NVIDIA открыла исходный код модели Audio2Face для создания цифровых аватаров
Компания NVIDIA открыла исходный код своей модели для 3D-анимации Audio2Face, что позволит каждому создать собственный цифровой аватар. Эта технология использует генеративные видео-модели для воспроизведения мимики, модели преобразования текста в речь и большие языковые модели для ведения диалогов, объединяя их в единый конвейер для создания реалистичного цифрового двойника.
Весь процесс начинается с анализа акустического входа, который включает такие характеристики, как интонация и фонемы. Эти данные преобразуются в поток анимации, который затем проецируется на лицевые выражения аватара, позволяя визуально определить его настроение. Конвейер может работать как с заранее записанным аудио для создания скриптового контента, так и с живыми данными для синхронизации губ и мимики в реальном времени.

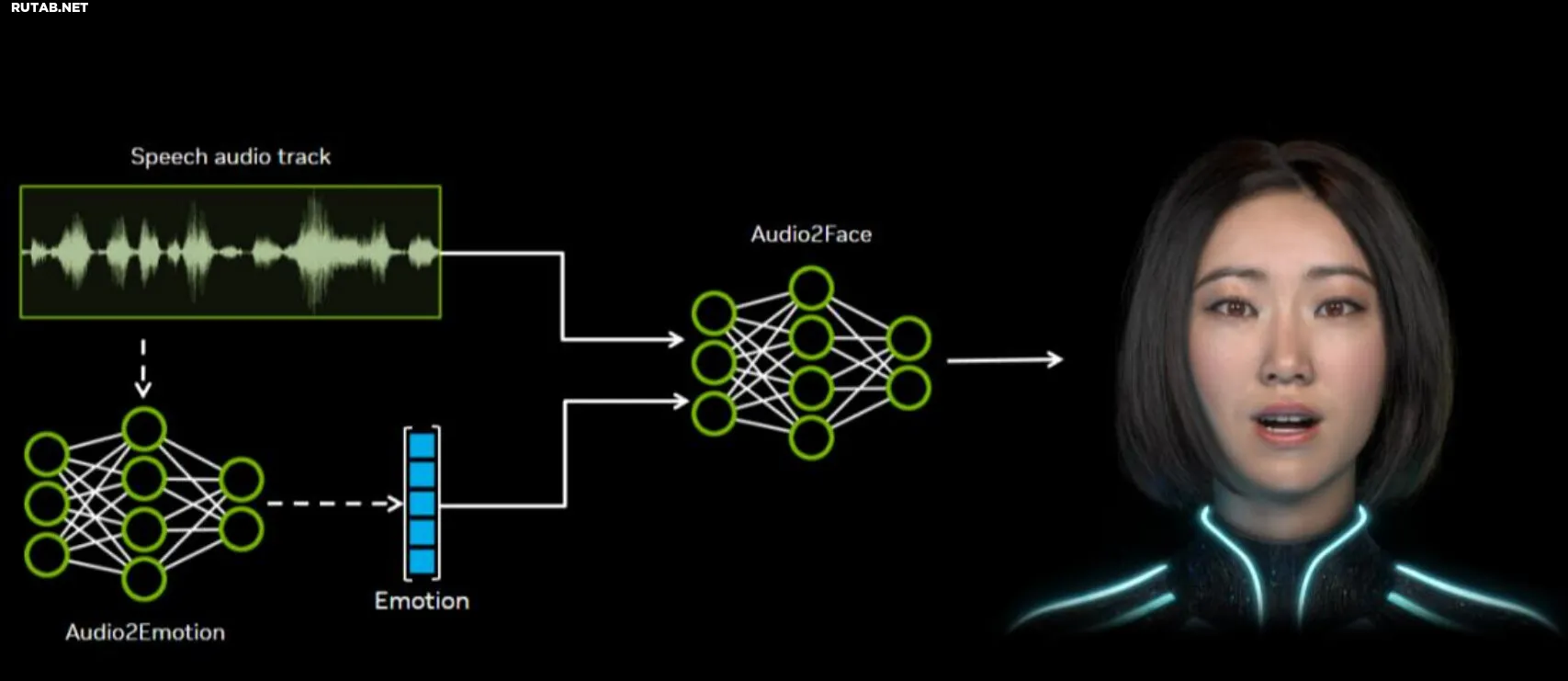
NVIDIA открывает не только саму модель, но и весь стек технологий Audio2Face, включая SDK и учебные фреймворки. Это позволяет как игровым разработчикам, так и энтузиастам использовать технологию в своих проектах. Компания также предоставила плагины для Autodesk Maya и Unreal Engine, что обеспечивает немедленную интеграцию генеративной модели в рабочие процессы 3D-графики.
Разработчики игр уже рассматривают Audio2Face как готовое к использованию решение для создания правдоподобной лицевой анимации. Инструмент автоматически преобразует диалоги в выразительную, многоязычную синхронизацию губ и мимику, избавляя художников от трудоёмкой работы с каждым кадром и позволяя сосредоточиться на повествовании. Студии, такие как Reallusion, Survios и The Farm 51, отмечают, что технология ускоряет рабочие процессы, освобождает аниматоров для более сложных задач и делает реализуемыми ранее непрактичные идеи, сохраняя при этом аутентичность и эмоциональную глубину персонажей.
Источник: Techpowerup.com
0 комментариев