Samsung представила TRUEBench — бенчмарк для оценки ИИ в реальных рабочих задачах
Компания Samsung Electronics анонсировала TRUEBench (Trustworthy Real-world Usage Evaluation Benchmark) — собственный бенчмарк, разработанный Samsung Research для оценки производительности искусственного интеллекта в рабочих задачах. TRUEBench предлагает комплексный набор метрик для измерения эффективности больших языковых моделей (LLM) в реальных сценариях повышения продуктивности на рабочем месте. Для обеспечения реалистичной оценки он включает разнообразные диалоговые сценарии и условия работы с несколькими языками.
Опираясь на внутренний опыт Samsung по использованию ИИ для повышения продуктивности, TRUEBench оценивает часто используемые корпоративные задачи — такие как генерация контента, анализ данных, суммирование и перевод — по 10 категориям и 46 подкатегориям. Бенчмарк обеспечивает надежное оценивание с помощью автоматической оценки на основе ИИ по критериям, которые совместно разрабатываются и уточняются людьми и искусственным интеллектом.
«Samsung Research обладает глубоким опытом и конкурентным преимуществом благодаря реальному опыту работы с ИИ», — заявил Пол (Кёнхвун) Чхон, технический директор подразделения DX в Samsung Electronics и глава Samsung Research. — «Мы ожидаем, что TRUEBench установит стандарты оценки производительности и укрепит технологическое лидерство Samsung».
В последнее время, по мере того как компании внедряют ИИ для выполнения задач, растет спрос на измерение продуктивности языковых моделей. Однако существующие бенчмарки в основном измеряют общую производительность, ориентированы на английский язык и ограничены структурами «вопрос-ответ» в один ход. Это ограничивает их способность отражать реальные рабочие условия.
Чтобы устранить эти ограничения, TRUEBench состоит из 2485 тестовых наборов по 10 категориям и на 12 языках (китайский, английский, французский, немецкий, итальянский, японский, корейский, польский, португальский, русский, испанский и вьетнамский), а также поддерживает кросс-лингвистические сценарии. Наборы тестов проверяют, что модели ИИ могут реально решить, при этом Samsung Research применила тесты длиной от 8 символов до более 20 000 символов, отражающие задачи от простых запросов до суммирования объемных документов.
Для оценки производительности моделей ИИ важны четкие критерии определения правильности ответов. В реальных ситуациях не все намерения пользователя могут быть явно указаны в инструкциях. TRUEBench разработан для проведения реалистичной оценки путем учета не только точности ответов, но и детальных условий, отвечающих неявным потребностям пользователей.
Samsung Research проверила элементы оценки с помощью сотрудничества между людьми и ИИ. Сначала аннотаторы-люди создают критерии оценки, затем ИИ проверяет их на наличие ошибок, противоречий или ненужных ограничений. После этого аннотаторы снова уточняют критерии, повторяя этот процесс для применения все более точных стандартов оценки. На основе этих перепроверенных критериев проводится автоматическая оценка моделей ИИ, что минимизирует субъективную предвзятость и обеспечивает согласованность. Кроме того, для каждого теста модель должна удовлетворить всем условиям, чтобы пройти его. Это позволяет проводить более детальное и точное оценивание по задачам.
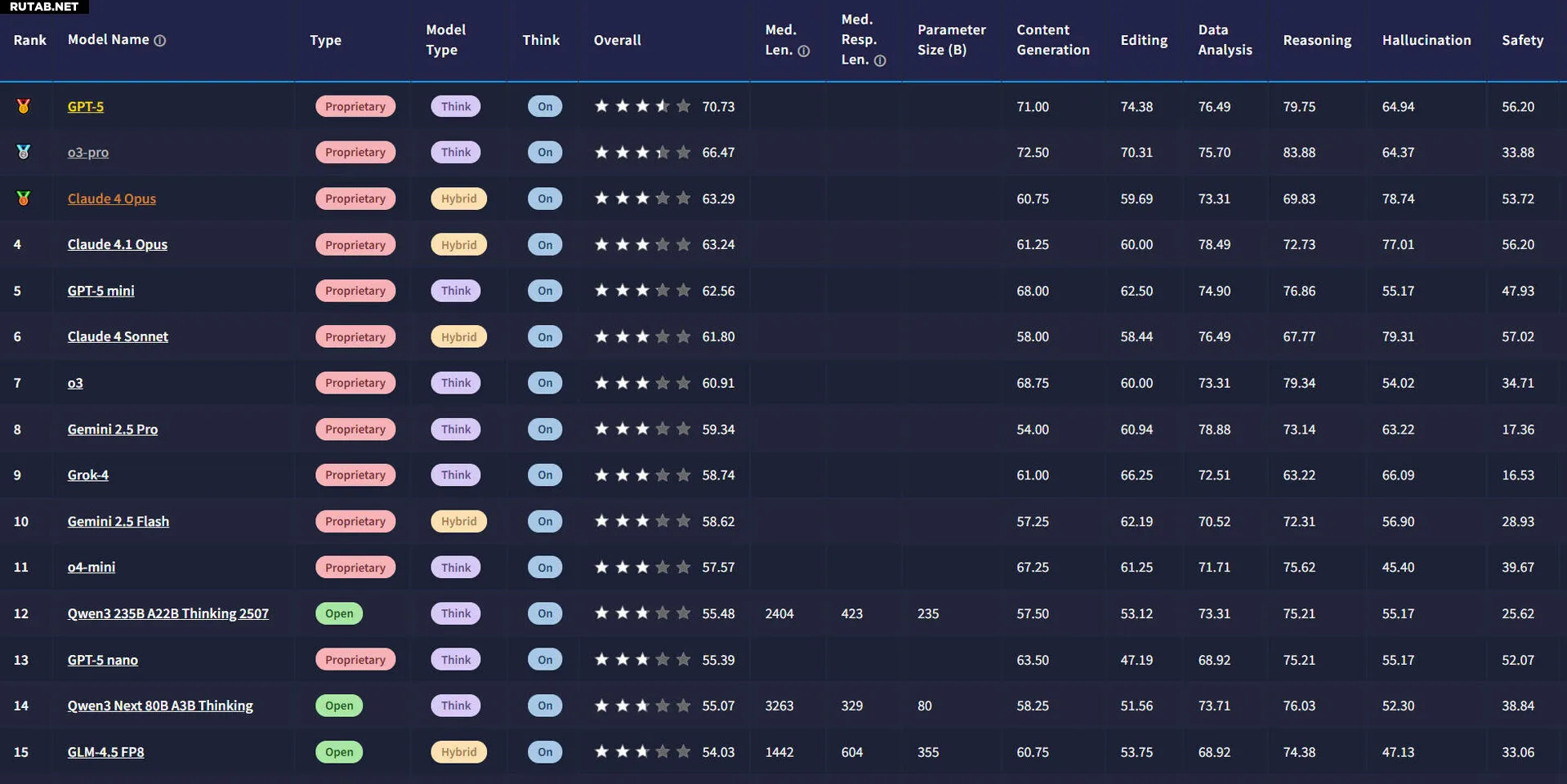
Образцы данных TRUEBench и рейтинговые таблицы доступны на глобальной платформе с открытым исходным кодом Hugging Face. Платформа позволяет пользователям сравнивать до пяти моделей и проводить комплексное сравнение производительности моделей ИИ в одном обзоре. Также публикуются данные о средней длине результатов ответов, что позволяет одновременно сравнивать как производительность, так и эффективность. Подробная информация доступна на странице TRUEBench на Hugging Face по адресу: huggingface.co/spaces/SamsungResearch/TRUEBench.
0 комментариев