DeepSeek представила модель с разреженным вниманием, снижающую затраты на API вдвое
Исследователи компании DeepSeek в понедельник представили новую экспериментальную модель под названием V3.2-exp, которая предназначена для значительного снижения затрат на вывод при работе с длинными контекстами. DeepSeek анонсировала модель в публикации на Hugging Face, также разместив связанную научную работу на GitHub.

Ключевой особенностью новой модели является система DeepSeek Sparse Attention, сложная архитектура которой подробно описана на представленной ниже схеме. По сути, система использует модуль под названием «lightning indexer» для определения приоритетных фрагментов из контекстного окна. После этого отдельная система под названием «fine-grained token selection system» выбирает конкретные токены из этих фрагментов для загрузки в ограниченное окно внимания модуля. В совокупности это позволяет моделям с разреженным вниманием работать с длинными контекстами при сравнительно небольшой нагрузке на серверы.
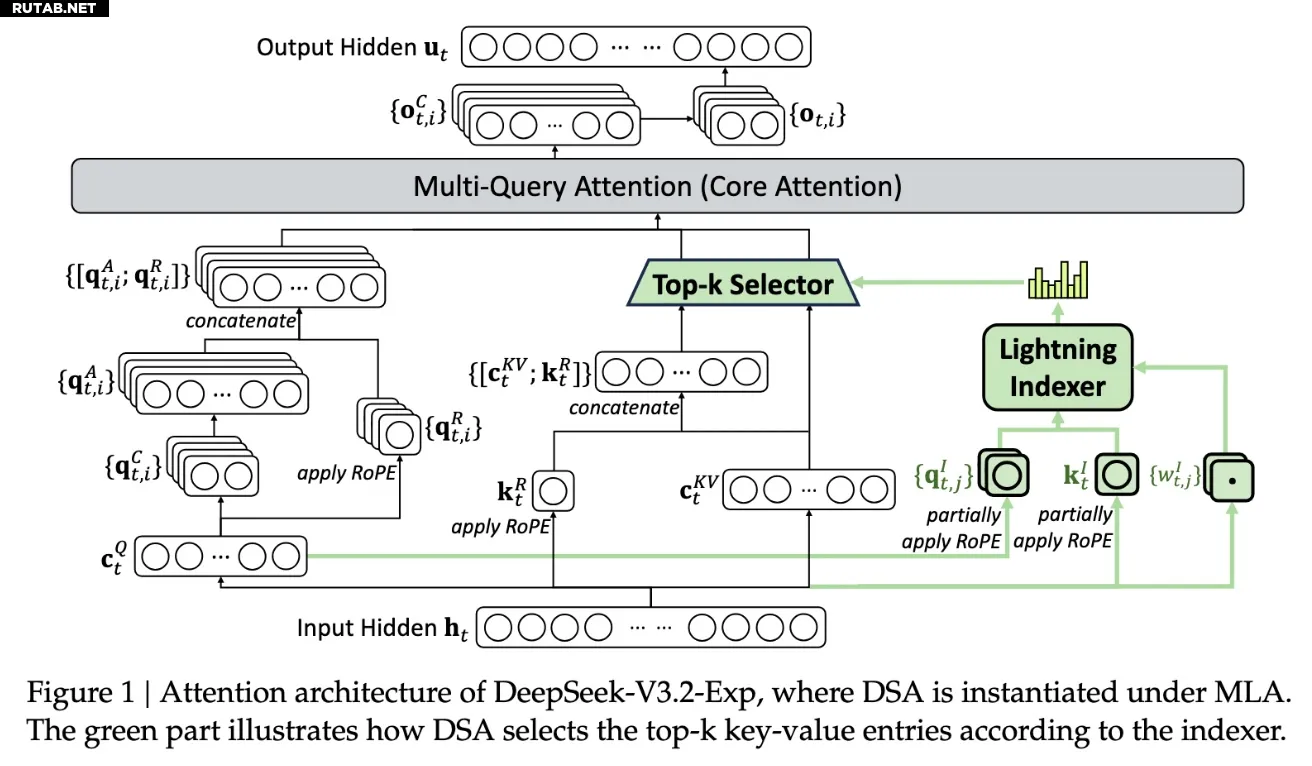
Схема архитектуры
Для операций с длинным контекстом преимущества системы весьма значительны. Предварительное тестирование DeepSeek показало, что стоимость простого API-вызова может быть снижена до половины в ситуациях с длинным контекстом. Для построения более надежной оценки потребуются дополнительные испытания, но поскольку модель имеет открытые веса и свободно доступна на Hugging Face, вскоре появятся независимые тесты, которые смогут оценить заявления, сделанные в статье.
Новая модель DeepSeek — это одно из последних достижений в решении проблемы затрат на вывод, то есть серверных расходов на эксплуатацию предварительно обученной ИИ-модели, в отличие от затрат на её обучение. В случае с DeepSeek исследователи искали способы повышения эффективности фундаментальной трансформерной архитектуры — и обнаружили, что возможны значительные улучшения.
Базирующаяся в Китае компания DeepSeek стала необычной фигурой в буме искусственного интеллекта, особенно для тех, кто рассматривает ИИ-исследования как национальное соперничество между США и Китаем. В начале года компания произвела фурор своей моделью R1, обученной в основном с помощью обучения с подкреплением при значительно более низких затратах, чем у американских конкурентов. Однако эта модель не вызвала тотальной революции в обучении ИИ, как предсказывали некоторые, и с тех пор компания отошла от всеобщего внимания.
Новый подход с «разреженным вниманием» вряд ли вызовет такой же ажиотаж, как R1, — но он всё же может научить американских поставщиков некоторым необходимым приёмам для поддержания низких затрат на вывод.
0 комментариев