Nvidia планирует использовать кремниевую фотонику и сопакутированную оптику в AI-кластерах к 2026 году

Растущие потребности в передаче данных между всё более масштабными кластерами AI-ускорителей подталкивают к использованию оптических технологий для коммуникации на сетевом уровне. Ранее в этом году Nvidia анонсировала, что её платформы следующего поколения для AI-кластеров будут использовать кремниевые фотонные интерконнекты с сопакутированной оптикой (Co-Packaged Optics, CPO) для более высоких скоростей передачи при меньшем энергопотреблении. На конференции Hot Chips компания раскрыла дополнительные детали о своих решениях Quantum-X и Spectrum-X, которые появятся в 2026 году.
Дорожная карта Nvidia, вероятно, будет тесно связана с планами TSMC по платформе COUPE, которая развивается в три этапа. Первое поколение — оптический двигатель для коннекторов OSFP с пропускной способностью 1,6 Тбит/с и сниженным энергопотреблением. Второе поколение переходит к упаковке CoWoS с сопакутированной оптикой, обеспечивая 6,4 Тбит/с на уровне материнской платы. Третье поколение нацелено на 12,8 Тбит/с внутри корпусов процессоров и дальнейшее снижение энергопотребления и задержек.
Зачем нужна CPO?
В крупных AI-кластерах тысячи GPU должны работать как единая система, что создаёт сложности в их соединении: вместо отдельных коммутаторов уровня Tier-1 (Top-of-Rack) в каждой стойке, связанных короткими медными кабелями, коммутаторы перемещаются в конец ряда для создания единой фабричной сети с низкой задержкой между несколькими стойками. Это увеличивает расстояние между серверами и их первым коммутатором, делая медные соединения непрактичными на скоростях вроде 800 Гбит/с, поэтому оптические подключения становятся необходимыми почти для каждого соединения сервер-коммутатор и коммутатор-коммутатор.
Изображение: Nvidia
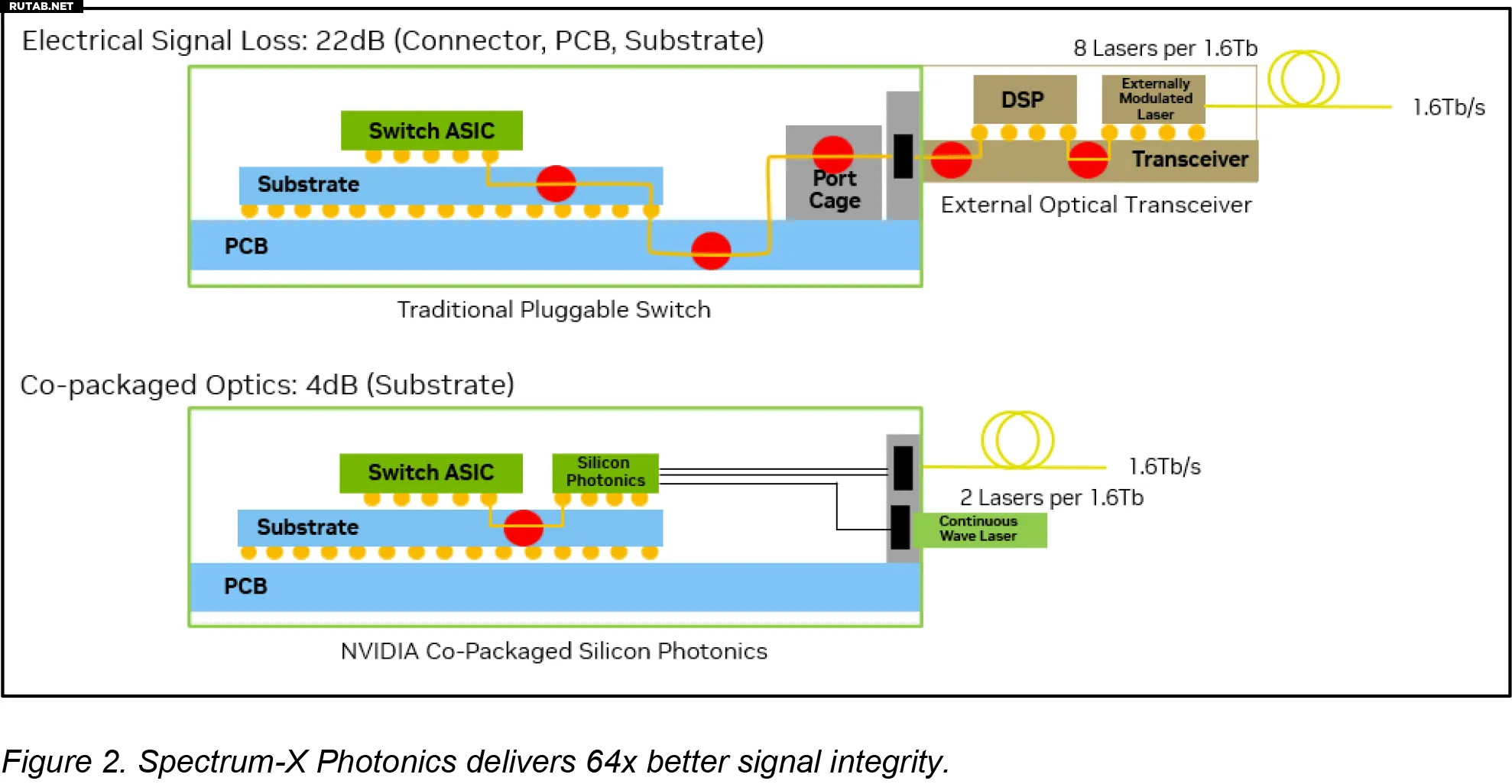
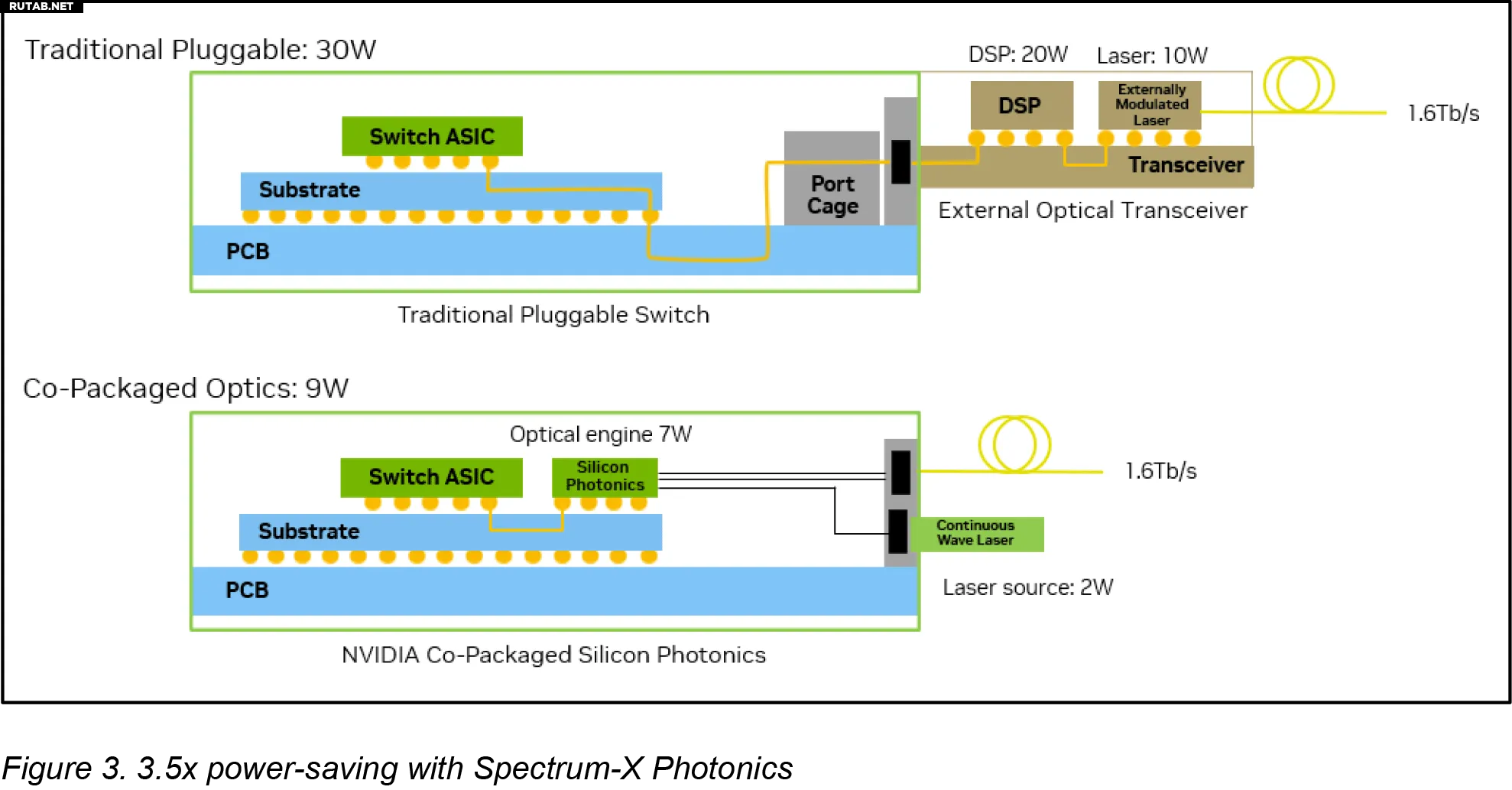
Использование съёмных оптических модулей в такой среде имеет очевидные ограничения: сигналы данных в таких конструкциях покидают ASIC, проходят через плату и коннекторы, и только затем преобразуются в свет. Этот метод приводит к значительным электрическим потерям — до 22 децибел на каналах 200 Гбит/с, что требует компенсации с помощью сложной обработки и увеличивает энергопотребление на порт до 30 Вт (что, в свою очередь, требует дополнительного охлаждения и создаёт точку потенциального отказа). По словам Nvidia, это становится почти невыносимым по мере роста масштабов AI-развёртываний.
Изображение: Nvidia
CPO позволяет избежать недостатков традиционных съёмных оптических модулей, встраивая двигатель оптического преобразования рядом с ASIC коммутатора, так что сигнал почти сразу соединяется с оптоволокном, вместо того чтобы проходить по длинным электрическим трассам. В результате электрические потери сокращаются до 4 децибел, а энергопотребление на порт снижается до 9 Вт. Такая компоновка устраняет множество компонентов, которые могут выйти из строя, и значительно упрощает реализацию оптических интерконнектов.
Nvidia заявляет, что переход от традиционных съёмных трансиверов и интеграция оптических двигателей непосредственно в кремний коммутаторов (благодаря платформе COUPE от TSMC) обеспечивает существенный прирост эффективности, надёжности и масштабируемости. Улучшения CPO по сравнению со съёмными модулями, по данным Nvidia, впечатляют: в 3,5 раза выше энергоэффективность, в 64 раза лучше целостность сигнала, в 10 раз выше отказоустойчивость из-за меньшего числа активных устройств и примерно на 30% быстрее развёртывание благодаря упрощённому обслуживанию и сборке.
CPO для Ethernet и InfiniBand
Nvidia представит платформы оптической коммутации на основе CPO как для технологий Ethernet, так и для InfiniBand. Сначала компания планирует выпустить коммутаторы Quantum-X InfiniBand в начале 2026 года. Каждый такой коммутатор будет обеспечивать пропускную способность 115 Тбит/с, поддерживая 144 порта со скоростью 800 Гбит/с каждый. Система также интегрирует ASIC с производительностью 14,4 TFLOPS для внутрисетевой обработки и поддержкой протокола Nvidia Scalable Hierarchical Aggregation Reduction Protocol (SHARP) 4-го поколения для снижения задержек при коллективных операциях. Коммутаторы будут использовать жидкостное охлаждение.

Изображение: Nvidia
Параллельно Nvidia намерена внедрить CPO в Ethernet с помощью своей платформы Spectrum-X Photonics во второй половине 2026 года. Она будет основана на ASIC Spectrum-6, который будет использоваться в двух устройствах: SN6810 с пропускной способностью 102,4 Тбит/с и 128 портами по 800 Гбит/с, и более крупном SN6800 с масштабированием до 409,6 Тбит/с и 512 портами на той же скорости. Оба также используют жидкостное охлаждение.

Изображение: Nvidia
Nvidia предполагает, что её коммутаторы на основе CPO будут питать новые AI-кластеры для генеративного ИИ, которые становятся всё larger и сложнее. Благодаря использованию CPO такие кластеры избавляют от тысячи дискретных компонентов, предлагая более быструю установку, простое обслуживание и сниженное энергопотребление на соединение. В результате кластеры на Quantum-X InfiniBand и Spectrum-X Photonics демонстрируют улучшения по таким показателям, как время до включения, время до первого токена и долгосрочная надёжность.
Nvidia подчёркивает, что сопакутированная оптика — не опциональное улучшение, а структурное требование для будущих AI-дата-центров, что означает, что компания будет позиционировать свои оптические интерконнекты как ключевое преимущество перед решениями масштаба серверной стойки для ИИ конкурентов, таких как AMD. Именно поэтому AMD приобрела Enosemi.
Перспективы развития
Важно отметить, что развитие инициативы Nvidia в области кремниевой фотоники тесно связано с эволюцией платформы COUPE (Compact Universal Photonic Engine) от TSMC, которая будет развиваться в ближайшие годы, улучшая и платформы CPO от Nvidia. COUPE первого поколения от TSMC создаётся путём сборки 65-нм электронной интегральной схемы (EIC) с фотонной интегральной схемой (PIC) с использованием технологии упаковки SoIC-X.
Дорожная карта TSMC COUPE разворачивается в три этапа. Первое поколение — оптический двигатель для коннекторов OSFP с пропускной способностью 1,6 Тбит/с и сниженным энергопотреблением. Второе поколение переходит к упаковке CoWoS с сопакутированной оптикой, обеспечивая 6,4 Тбит/с на уровне материнской платы. Третье поколение нацелено на 12,8 Тбит/с внутри корпусов процессоров и дальнейшее снижение энергопотребления и задержек.
Источник: Tomshardware.com
0 комментариев