AMD и Nexa AI улучшили NexaQuant
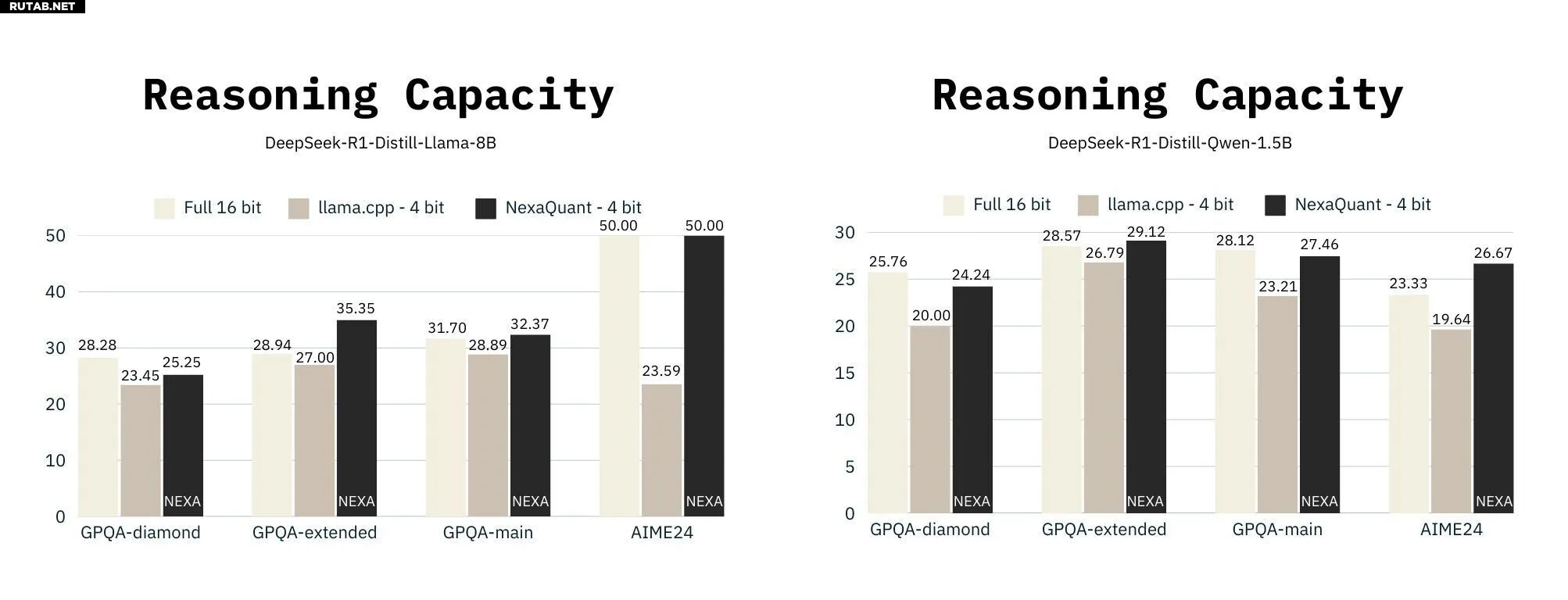
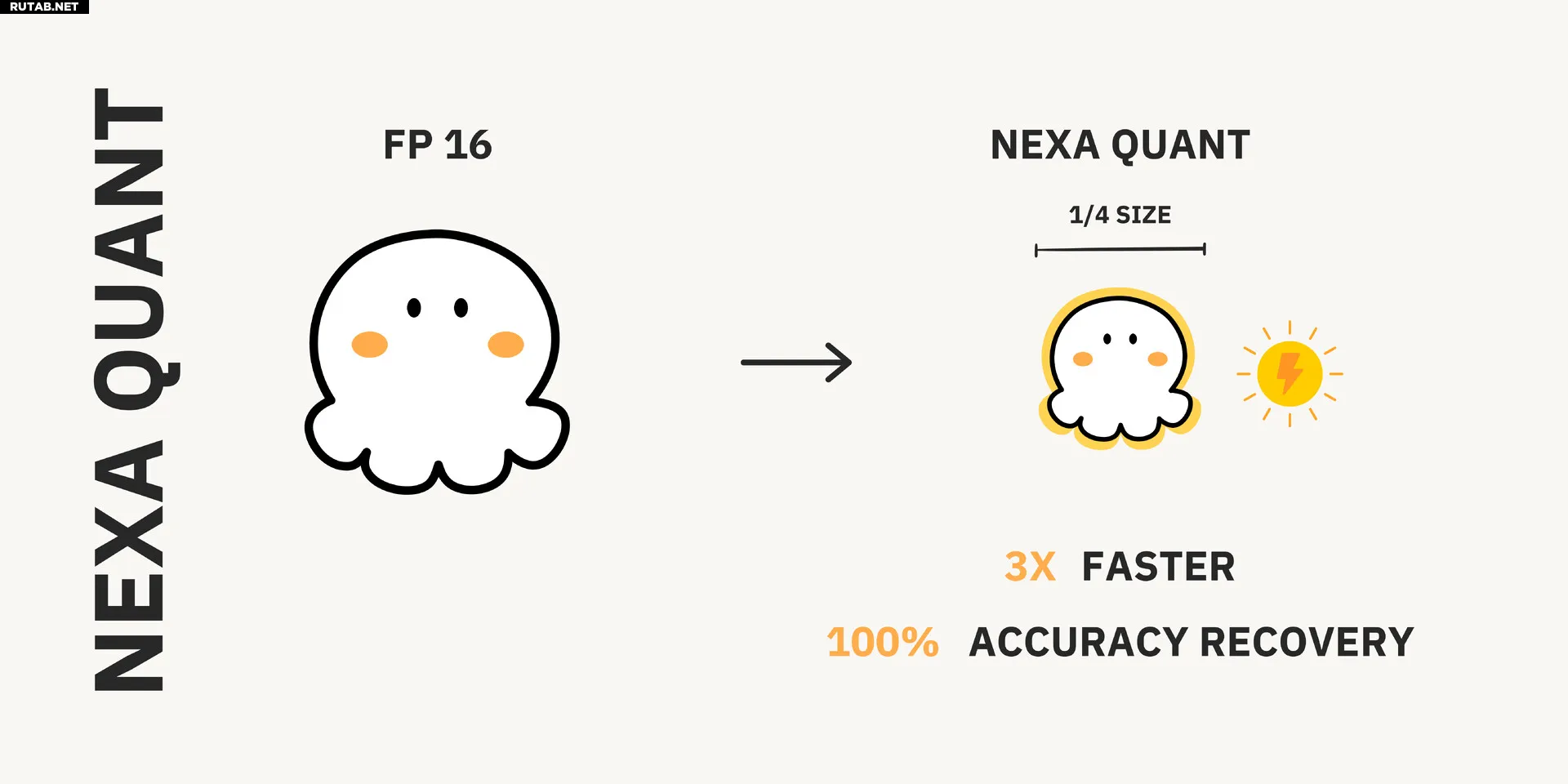
Nexa AI сегодня анонсировала NexaQuants двух DeepSeek R1 Distills: DeepSeek R1 Distill Qwen 1.5B и DeepSeek R1 Distill Llama 8B. Популярные методы квантования, такие как основанный на llama.cpp Q4 KM, позволяют большим языковым моделям значительно сократить объем памяти и обычно предлагают низкие потери перплексии для плотных моделей в качестве компромисса. Однако даже низкие потери перплексии могут привести к снижению способности рассуждения для (плотных или MoE) моделей, использующих трассировки цепочки мыслей. Nexa AI заявила, что NexaQuants способны восстановить эту потерю способности рассуждения (по сравнению с полной 16-битной точностью), сохраняя при этом 4-битную квантизацию и все время сохраняя преимущество в производительности. Тесты, предоставленные Nexa AI, можно увидеть ниже.
Мы видим, что квантованные дистилляты DeepSeek R1 с Q4 KM показывают немного худшие результаты (за исключением теста AIME24 на дистилляте Llama 3 8b, который показывает значительно более низкие результаты) в тестах LLM, таких как GPQA и AIME24, по сравнению с их полными 16-битными аналогами. Переход к квантованию Q6 или Q8 был бы одним из способов решения этой проблемы, но это привело бы к тому, что модель стала бы работать немного медленнее и потребовала бы больше памяти. Nexa AI заявила, что NexaQuants использует собственный метод квантования для восстановления потерь, сохраняя квантование на уровне 4 бит. Это означает, что пользователи теоретически могут получить лучшее из обоих миров: точность и скорость.

Дополнительную информацию о дистилляторах NexaQuant DeepSeek R1 можно прочитать здесь.

Для загрузки доступны следующие дистилляции NexaQuants DeepSeek R1:
Как запустить NexaQuants на процессорах AMD Ryzen или видеокартах Radeon
Мы рекомендуем использовать LM Studio для всех ваших нужд в области LLM.
- 1) Загрузите и установите LM Studio с lmstudio.ai/ryzenai
- 2) Перейдите на вкладку «Обнаружение» и вставьте ссылку на huggingface одного из nexaquants выше.
- 3) Дождитесь окончания загрузки модели.
- 4) Вернитесь на вкладку чата и выберите модель из выпадающего меню. Убедитесь, что выбрано «выбрать параметры вручную».
- 5) Установите уровни разгрузки графического процессора на МАКС.
- 6) Загрузите модель и начните общаться!
Согласно этим данным, предоставленным Nexa AI, разработчики также могут использовать версии DeepSeek R1 Distills от NexaQuant, указанные выше, для получения общего повышения производительности в приложениях на основе llama.cpp или GGUF.
Источник: AMD Community
0 комментариев