Учёные создали модель, объясняющую, как люди учатся на наказаниях
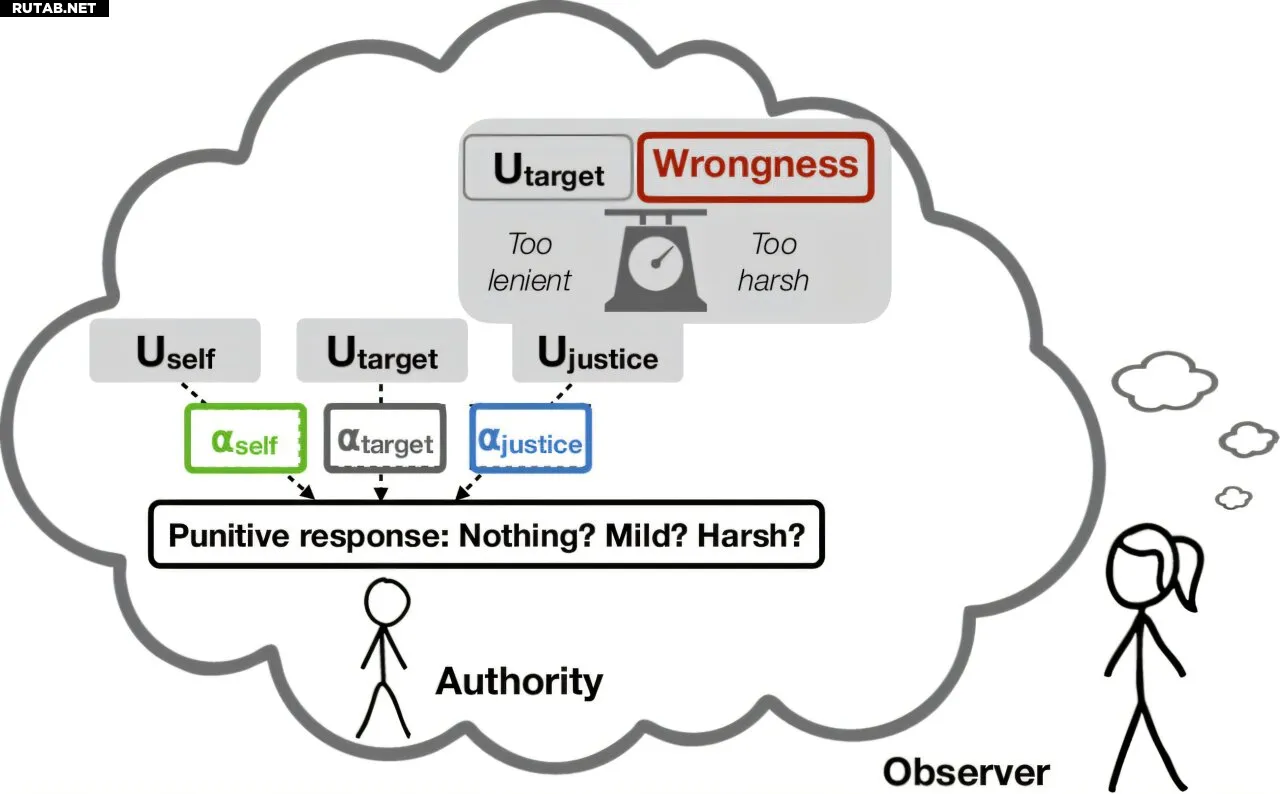
Модель обратного планирования, при которой наблюдатели одновременно обновляют свои представления о неправильности действия-нарушения и мотивах авторитета, выполняя байесовский вывод на основе интуитивной теории принятия карательных решений авторитетом. Автор: Proceedings of the National Academy of Sciences (2025). DOI: 10.1073/pnas.2500730122
От тайм-аутов для малышей до тюремных сроков для преступников — наказание укрепляет социальные нормы, давая понять, что нарушитель совершил нечто недопустимое. По крайней мере, такова обычно цель — но эта стратегия может дать обратный эффект. Когда наказание воспринимается как слишком суровое, у наблюдателей может сложиться впечатление, что авторитетная фигура движима чем-то иным, кроме справедливости.
Бывает сложно предсказать, что люди вынесут из конкретного наказания, потому что каждый делает свои собственные выводы — не только о приемлемости действия, приведшего к наказанию, но и о легитимности авторитета, его назначившего.
Новая вычислительная модель, разработанная учёными из Института исследований мозга Макговерна при MIT, осмысляет эти сложные когнитивные процессы, воссоздавая способы, которыми люди учатся на наказаниях, и раскрывая, как их рассуждения формируются предшествующими убеждениями.
Их работа, опубликованная 4 августа в Proceedings of the National Academy of Sciences, объясняет, как одно наказание может посылать разные сообщения разным людям и даже укреплять противоположные точки зрения групп, придерживающихся разных мнений об авторитетах или социальных нормах.
«Ключевая интуиция в этой модели — это факт, что вам приходится одновременно оценивать и норму, которую нужно усвоить, и авторитет, который наказывает», — говорит исследователь Макговерна и профессор когнитивных наук и наук о мозхе имени Джона У. Джарва Ребекка Сакс, руководившая исследованием.
«Одно действительно важное следствие этого — даже там, где никто не спорит о фактах — все знают, какое действие произошло, кто его наказал и что они сделали для наказания — разные наблюдатели одной и той же ситуации могут прийти к разным выводам».
Например, говорит она, ребёнок, отправленный в угол после укуса брата или сестры, может интерпретировать событие иначе, чем родитель. Один может увидеть наказание как соразмерное и важное, обучающее ребёнка не кусаться. Но если укус, с точки зрения малыша, казался разумной тактикой в midst ссоры, наказание может быть воспринято как несправедливое, и урок будет утерян.
Люди опираются на собственные знания и мнения, когда оценивают эти ситуации — но чтобы изучить, как мозг интерпретирует наказание, Сакс и аспирантка Сетаеш Радкани хотели вывести эти личные идеи из уравнения.
Им нужно было чёткое понимание убеждений, которые люди имели, наблюдая наказание, чтобы они могли узнать, как разные виды информации изменяют их восприятие. Поэтому Радкани создала сценарии в вымышленных деревнях, где власти наказывали отдельных лиц за действия, не имеющие очевидных аналогов в реальном мире.
Участники наблюдали эти сценарии в серии экспериментов, с разной информацией, предлагаемой в каждом. В некоторых случаях, например, участникам говорили, что наказываемый человек был либо союзником, либо конкурентом авторитета, тогда как в других случаях возможная предвзятость авторитета оставалась неоднозначной.
«Это даёт нам действительно контролируемую установку для варьирования предшествующих убеждений», — объясняет Радкани. «Мы могли спросить, что люди узнают из наблюдения за карательными решениями разной степени строгости, в ответ на действия, варьирующиеся по уровню неправильности, со стороны авторитетов, варьирующихся по уровню разных мотивов».
Для каждого сценария участников просили оценить четыре фактора: насколько авторитетная фигура заботится о справедливости; эгоистичность авторитета; предвзятость авторитета за или против наказываемого лица; и неправильность наказанного действия.
Исследовательская группа задавала эти вопросы, когда участники впервые знакомились с гипотетическим обществом, а затем отслеживала, как их ответы менялись после наблюдения за наказанием. Во всех сценариях первоначальные убеждения участников об авторитете и неправильности действия формировали степень, в которой эти убеждения смещались после наблюдения наказания.
Радкани удалось воспроизвести эти тонкие интерпретации с помощью когнитивной модели, основанной на идее, которую команда Сакс давно использует для размышлений о том, как люди интерпретируют действия других. То есть, чтобы делать выводы о намерениях и убеждениях других, мы предполагаем, что люди выбирают действия, которые, как они ожидают, помогут им достичь своих целей.
Чтобы применить эту концепцию к сценариям наказания, Радкани разработала модель, которая оценивает значение наказания (действия, направленного на достижение цели авторитета), учитывая вред, связанный с этим наказанием; его издержки или выгоды для авторитета; и его соразмерность нарушению.
Оценивая эти факторы наряду с предшествующими убеждениями об авторитете и наказанном действии, модель смогла предсказать ответы людей на гипотетические сценарии наказания, поддерживая идею о том, что люди используют похожую ментальную модель. «Вам нужно, чтобы они учитывали эти вещи, иначе вы не сможете понять, как люди понимают наказание, когда наблюдают его», — говорит Сакс.
Хотя команда разработала свои эксперименты, чтобы исключить предвзятые идеи о людях и действиях в их вымышленных деревнях, не все пришли к одинаковым выводам из наблюдаемых наказаний.
Группа Сакс обнаружила, что общее отношение участников к авторитету влияло на их интерпретацию событий. Те, у кого были более авторитарные установки — оцененные через стандартный опрос — склонны оценивать наказанные действия как более неправильные, а авторитеты — как более мотивированных справедливостью, чем другие наблюдатели.
«Если мы отличаемся от других людей, есть непроизвольная тенденция говорить: „либо у них другие доказательства, чем у нас, либо они сумасшедшие“», — говорит Сакс. Вместо этого, говорит она, «Это часть того, как люди думают о действиях друг друга».
«Когда группа людей, начинающих с разных предварительных убеждений, получает общие доказательства, они не обязательно придут к общим убеждениям. Это верно, даже если все ведут себя рационально», — говорит Сакс.
Такой образ мышления также означает, что одно и то же действие может одновременно укреплять противоположные точки зрения. Моделирование и эксперименты лаборатории Сакс показали, что когда эти точки зрения формируют интерпретации будущих наказаний отдельными лицами, мнения групп будут продолжать расходиться.
Например, наказание, которое кажется слишком суровым группе, подозревающей предвзятость авторитета, может сделать эту группу ещё более скептичной к будущим действиям авторитета. Между тем, люди, которые видят то же наказание как справедливое, а авторитет — как справедливого, с большей вероятностью сделают вывод, что будущие действия авторитетной фигуры также справедливы.
«Вы получите порочный круг поляризации, сохраняющийся и фактически распространяющийся на новые вещи», — говорит Радкани.
Исследователи говорят, что их выводы указывают на стратегии передачи социальных норм через наказание. «В нашей модели совершенно разумно делать всё возможное, чтобы ваше действие выглядело так, как будто оно исходит из заботы о долгосрочном результате этого человека, и что оно соразмерно нарушению нормы, которое они совершили», — говорит Сакс. «Это ваш лучший шанс, чтобы наказание было интерпретировано педагогически, а не как доказательство того, что вы хулиган».
Тем не менее, она говорит, что этого не всегда будет достаточно. «Если убеждения сильны в другую сторону, очень трудно наказывать и при этом поддерживать веру в то, что вы были мотивированы справедливостью».
Больше информации: Setayesh Radkani et al, What people learn from punishment: A cognitive model, Proceedings of the National Academy of Sciences (2025). DOI: 10.1073/pnas.2500730122
Источник: Massachusetts Institute of Technology


0 комментариев