Выпущен бенчмарк MLPerf Client 1.0 для тестирования локального ИИ
ИИ-революция в самом разгаре, но в отличие от прошлых сдвигов в вычислительных технологиях, большинство из нас взаимодействует с самыми продвинутыми версиями ИИ-моделей в облаке. Ведущие сервисы, такие как ChatGPT, Claude и Gemini, остаются облачными. Однако локально запускаемые ИИ-модели по-прежнему представляют интерес из-за вопросов приватности, исследований и контроля. Поэтому важно иметь возможность надежно и объективно измерять производительность ИИ на клиентских системах с GPU и NPU.
Локальный ИИ остается крайне динамичной сферой, поскольку производители оборудования и ПО работают над определением типов задач, наиболее подходящих для локального выполнения, и оптимальных вычислительных ресурсов для них. Чтобы помочь ориентироваться в этой быстро меняющейся среде, консорциум MLCommons и его рабочая группа MLPerf Client разработали бенчмарк для клиентских систем в сотрудничестве с крупными производителями оборудования и ПО.
MLPerf Client 1.0 только что выпущен с серьезными улучшениями по сравнению с предыдущей версией 0.6. Новый инструмент включает больше ИИ-моделей, поддерживает аппаратное ускорение на большем количестве устройств от большего числа производителей и тестирует более широкий спектр возможных взаимодействий пользователей с большими языковыми моделями. Кроме того, он получил удобный графический интерфейс, что сделает его более привлекательным для обычных пользователей.
MLPerf Client 1.0 теперь может тестировать производительность с моделями Meta Llama 2 7B Chat и Llama 3.1 8B Instruct, а также Microsoft Phi 3.5 Mini Instruct. Также добавлена поддержка экспериментальной модели Phi 4 Reasoning 14B в качестве примера производительности следующего поколения языковых моделей с большим количеством параметров и расширенными возможностями.
Бенчмарк теперь охватывает более широкий спектр типов запросов, включая анализ кода (что особенно актуально для разработчиков) и суммирование контента с большими контекстными окнами в 4000 или 8000 токенов (экспериментальная функция).
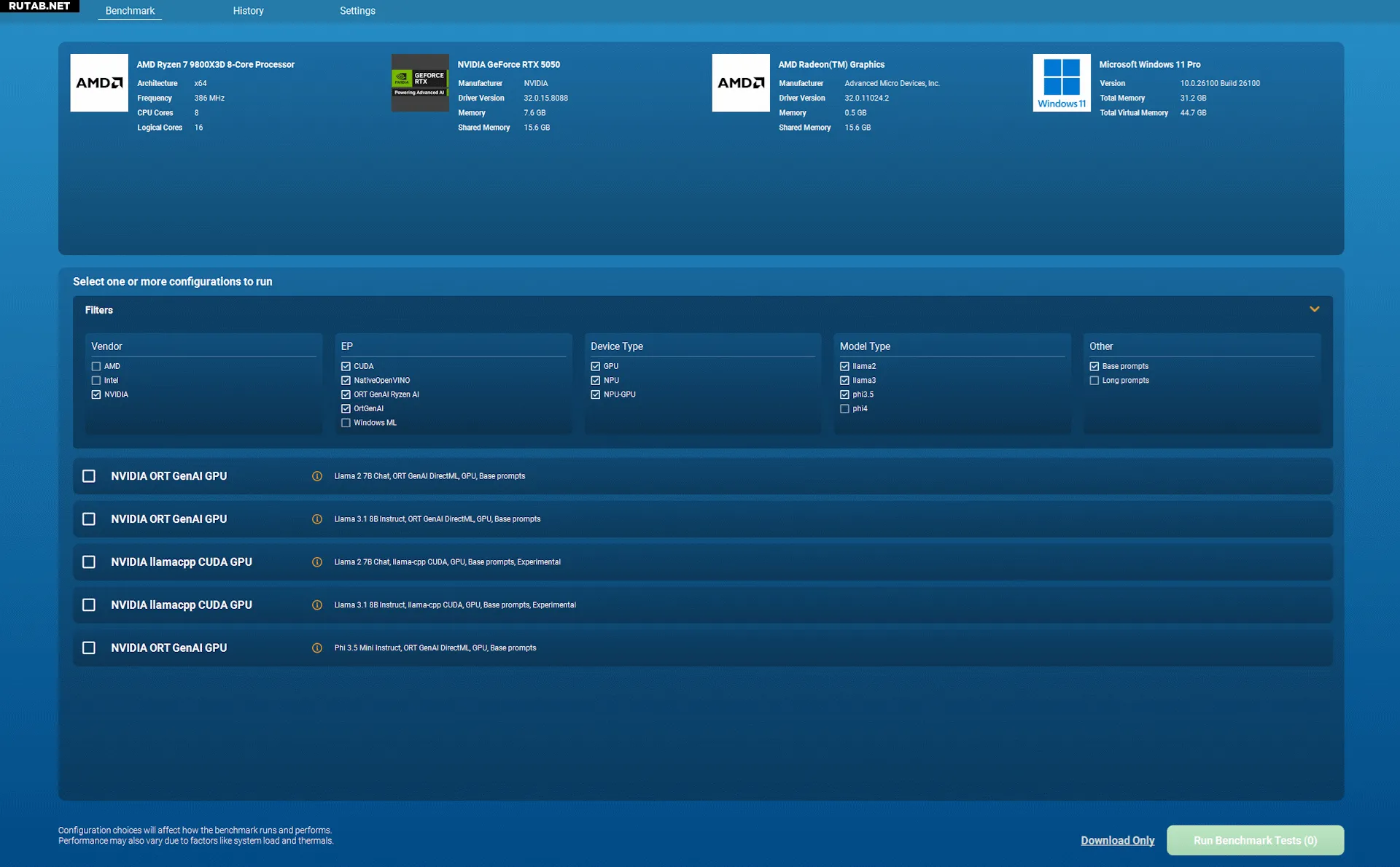
Поддерживаемые аппаратные платформы и пути ускорения:
- Гибридная поддержка NPU и GPU AMD через ONNX Runtime GenAI и Ryzen AI SDK
- Поддержка GPU AMD, Intel и NVIDIA через ONNX Runtime GenAI-DirectML
- Поддержка NPU и GPU Intel через OpenVINO
- Гибридная поддержка NPU и CPU Qualcomm через Qualcomm Genie и QAIRT SDK
- Поддержка GPU Apple Mac через MLX
Экспериментальные пути выполнения:
- Поддержка NPU и GPU Intel через Microsoft Windows ML и OpenVINO
- Поддержка GPU NVIDIA через Llama.cpp-CUDA
- Поддержка GPU Apple Mac через Llama.cpp-Metal
Изображение: Future
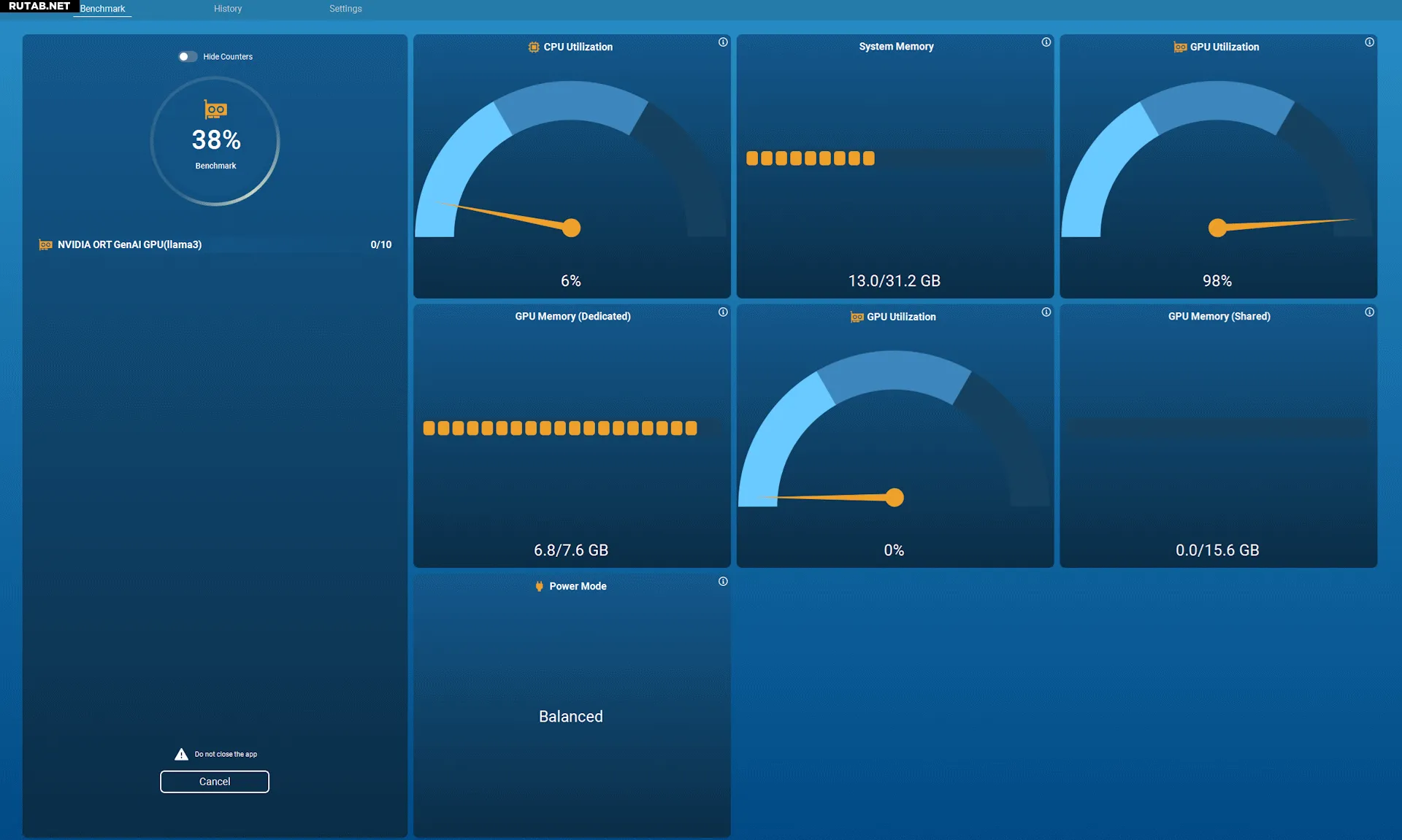
Главное нововведение — графический интерфейс, который позволяет пользователям легко выбирать тесты и отслеживать использование аппаратных ресурсов в реальном времени. Ранние версии MLPerf Client были доступны только через командную строку, поэтому новый интерфейс сделает бенчмарк более доступным как для обычных пользователей, так и для профессиональных тестировщиков.
MLPerf Client 1.0 уже доступен для бесплатного скачивания на GitHub. Если вы хотите проверить производительность своей системы в различных ИИ-задачах, стоит попробовать этот инструмент.
Источник: Tomshardware.com
* Meta, Facebook и Instagram запрещены в России.






0 комментариев