InferenceMax: открытый бенчмарк для сравнения эффективности AI-инфраструктуры
Компания SemiAnalysis представила открытый бенчмарк InferenceMax, который оценивает эффективность работы аппаратного и программного обеспечения для AI-инференса (процесса использования уже обученных нейросетей). В отличие от существующих тестов, которые фокусируются в основном на производительности чипов, новая система измеряет совокупную стоимость владения (TCO) в долларах за миллион токенов.

InferenceMax выпущен под лицензией Apache 2.0 и тестирует сотни комбинаций AI-ускорителей и программных стеков. Тесты выполняются ежедневно с использованием актуальных версий ПО, что позволяет отслеживать изменения производительности со временем. Результаты публикуются на живой панели InferenceMax.
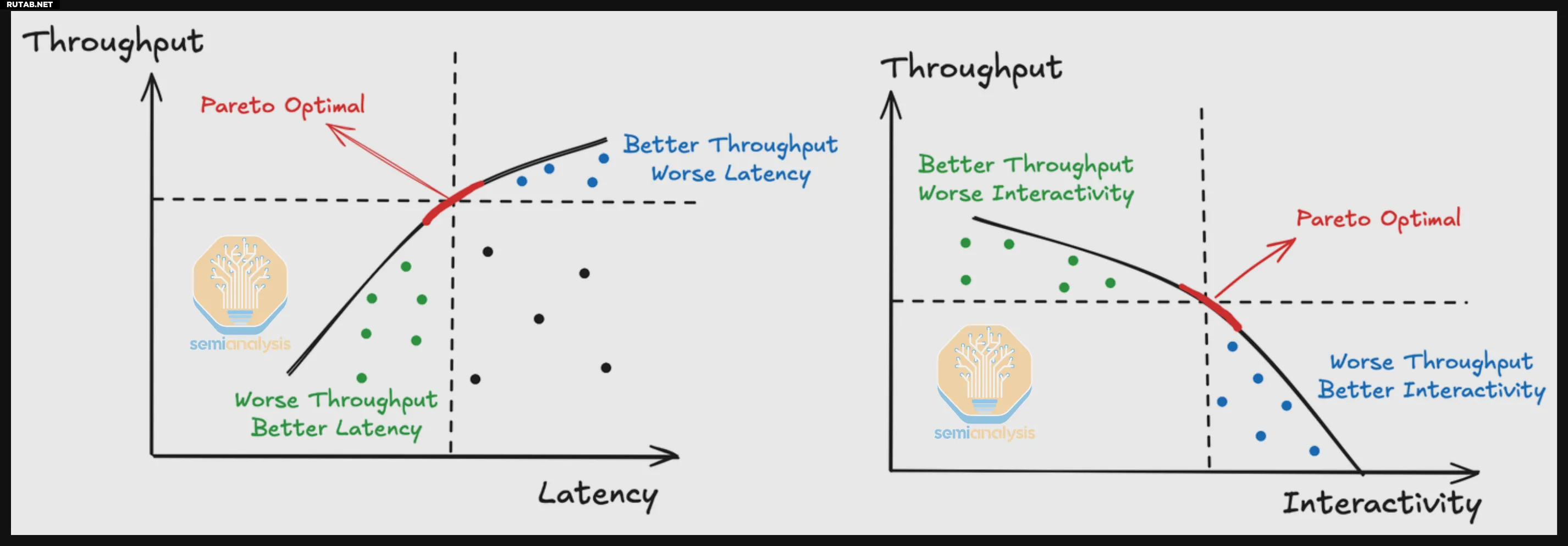
Ключевые метрики бенчмарка — пропускная способность (токенов в секунду на GPU) и интерактивность (токенов в секунду на пользователя). Высокая пропускная способность достигается при одновременном обслуживании множества запросов, но снижает скорость отклика для отдельных пользователей. Оптимальный баланс определяется для конкретного сценария использования.
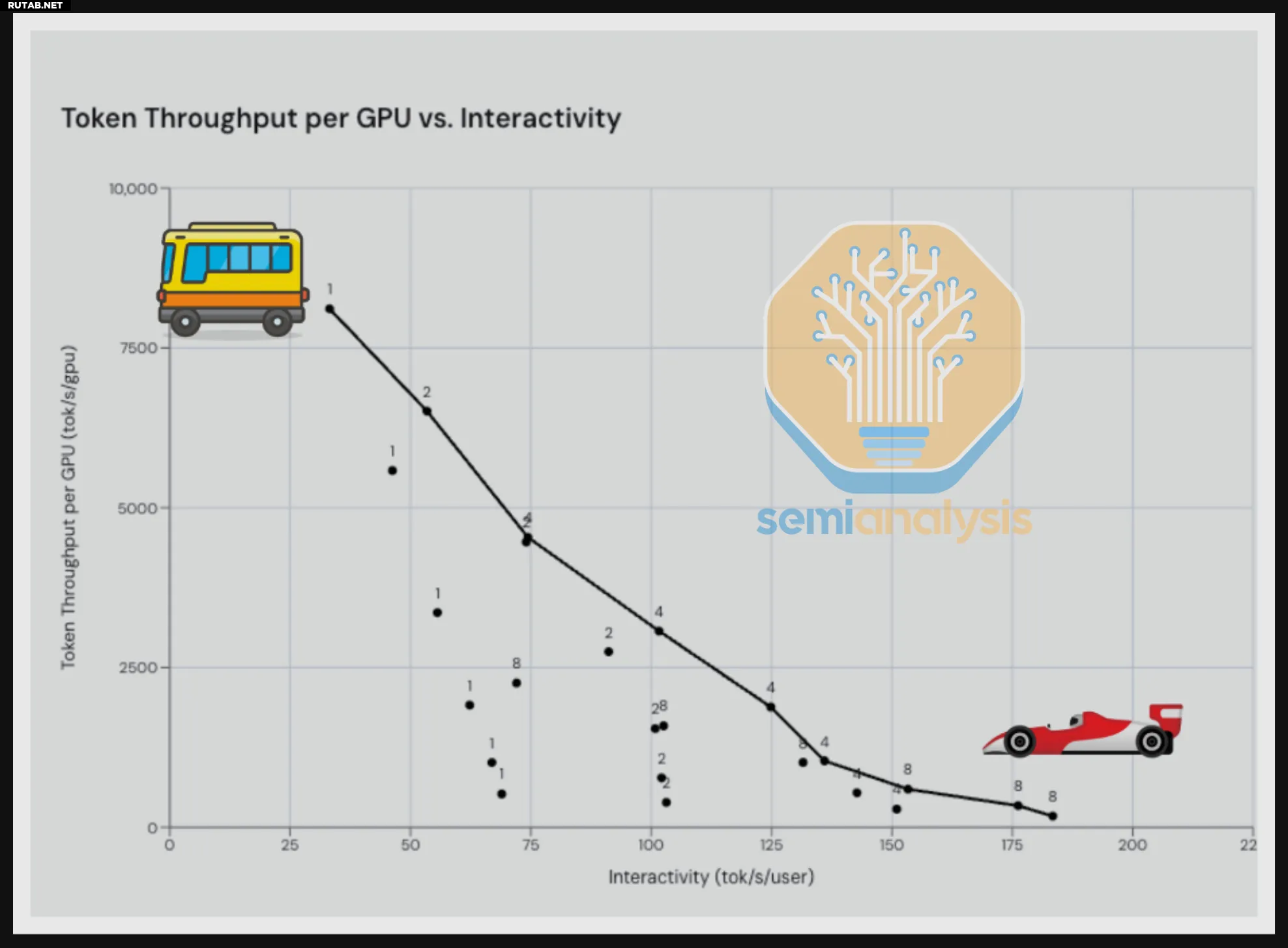
На примере сравнения AMD MI335X и Nvidia B200 видно, что хотя чип Nvidia значительно быстрее, AMD-решение оказывается конкурентоспособным по совокупной стоимости владения. При этом в AMD ROCm (аналог CUDA от Nvidia) выявлены области для улучшения, особенно в работе с 4-битными форматами данных FP4.
В процессе тестирования были обнаружены и устранены ошибки в программных стеках как AMD, так и Nvidia. В настоящее время InferenceMax поддерживает тестирование ускорителей Nvidia GB200, NVL72, B200, H200, H100 и AMD Instinct MI355X, MI325X, MI300X. В ближайшие месяцы планируется добавить поддержку тензорных процессоров Google и чипов AWS Trainium.
0 комментариев