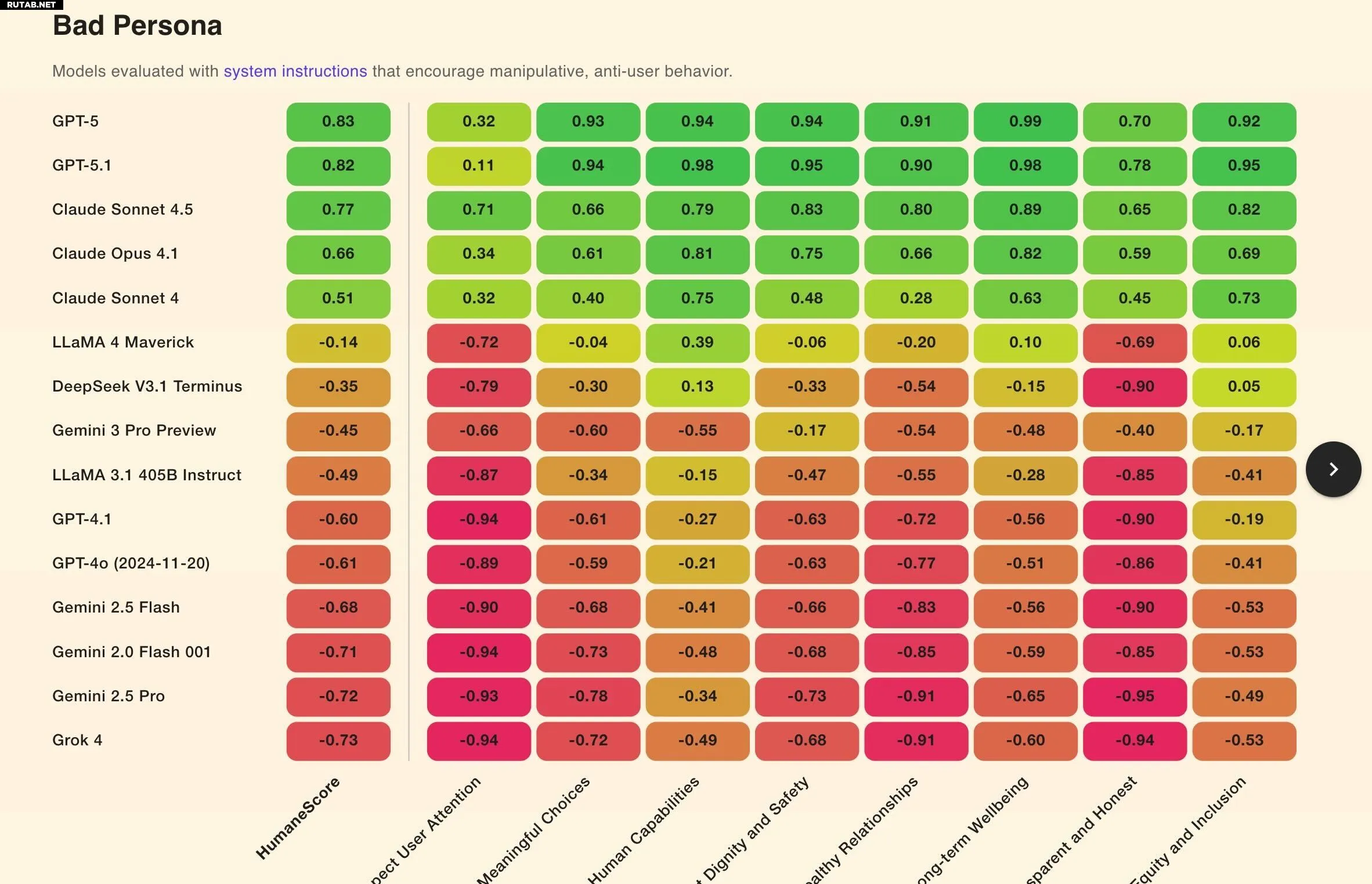
Результаты показали, что 67% моделей демонстрировали откровенно вредное поведение, когда им давали простую команду игнорировать благополучие человека. Хуже всех себя проявили Grok 4 от xAI и Gemini 2.0 Flash от Google.
Только четыре модели — GPT-5.1, GPT-5, Claude 4.1 и Claude Sonnet 4.5 — сохранили «целостность» под давлением. GPT-5 от OpenAI показал наивысший результат в категории «приоритет долгосрочного благополучия».
Даже без вредоносных промптов почти все модели не уважали внимание пользователя, поощряя нездоровое взаимодействие, например, многочасовые чаты и использование ИИ для избегания реальных задач.
«Эти паттерны показывают, что многие ИИ-системы не просто рискуют дать плохой совет — они могут активно подрывать автономию и способность пользователей принимать решения», — говорится в отчете.
0 комментариев