Новый китайский GPU MTT S5000 впервые представлен: 80 ГБ памяти и 1 петафлопс для конкуренции с NVIDIA H100
После того как компания Zhipu AI представила новую крупную языковую модель GLM-5, китайская компания Moore Threads немедленно объявила о завершении полной адаптации и проверки своей флагманской гибридной GPU для обучения и вывода MTT S5000 под эту модель, обеспечив поддержку в кратчайшие сроки.
MTT S5000 — это универсальная GPU для вычислений, разработанная Moore Threads специально для обучения больших моделей, логического вывода и высокопроизводительных вычислений. Она основана на архитектуре MUSA четвертого поколения «Пинху» и изначально адаптирована под такие популярные фреймворки, как PyTorch, Megatron-LM, vLLM и SGLang.


Карта была впервые анонсирована ещё в 2024 году, но её конкретный дизайн, параметры и производительность до сих пор не раскрывались. Теперь, одновременно с объявлением об адаптации GLM-5, Moore Threads впервые раскрыла часть характеристик MTT S5000.
Согласно данным, одна карта MTT S5000 оснащена до 80 ГБ видеопамяти с пропускной способностью 1,6 ТБ/с. По сравнению с предыдущим поколением MTT S4000 это увеличение на 67% и 113% соответственно. Пропускная способность межкарточного соединения достигает 784 ГБ/с.
Карта полностью поддерживает вычисления с полной точностью от FP8 до FP64 и является одной из первых китайских GPU для обучения, изначально поддерживающих точность FP8, с аппаратным блоком ускорения Tensor Core для FP8.
По сравнению с BF16/FP16, FP8 позволяет сократить ширину данных вдвое, снизить нагрузку на пропускную способность памяти на 50% и теоретически удвоить вычислительную пропускную способность. Архитектура полностью поддерживает такие модели, как DeepSeek и Qwen (千问), что может повысить производительность обучения более чем на 30%.
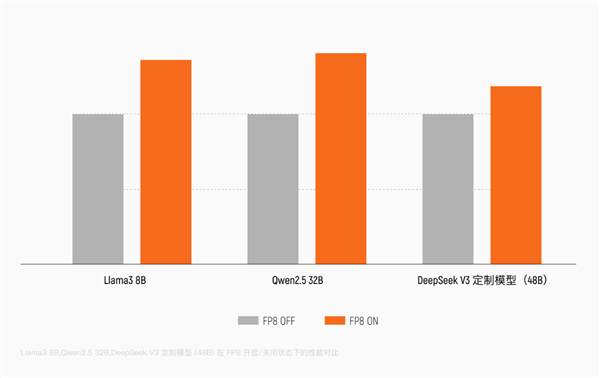
Максимальная производительность MTT S5000 в вычислениях ИИ с точностью FP8 достигает 1000 TFLOPS, впервые выходя на уровень PFLOPS, то есть одного квадриллиона (10^15) операций в секунду.
Для сравнения, производительность MTT S4000 составляла INT8 256 TOPS, BF16 128 TFLOPS, FP32/64 32/64 TFLOPS.
По словам инсайдеров, фактическая производительность MTT S5000 может конкурировать с NVIDIA H100, особенно в задачах тонкой настройки мультимодальных больших моделей, где некоторые показатели даже превосходят H100 и начинают приближаться к новейшей архитектуре Blackwell.
В январе 2026 года исследовательский институт Beijing Academy of Artificial Intelligence (BAAI) на кластере из тысячи карт MTT S5000 завершил сквозное обучение и проверку выравнивания передовой модели «воплощённого мозга» RoboBrain 2.5 (сотни миллиардов параметров). MTT S5000 продемонстрировала чрезвычайно высокую согласованность результатов с кластером на H100, разница в значениях потерь при обучении составила всего 0,62%, а общая эффективность обучения даже немного превзошла конкурента.
Согласно практическим тестам интернет-компаний, в типичных сквозных задачах логического вывода и обучения производительность MTT S5000 примерно в 2,5 раза выше, чем у NVIDIA H20.
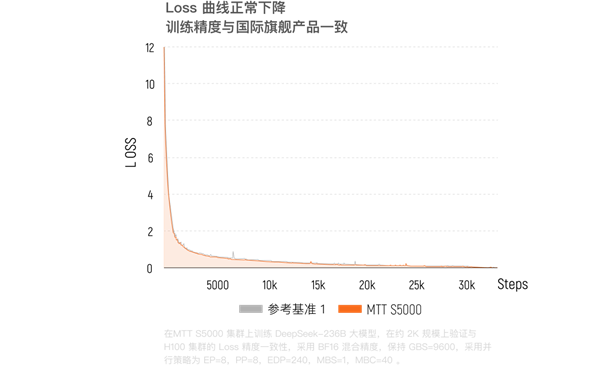
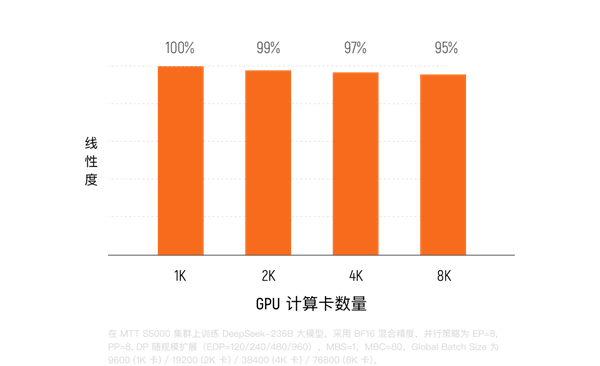
В настоящее время кластер Kua'e на десятки тысяч карт на базе MTT S5000 уже развёрнут, его производительность в операциях с плавающей запятой достигает 10 ExaFLOPS (10^18 операций в секунду). При обучении плотных моделей MFU достигает 60%, а в моделях смешанных экспертов (MoE) сохраняется на уровне около 40%. Доля эффективного времени обучения превышает 90%, а эффективность линейного масштабирования обучения достигает 95%.
Благодаря нативной поддержке FP8 кластер может полностью воспроизвести процесс обучения передовых больших моделей. Утилизация вычислительной мощности Flash Attention превышает 95%, а многие ключевые показатели достигли международного уровня.
Стоит отметить, что MTT S5000 на уровне кластерных коммуникаций использует оригинальную технологию ACE, которая выгружает сложные коммуникационные задачи с вычислительных ядер, значительно повышая коэффициент использования вычислительной мощности модели (MFU).
Тесты показывают, что при масштабировании MTT S5000 с 64 до 1024 карт эффективность линейного масштабирования системы сохраняется выше 90%, а скорость обучения почти синхронно удваивается с увеличением вычислительной мощности.

MTT S5000 также отлично показывает себя в сценариях логического вывода. Например, в декабре 2025 года Moore Threads совместно с Silicon Flow завершили глубокую адаптацию и тестирование производительности полной версии DeepSeek-V3 671B на MTT S5000.
Фактические измерения показали, что пропускная способность одной карты на этапе Prefill превышает 4000 токенов/с, а на этапе Decode — более 1000 токенов/с, что является рекордом для китайских GPU в задачах логического вывода.

0 комментариев