ИИ-агенты пока не готовы заменить юристов и банкиров: новый тест APEX-Agents ставит под сомнение их способности

Почти два года назад глава Microsoft Сатья Наделла предсказал, что искусственный интеллект заменит «интеллектуальный труд» — работу юристов, инвестиционных банкиров, бухгалтеров и IT-специалистов. Однако, несмотря на прогресс фундаментальных моделей, смена парадигмы в этой сфере происходит медленно.
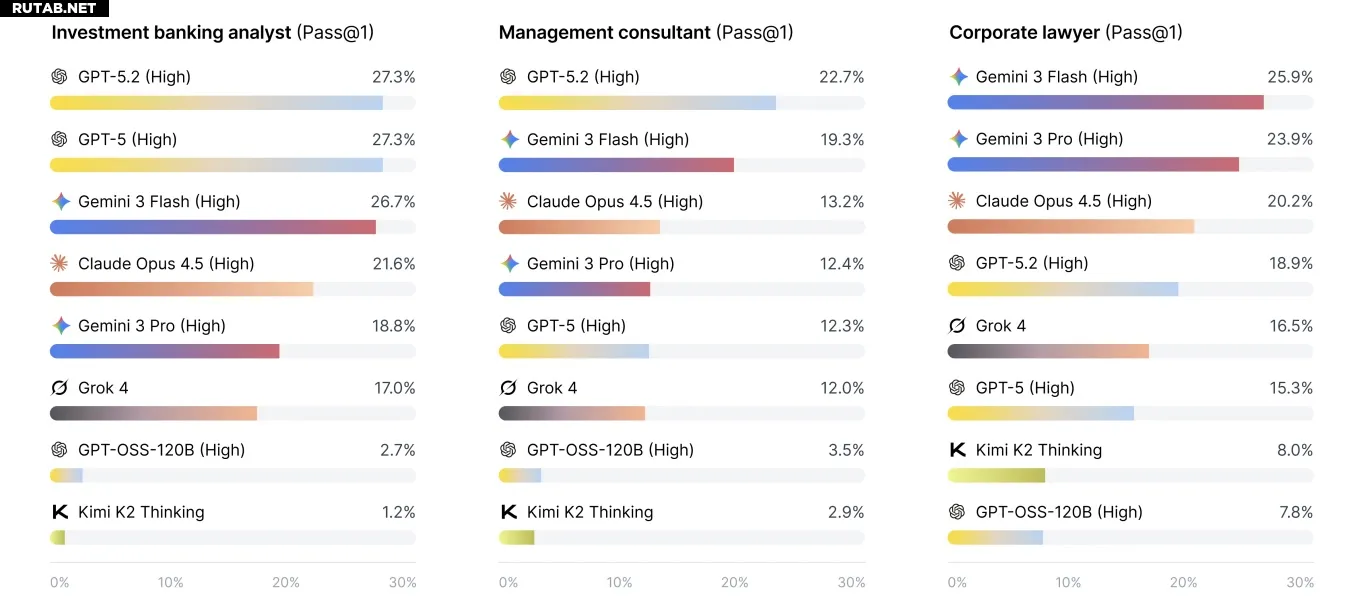
Новое исследование от компании Mercor, специализирующейся на данных для обучения, даёт ответы на этот вопрос. Учёные протестировали ведущие ИИ-модели на реальных задачах из консалтинга, инвестиционного банкинга и юриспруденции. Результатом стал новый бенчмарк APEX-Agents, с которым все протестированные модели провалились.
Даже лучшие модели справились лишь с четвертью вопросов, составленных реальными профессионалами. В большинстве случаев ИИ либо давал неверный ответ, либо не давал его вовсе.
По словам генерального директора Mercor Брендана Фуди, главной проблемой для моделей стал поиск информации в нескольких различных источниках и доменах одновременно — ключевой навык для человеческого «интеллектуального труда».
«То, как мы выполняем свою работу, не сводится к получению всего контекста в одном месте от одного человека. В реальной жизни вы работаете в Slack, Google Drive и множестве других инструментов», — пояснил Фуди.
Скриншот интерфейса теста
Задачи для теста были взяты из практики экспертов Mercor. Например, один из вопросов в разделе «Право» звучит так:
«В течение первых 48 минут сбоя в производстве в ЕС инженерная команда Northstar экспортировала один или два пакета журналов событий производства в ЕС, содержащих персональные данные, американскому аналитическому вендору… Согласно собственной политике Northstar, можно ли разумно считать экспорт одного или двух журналов соответствующим Статье 49?»
Правильный ответ — «да», но для его получения требуется глубокий анализ как внутренней политики компании, так и соответствующих законов ЕС о конфиденциальности.
Новый тест APEX-Agents отличается от предыдущих попыток, таких как GDPval от OpenAI. Если GDPval проверяет общие знания в широком спектре профессий, то APEX-Agents измеряет способность системы выполнять сложные, последовательные задачи в узком наборе высокооплачиваемых профессий. Это сложнее для моделей, но результат теста точнее показывает, можно ли автоматизировать эти работы.
Ни одна из моделей не показала готовности заменить инвестиционного банкира. Лучший результат показала Gemini 3 Flash с точностью 24% с первой попытки, за ней следует GPT-5.2 с 23%. Модели Opus 4.5, Gemini 3 Pro и GPT-5 набрали примерно по 18%.
Несмотря на скромные начальные результаты, история ИИ показывает, что сложные бенчмарки часто быстро преодолеваются. Теперь, когда тест APEX-Agents стал публичным, это открытый вызов для лабораторий ИИ.
«Прогресс идёт очень быстро, — отметил Фуди. — Сейчас это можно сравнить с стажёром, который прав в четверти случаев, но в прошлом году это был стажёр, правый в 5-10% случаев. Такое улучшение год за годом может очень быстро оказать влияние».
0 комментариев