NVIDIA Blackwell Ultra установила рекорды в новом тесте MLPerf Inference v5.1
Производительность систем логического вывода (вывода) критически важна, поскольку напрямую влияет на экономику «фабрик искусственного интеллекта». Чем выше пропускная способность инфраструктуры такой фабрики, тем больше токенов она может производить на высокой скорости — это увеличивает доходы, снижает совокупную стоимость владения (TCO) и повышает общую производительность системы. Менее чем через полгода после дебюта на NVIDIA GTC, масштабируемая на уровне стоек система NVIDIA GB300 NVL72 — на базе архитектуры NVIDIA Blackwell Ultra — установила рекорды в новом тесте логического вывода в MLPerf Inference v5.1, обеспечив до 1,4-кратного увеличения пропускной способности вывода DeepSeek-R1 по сравнению с системами на базе NVIDIA Blackwell GB200 NVL72.
Blackwell Ultra развивает успех архитектуры Blackwell: она предлагает в 1,5 раза больше вычислительной мощности ИИ в формате NVFP4 и в 2 раза больше ускорения для слоёв внимания (attention-layer), а также до 288 ГБ памяти HBM3e на каждый GPU. Платформа NVIDIA также установила рекорды производительности на всех новых тестах для центров обработки данных, добавленных в набор MLPerf Inference v5.1 — включая DeepSeek-R1, Llama 3.1 405B Interactive, Llama 3.1 8B и Whisper — продолжая удерживать рекорды на каждый GPU на всех тестах MLPerf для ЦОД.

Комплексный подход
Полноценное совместное проектирование (full-stack co-design) играет важную роль в достижении этих новейших результатов. Blackwell и Blackwell Ultra включают аппаратное ускорение для формата данных NVFP4 — разработанного NVIDIA 4-битного формата с плавающей запятой, который обеспечивает лучшую точность по сравнению с другими форматами FP4, а также сравнимую точность с форматами более высокой точности.
Программное обеспечение NVIDIA TensorRT Model Optimizer выполнило квантизацию моделей DeepSeek-R1, Llama 3.1 405B, Llama 2 70B и Llama 3.1 8B в формат NVFP4. В сочетании с открытой библиотекой NVIDIA TensorRT-LLM эта оптимизация позволила Blackwell и Blackwell Ultra обеспечить более высокую производительность при соблюдении строгих требований к точности в представленных результатах.
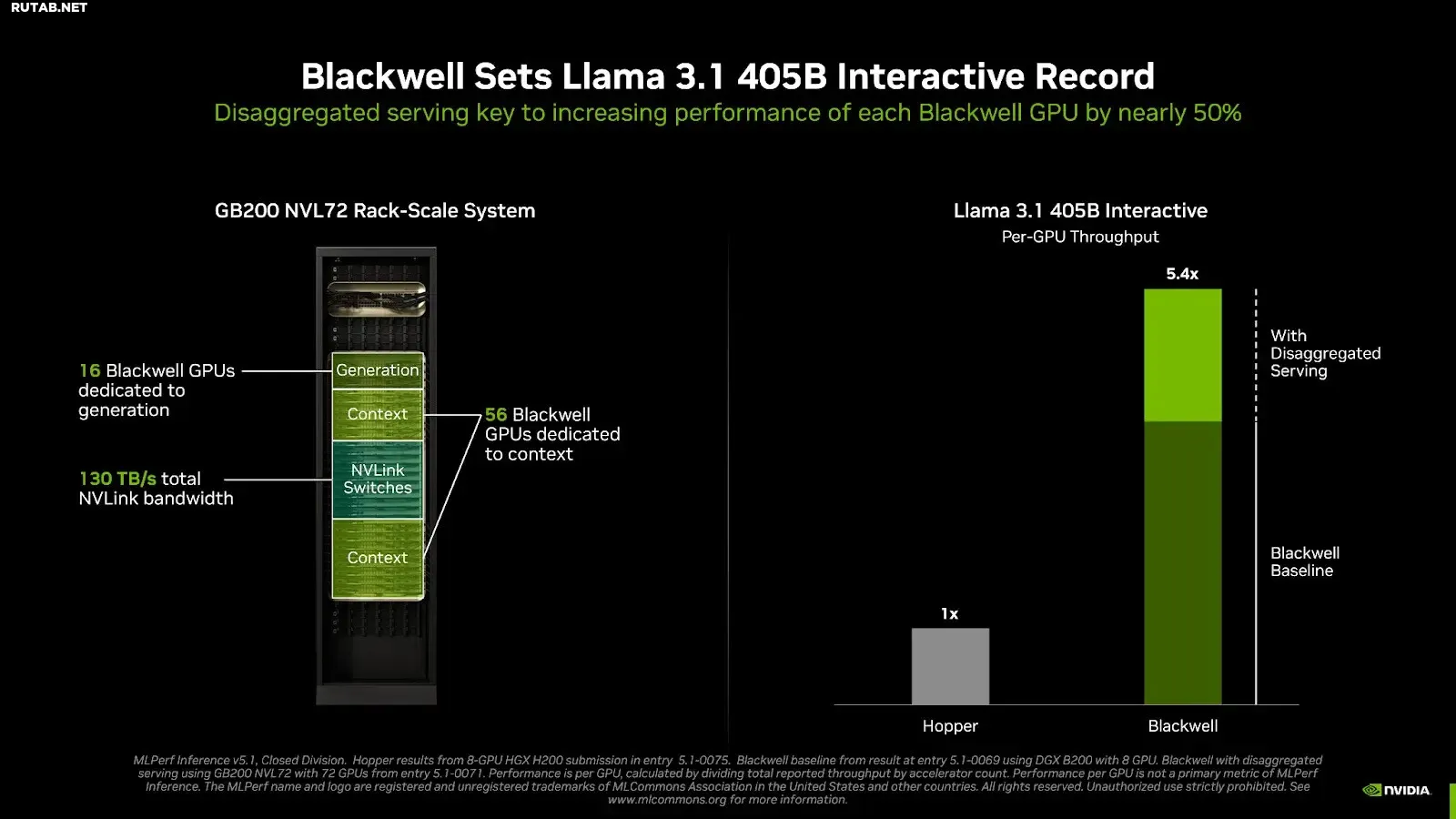
Логический вывод больших языковых моделей состоит из двух рабочих нагрузок с различными характеристиками выполнения: 1) контекст для обработки пользовательского ввода с целью генерации первого выходного токена и 2) генерация для производства всех последующих выходных токенов.
Техника под названием disaggregated serving разделяет задачи контекста и генерации, так что каждая часть может быть оптимизирована независимо для достижения наилучшей общей пропускной способности. Эта техника была ключевой для установления рекордной производительности в тесте Llama 3.1 405B Interactive, позволив обеспечить почти 50%-ное увеличение производительности на GPU в системах GB200 NVL72 по сравнению с каждым GPU Blackwell в сервере NVIDIA DGX B200, работающем с традиционным обслуживанием.
NVIDIA также впервые представила результаты в этом раунде с использованием фреймворка логического вывода NVIDIA Dynamo.
Партнёры NVIDIA — включая облачных провайдеров и производителей серверов — представили отличные результаты с использованием платформ NVIDIA Blackwell и/или Hopper. Среди этих партнёров: Azure, Broadcom, Cisco, CoreWeave, Dell Technologies, Giga Computing, HPE, Lambda, Lenovo, Nebius, Oracle, Quanta Cloud Technology, Supermicro и Университет Флориды.
Лидирующая на рынке производительность логического вывода на платформе NVIDIA AI доступна у крупнейших облачных провайдеров и производителей серверов. Это означает более низкую совокупную стоимость владения и повышенную отдачу от инвестиций для организаций, развёртывающих сложные приложения ИИ.
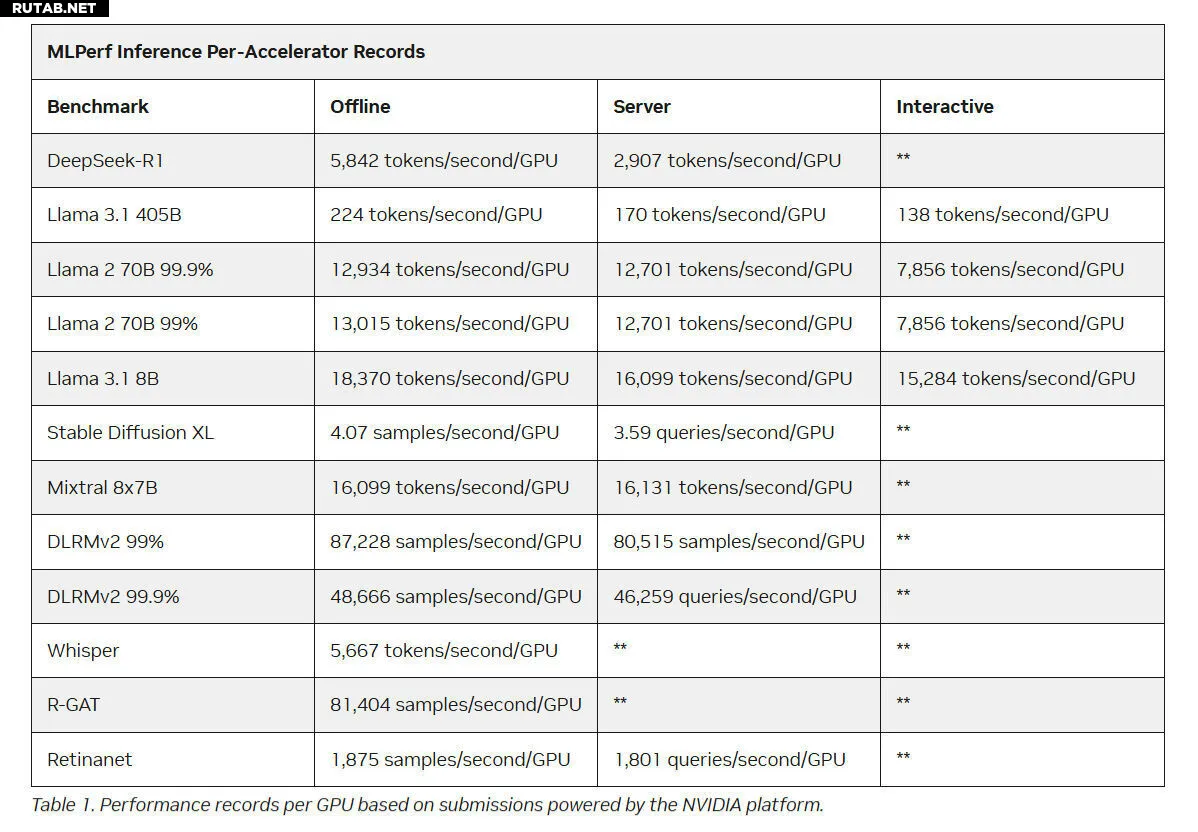
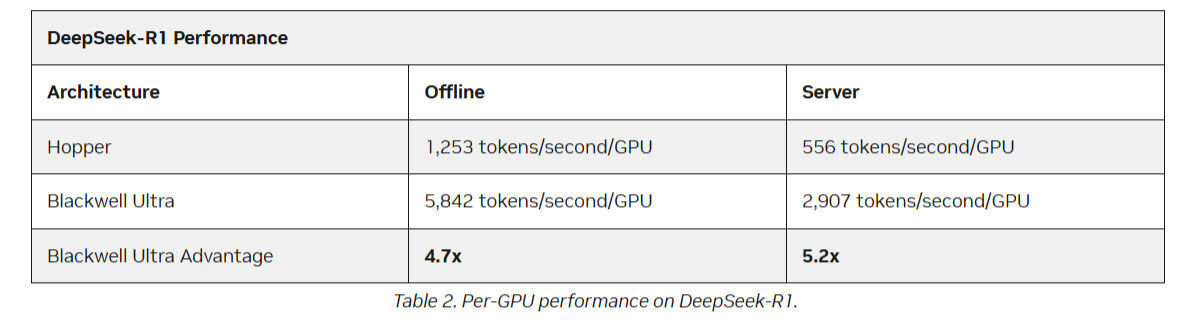
Источник: NVIDIA
ИИ: Впечатляющий прогресс NVIDIA в области специализированных AI-ускорителей продолжает задавать высокую планку для всей индустрии. Рекорды Blackwell Ultra демонстрируют, насколько важна оптимизация полного стека — от аппаратного обеспечения до программных библиотек — для достижения максимальной эффективности в эпоху больших языковых моделей.
0 комментариев