NVIDIA усиливает FP4 в своих AI-ускорителях: прирост энергоэффективности в 50 раз
NVIDIA продолжает доминировать на рынке AI-ускорителей. В то время как новый флагман Blackwell GB300 готовится к выходу в четвертом квартале 2025 года, а следующее поколение Rubin уже включает шесть разрабатываемых продуктов, происходит интересное расхождение в подходах к вычислениям между NVIDIA и китайскими производителями.
Китайские компании, включая Huawei Ascend, Moore Threads, Lichen Technology, VeriSilicon и Hygon, объединяются вокруг стандарта UE8M0 FP8, который был анонсирован вместе с выходом модели Deepseek 3.1. Этот стандарт обещает повышение производительности в 2-3 раза по сравнению с предыдущими FP16+INT8 решениями, снижает нагрузку на видеопамять и энергопотребление.
NVIDIA же в архитектуре Blackwell делает ставку на собственный стандарт NVFP4 (а также поддерживает MXFP4). Хотя NVFP4 структурно похож на E2M1 FP4, он практически не теряет в точности.
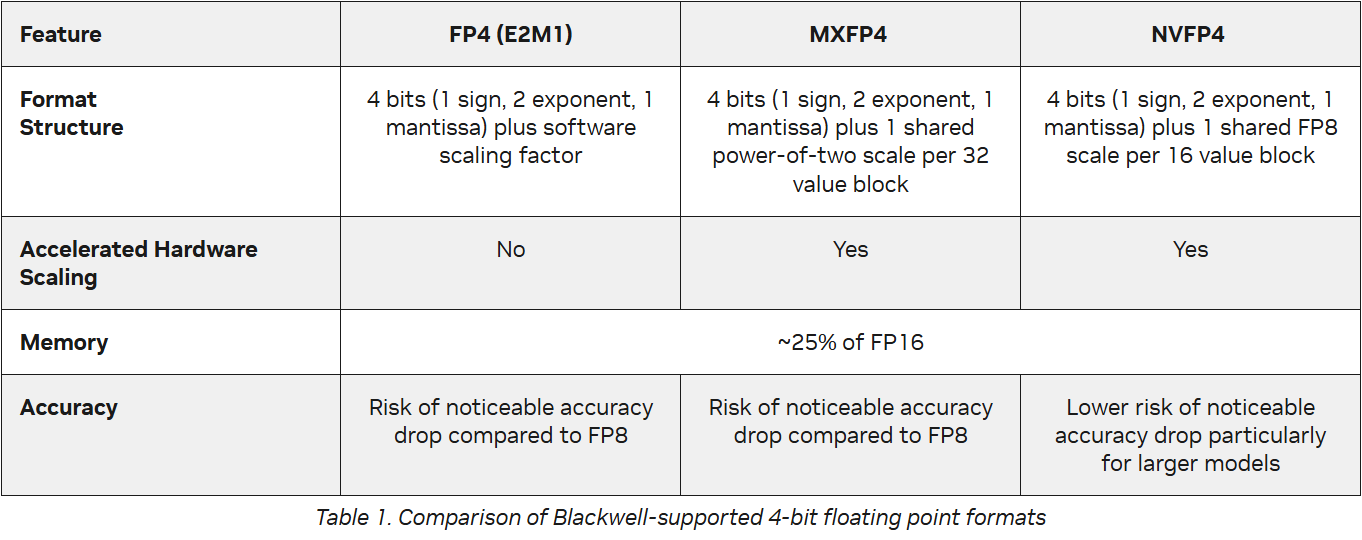
Преимущества NVFP4 впечатляют:
- Плотная производительность GB300 вырастает на 50%, достигая 15 PFlops
- Точность практически не уступает FP8: в модели DS 0528 отставание менее 1%, а в тесте AIME 2024 даже опережение на 2%
- Снижение использования памяти: в 3,5 раза по сравнению с FP16 и в 1,8 раза по сравнению с FP8
- Энергоэффективность: потребление на токен всего 0,2 Дж против 0,4 Дж у GB200 и 10 Дж у H100 — то есть в 50 раз лучше, чем у H100
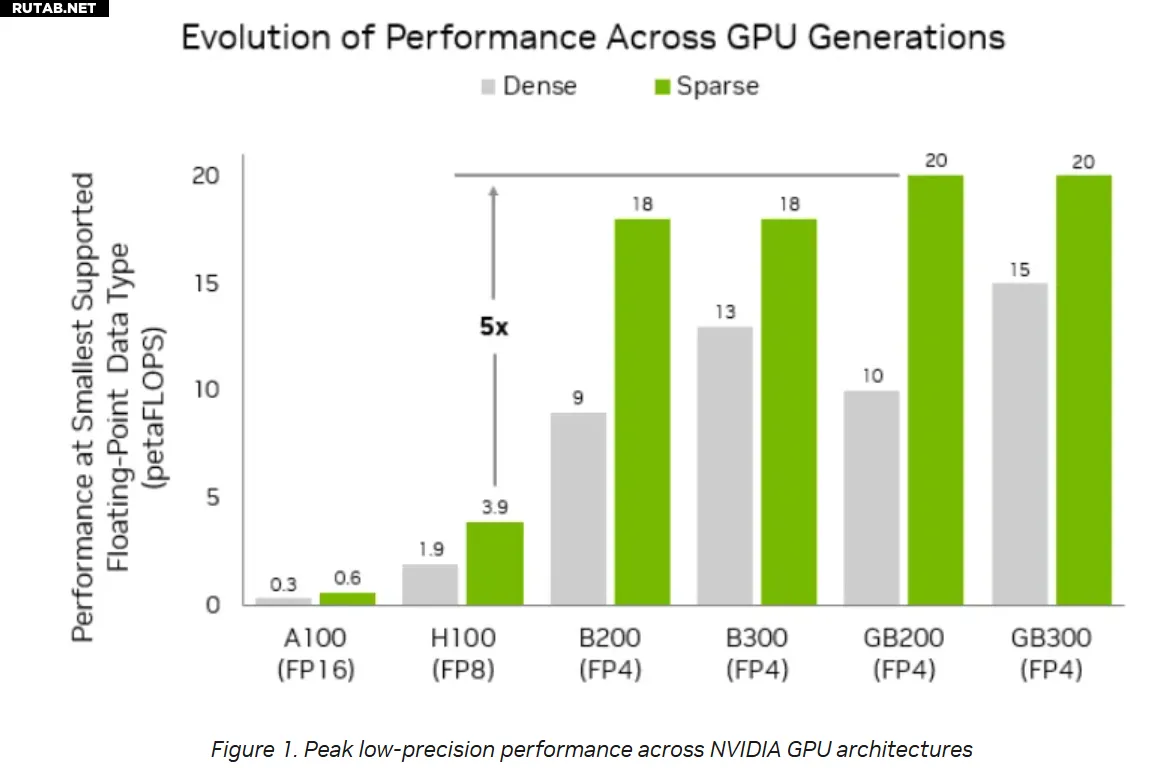
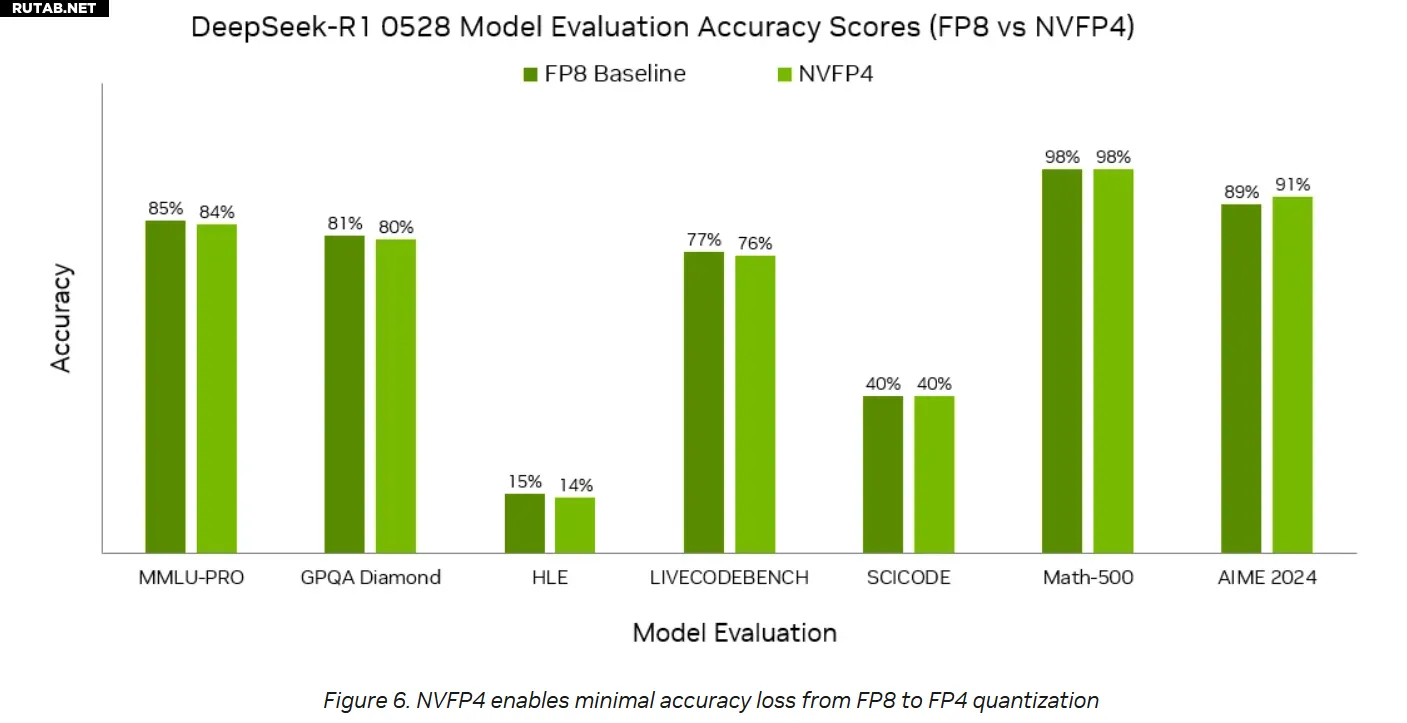
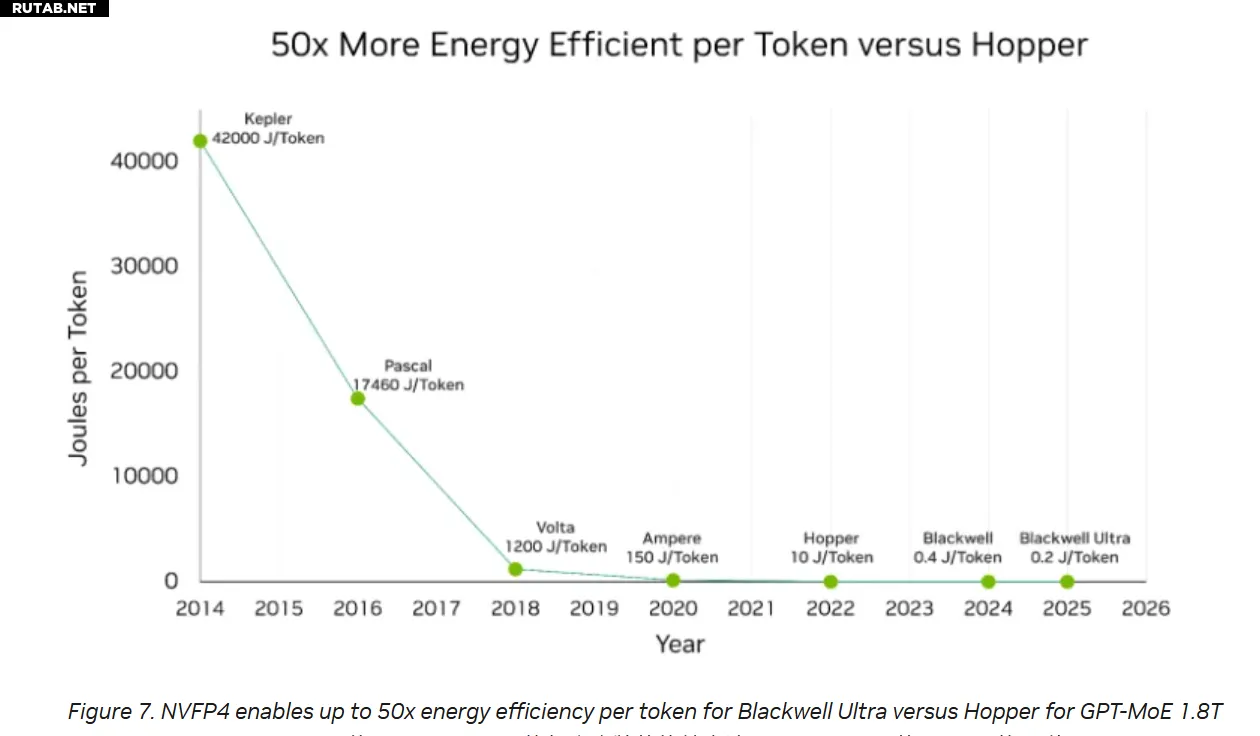
Объем HBM-памяти в GB300 увеличился до 288 ГБ (против 186 ГБ у GB200), а в системе NVL72 общая память достигает 40 ТБ, что достаточно для моделей с 300 миллиардами параметров.

ИИ: Интересно наблюдать, как на фоне геополитических ограничений формируются два параллельных технологических стека — западный во главе с NVIDIA и китайский с собственным стандартом UE8M0 FP8. При этом NVFP4 выглядит крайне убедительно с технической точки зрения, особенно в плане энергоэффективности. Вопрос в том, смогут ли китайские компании создать достаточно привлекательную экосистему вокруг своего стандарта.






0 комментариев