Arm China представила новый NPU пятого поколения «Чжоу И» X3 с производительностью до 80 TFLOPS
Компания Arm China (安谋科技), ведущий поставщик IP-ядер и сервисов для чипов, провела в Шанхае презентацию, где официально представила новое поколение нейропроцессора «Чжоу И» X3 NPU (Zhouyi X3 NPU).
Это первый крупный продукт, выпущенный после объявления стратегии Arm China «All in AI», и он ориентирован на четыре ключевых направления: инфраструктуру, умные автомобили, мобильные устройства и интернет вещей (AIoT).
Новый NPU обеспечит эффективные вычисления искусственного интеллекта на стороне устройства для таких применений, как AI-акселераторы, интеллектуальные кокпиты, системы ADAS, роботы с воплощённым интеллектом, AI PC, смартфоны с ИИ, умные шлюзы и IP-камеры.

Помимо NPU «Чжоу И», в портфолио Arm China входят собственные разработки: CPU «Син Чэнь» (Xingchen), SPU «Шань Хай» (Shanhai) и мультимедийные процессоры «Лин Лун» (Linglong), которые в совокупности покрывают широкий спектр сценариев для AI-вычислений.
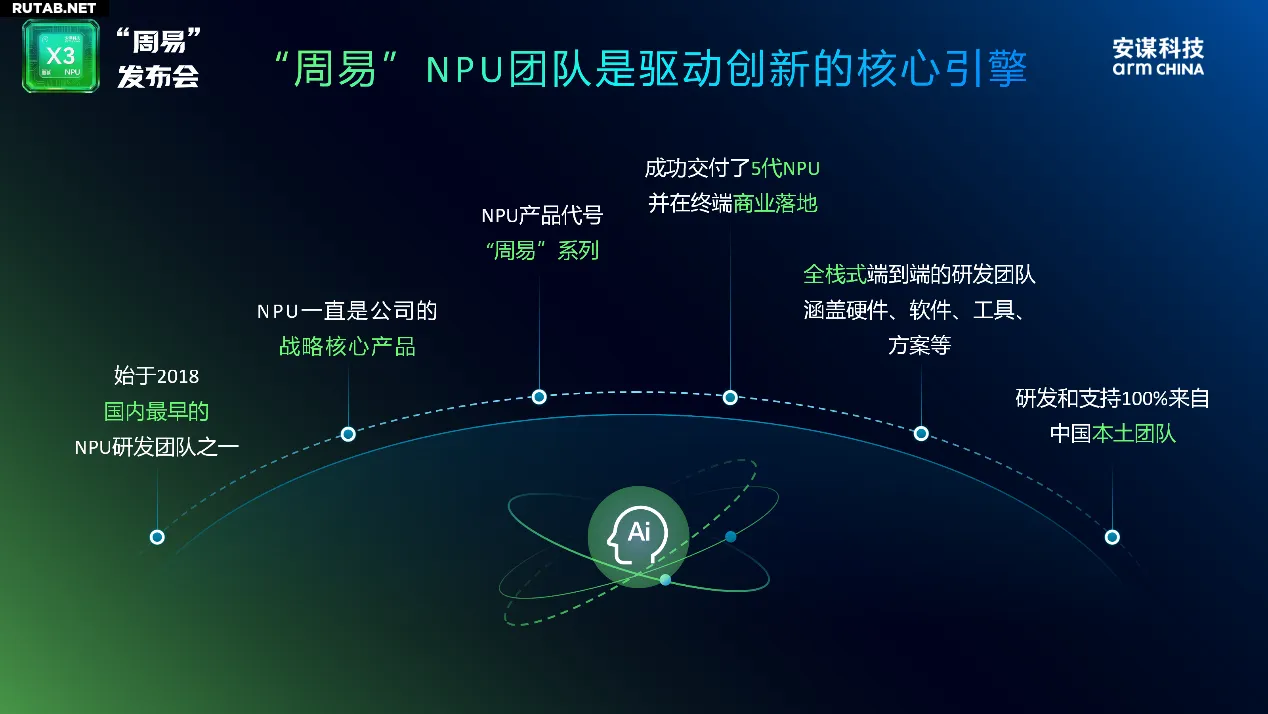
Команда «Чжоу И» NPU, одна из старейших в Китае в этой области, была создана в 2018 году и предлагает полный стек решений — от аппаратного обеспечения и ПО до инструментов, при этом вся разработка на 100% осуществляется локальной китайской командой.
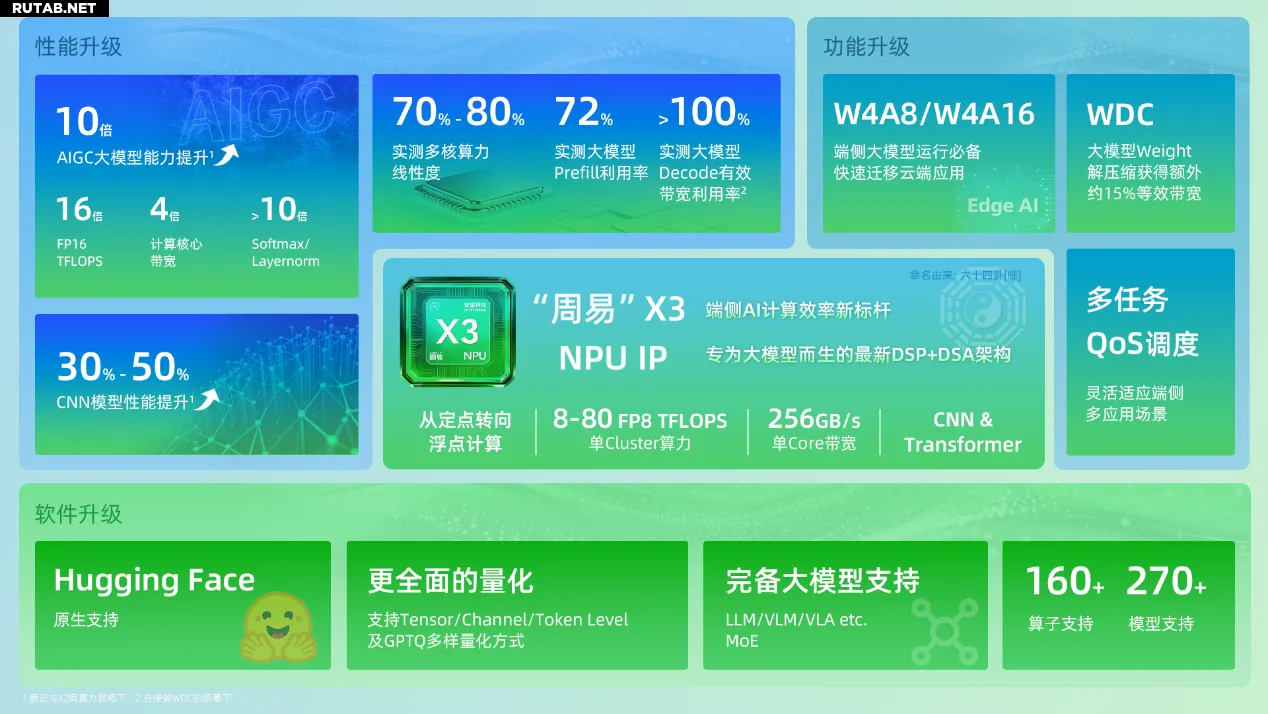
Архитектура «Чжоу И» X3 NPU основана на новой универсальной схеме DSP+DSA, созданной специально для больших моделей, и поддерживает как CNN, так и Transformer, эффективно решая проблему работы больших AI-моделей на устройстве.
Один кластер может содержать до 4 ядер, обеспечивая производительность в формате FP8 от 8 до 80 TFLOPS, при этом пропускная способность на одно ядро достигает 256 ГБ/с.
Архитектура X3 включает несколько ключевых инноваций:
— Интегрированный аппаратный декомпрессор WDC собственной разработки: после программного сжатия весов большых моделей без потерь аппаратная декомпрессия даёт прирост эффективной пропускной способности на 15-20%.
— Новые режимы вычислений W4A8/W4A8 для устройств: оба необходимы для работы больших моделей. Квантование весов модели с низкой битностью значительно снижает потребление пропускной способности и поддерживает эффективную миграцию облачных больших моделей на устройства.
— Интегрированный AI-движок AIFF (AI Fixed-Function) и специализированный планировщик: обеспечивают сверхнизкую (всего 0.5%) нагрузку на CPU и малую задержку планирования, гибко поддерживая многозадачные сценарии и сценарии с любым приоритетом, гарантируя мгновенный отклик для высокоприоритетных задач.
— Поддержка вычислений со смешанной точностью INT4/8/16/32, FP4/8/16/32, BF16 и вычислений с плавающей запятой: гибко адаптируется к требованиям различных типов данных — от традиционных CNN до передовых больших моделей в смартфонах, AI PC и умных автомобилях, балансируя производительность и энергоэффективность.


По сравнению с предыдущим поколением X2, производительность для CNN-моделей выросла на 30-50%, а масштабируемость производительности для многоядерных конфигураций достигла 70-80%.
При одинаковой вычислительной мощности возможности для AIGC-больших моделей выросли в 10 раз благодаря 16-кратному увеличению производительности FP16 TFLOPS, 4-кратному увеличению пропускной способности вычислительных ядер и более чем 10-кратному улучшению производительности Softmax и LayerNorm.
Благодаря этим оптимизациям, вывод больших моделей на «Чжоу И» X3 NPU стал значительно эффективнее. В тестах с большой моделью Llama2 7B, IP-ядро «Чжоу И» X3 продемонстрировало утилизацию вычислительной мощности на этапе Prefill в 72%, а с использованием аппаратного декомпрессора WDC эффективная утилизация пропускной способности на этапе Decode превысила 100%, что существенно выше средних показателей по отрасли и удовлетворяет требованиям к высокой пропускной способности при декодировании больших моделей.
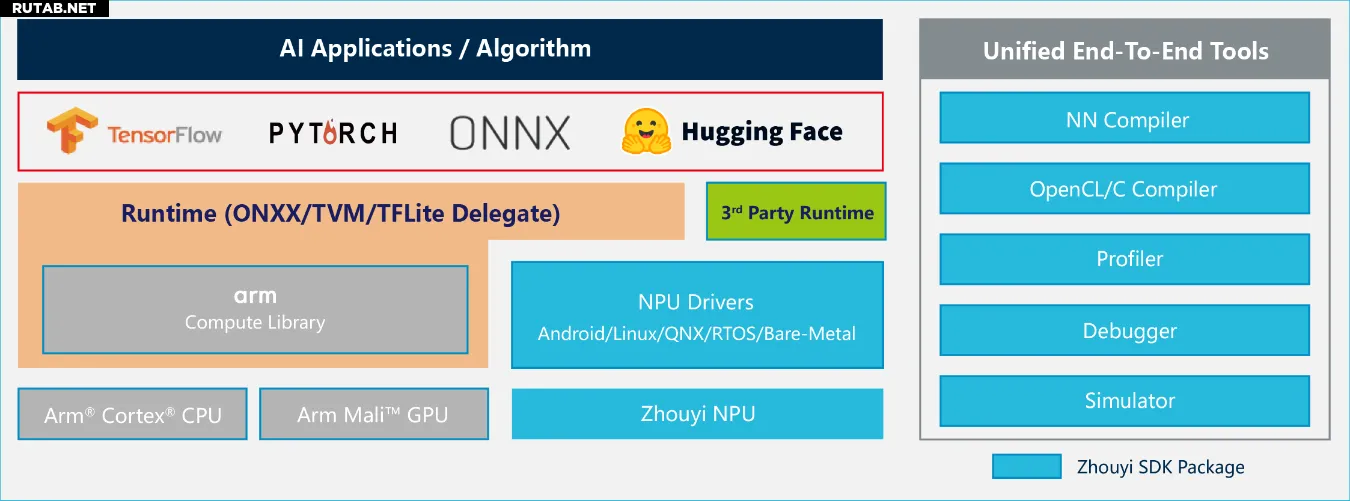
Помимо высокопроизводительного аппаратного обеспечения, «Чжоу И» X3 NPU поставляется с комплексной и удобной программной платформой «Чжоу И» Compass AI, которая за счёт совместного проектирования hardware и software значительно повышает эффективность разработки и развёртывания.
Платформа Compass AI решает ключевые проблемы разработки ИИ на устройствах, такие как сложная адаптация, длительные циклы и высокий порог входа, благодаря инструментарию, охватывающему весь цикл разработки, оптимизации для простоты использования и открытой экосистеме.
Ключевой инструмент платформы — NN Compiler (компилятор нейронных сетей), который интегрирует Parser (анализатор моделей), Optimizer (оптимизатор), GBuilder (генератор) и AIPULLM (инструмент для работы с большими моделями), обеспечивая эффективное преобразование, автоматическую оптимизацию и генерацию конфигураций для развёртывания основных моделей.
Платформа также обладает следующими основными возможностями:
— Широкая поддержка фреймворков и моделей: поддерживает более 160 операторов и 270 моделей, совместима с основными AI-фреймворками, включая TensorFlow, ONNX, PyTorch, Hugging Face, и предоставляет готовую к использованию коллекцию моделей Model Zoo.
— Инновационная функция «однощёлчкового развёртывания» для моделей Hugging Face: с помощью инструментария AIPULLM напрямую поддерживаются модели в формате Hugging Face, что обеспечивает «сквозное» преобразование и развёртывание, значительно снижая порог входа для разработчиков.
— Передовая оптимизация вывода моделей: передовая в отрасли поддержка dynamic shape для больших моделей, эффективно обрабатывающая входные последовательности любой длины; предоставляет различные методы квантования (Tensor, Channel, Token Level), а также основные схемы квантования для больших моделей, такие как GPTQ, и добавляет высокопроизводительную поддержку для моделей LLM/VLM/VLA и MoE.
— Гибкие возможности для разработчиков: предоставляет различные открытые интерфейсы для разработки и отладки пользовательских моделей и операторов; оснащена богатым набором инструментов отладки и платформой программной эмуляции битовой точности, поддерживающей многоуровневую белую разработку и тонкую настройку производительности, упрощая портирование и развёртывание алгоритмов.
— Всесторонняя совместимость с системами и гетерогенными вычислениями: поддерживает различные ОС, включая Android, Linux, RTOS, QNX, и через TVM/ONNX реализует гетерогенные вычисления на System-on-Chip (SoC), эффективно управляя такими вычислительными ресурсами, как CPU, GPU и NPU.

На презентации Arm China также продемонстрировала продукты и практические результаты линейки «Чжоу И» NPU.
— «Чжоу И» Z1: производительность 0.32–3.75 TOPS, для сценариев AIoT, поддерживает распознавание лиц, обнаружение ключевых точек тела, распознавание текста; уже используется в умных колонках с ИИ.
— «Чжоу И» Z2/Z3: производительность 1.25–5 TOPS, для рынков AIoT и базовых кокпитов, поддерживает системы переднего вспомогательного вождения, интегрированные системы парковки, виртуальные приборные панели и улучшение разрешения изображения.
— «Чжоу И» X1: производительность 10 TOPS, для премиального AIoT и автомобильных кокпитов, поддерживает мониторинг водителя и пассажиров, автоматическую парковку, круговой обзор AVM 360 и AI-шумоподавление изображений.
— «Чжоу И» X2: производительность 10-30 TOPS, для премиального AIoT, AI PC, планшетов и смартфонов с ИИ; на презентации показана работа Stable Diffusion v1.5 (генерация изображений по тексту) и CLIP (поиск изображений по тексту), демонстрирующая плавную работу мультимодального ИИ на устройстве.
— «Чжоу И» X3: производительность 8-80 FP8 TFLOPS, для инфраструктуры, умных автомобилей, мобильных устройств и AIoT; во время демонстрации были показаны результаты работы с основными большими моделями, включая плавный диалог с текстовой AI-моделью DeepSeek-R1-Distill-Qwen-1.5B, генерацию изображений через Stable Diffusion v1.5, а также мультимодальное приложение для распознавания изображений и генерации текста по изображению на модели MiniCPM v2.6, что подтвердило превосходную производительность нового NPU при выводе больших моделей на устройстве.


Нейропроцессоры (NPU) становятся ключевым компонентом для работы искусственного интеллекта непосредственно на устройствах, снижая зависимость от облачных вычислений и обеспечивая более быстрый отклик и повышенную конфиденциальность данных. Ожидается, что в ближайшие годы их распространение в смартфонах, автомобилях и IoT-устройствах будет только расти.






0 комментариев