Глубокое погружение в архитектуру Nvidia Blackwell

NVIDIA Corporation (NASDAQ: NVDA) — американская компания, один из крупнейших разработчиков графических ускорителей и процессоров, а также наборов системной логики. На рынке продукция компании известна под такими торговыми марками как GeForce, nForce, Quadro, Tesla, ION и Tegra. Компания была основана в 1993 году. По состоянию на август 2006 года в корпорации насчитывалось более 8 тысяч сотрудников, работающих в 40 офисах по всему миру. Википедия
Читайте также:Nvidia: запуск ARM SoC для Windows в конце годаNVIDIA предоставила облачный доступ к Marvel RivalsКластер мощностью 100 кВт на базе Nvidia Hopper развертывается с 144 графическими процессорами H200Акции Quantum computing упали более чем на 40% после прогноза генерального директора NvidiaМини-суперкомпьютер Nvidia AI вызвал презрение у Раджи Кодури, Tiny Corp
Блэкуэлл, Блэквелл (англ. Blackwell) — английская фамилия. Википедия
Читайте также:Производство серверов Blackwell запущеноГрафический процессор Blackwell от Nvidia использует жидкий металл вместо термопастыСерия NVIDIA Blackwell GeForce RTX 50 открывает новый мир компьютерной графики ИИNVIDIA представила графический процессор GeForce RTX 50Утечка коробки MSI GeForce RTX 5080 Gaming Trio «Blackwell»

(Изображение предоставлено: Nvidia)

(Изображение предоставлено: Nvidia)
(Изображение предоставлено: Nvidia)

(Изображение предоставлено: Nvidia)

(Изображение предоставлено: Nvidia)
(Изображение предоставлено: Nvidia)
(Изображение предоставлено: Nvidia)
(Изображение предоставлено: Nvidia)
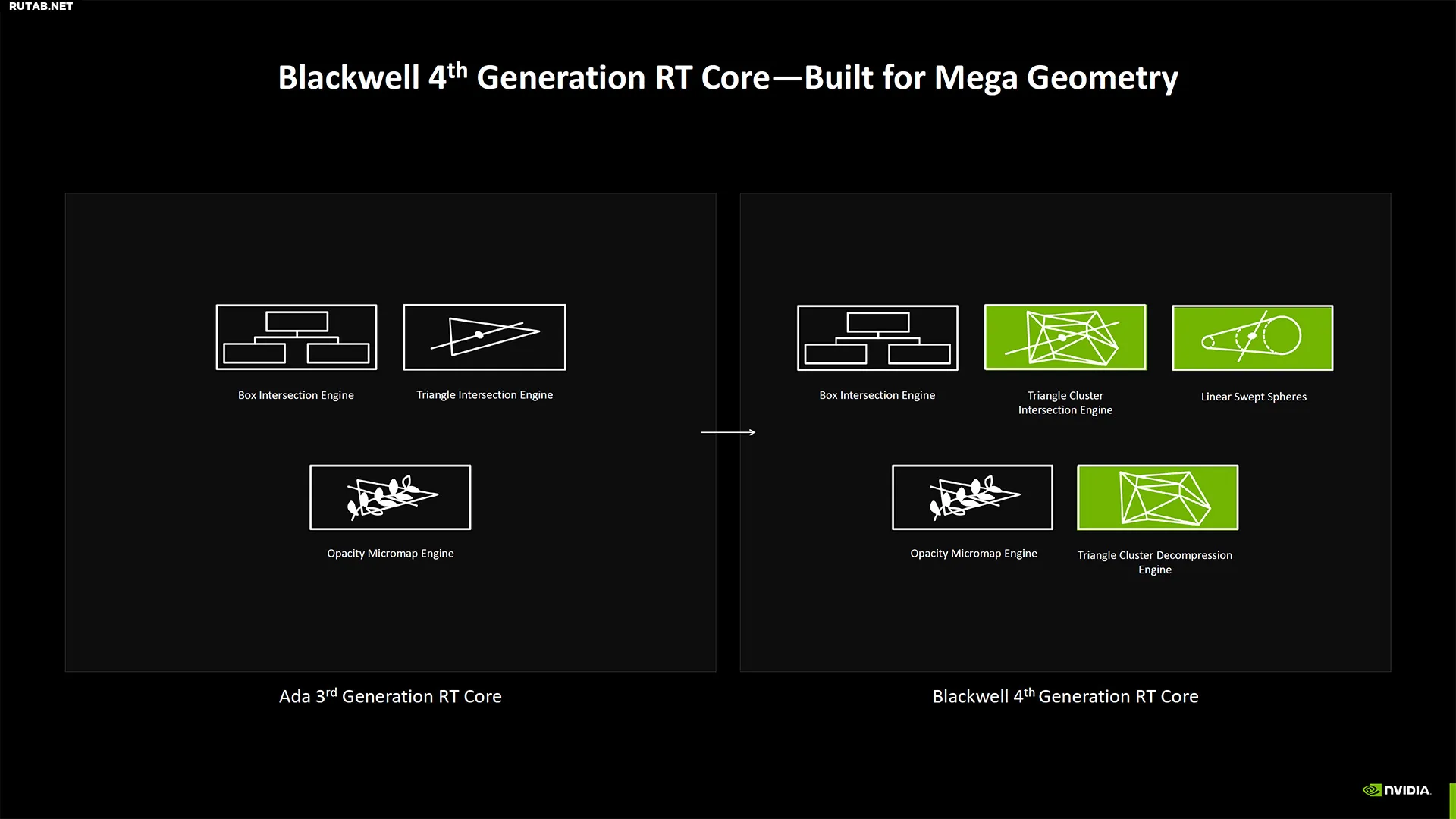
(Изображение предоставлено: Nvidia)
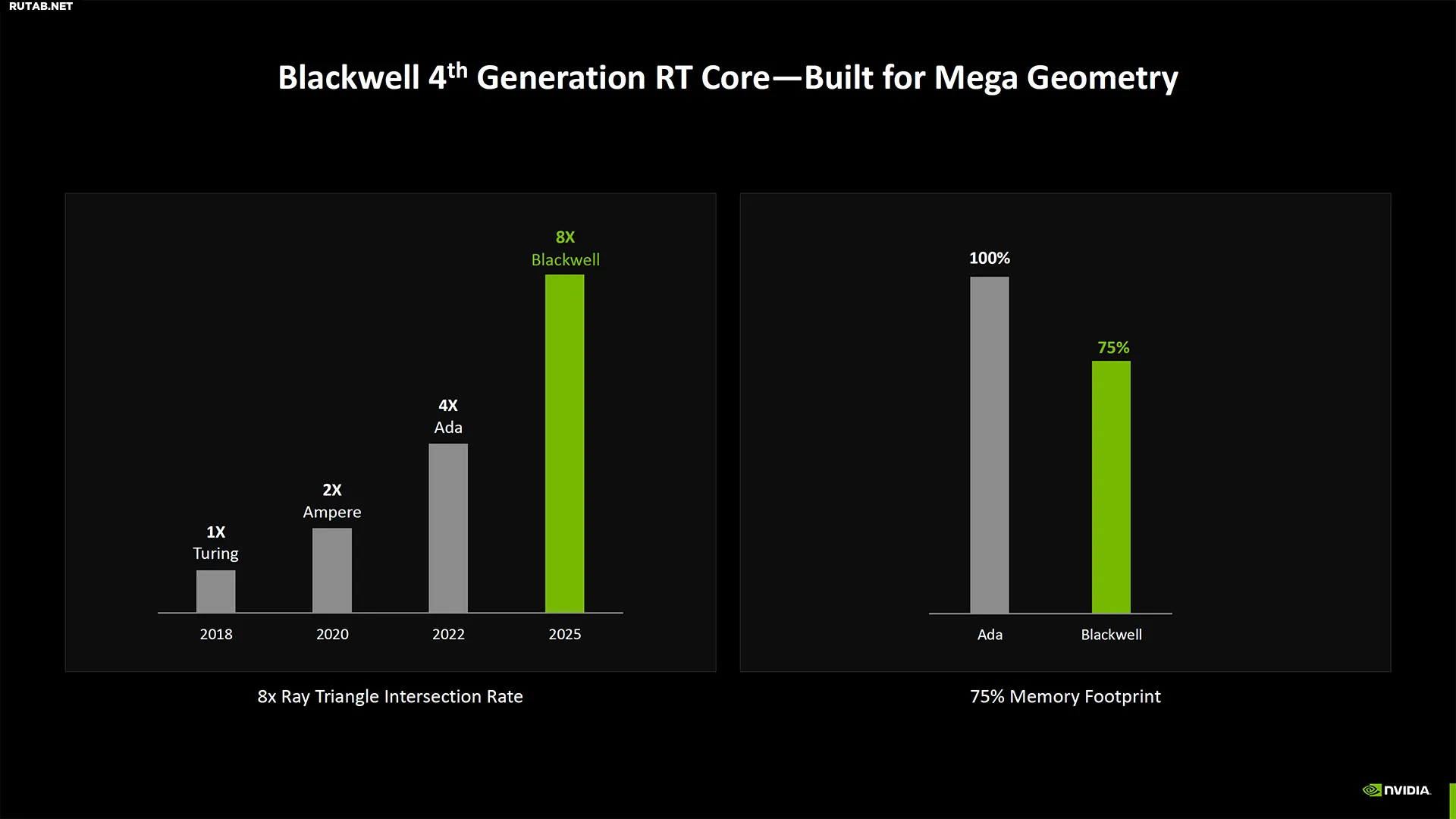
(Изображение предоставлено: Nvidia)
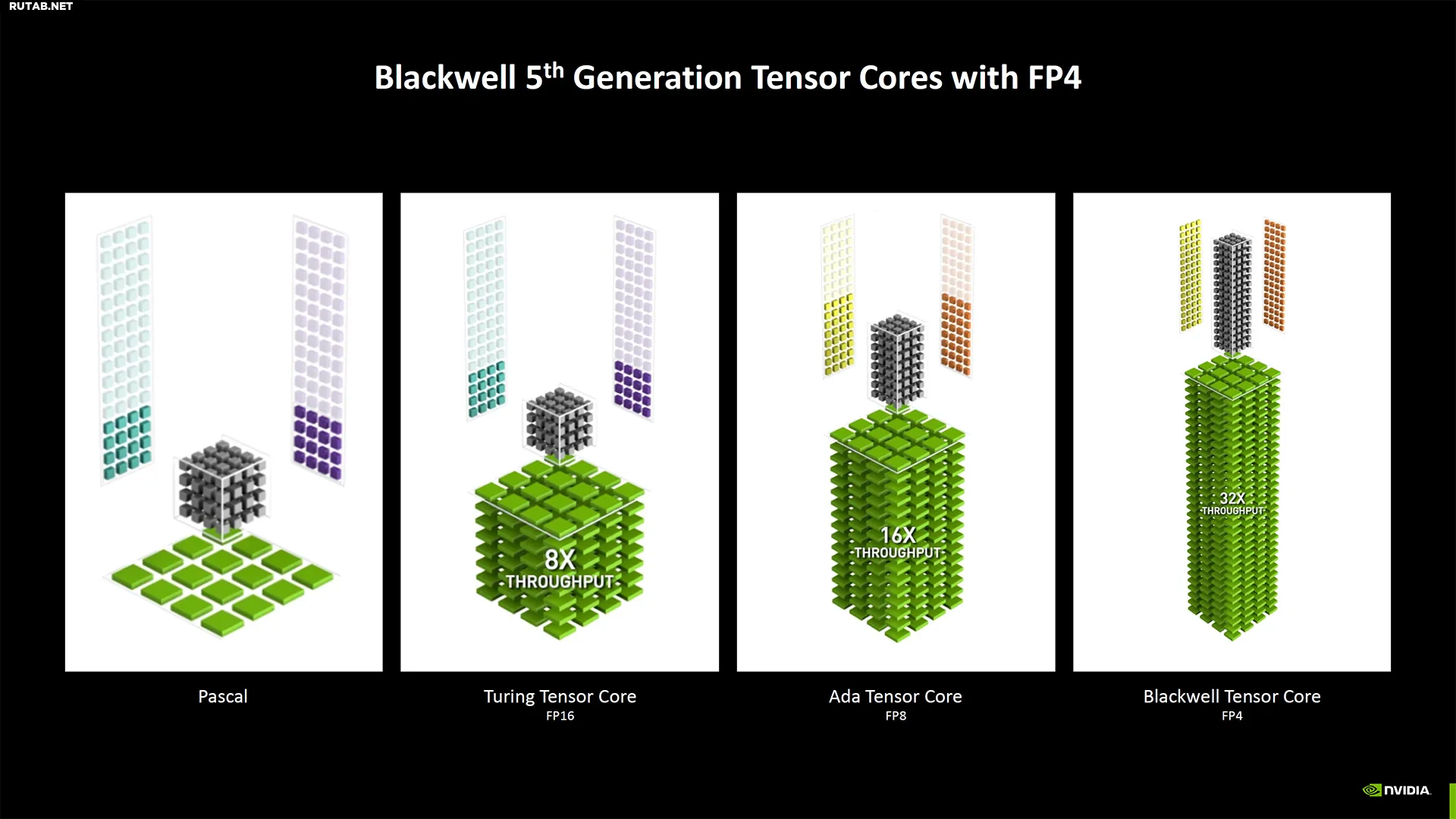
(Изображение предоставлено: Nvidia)
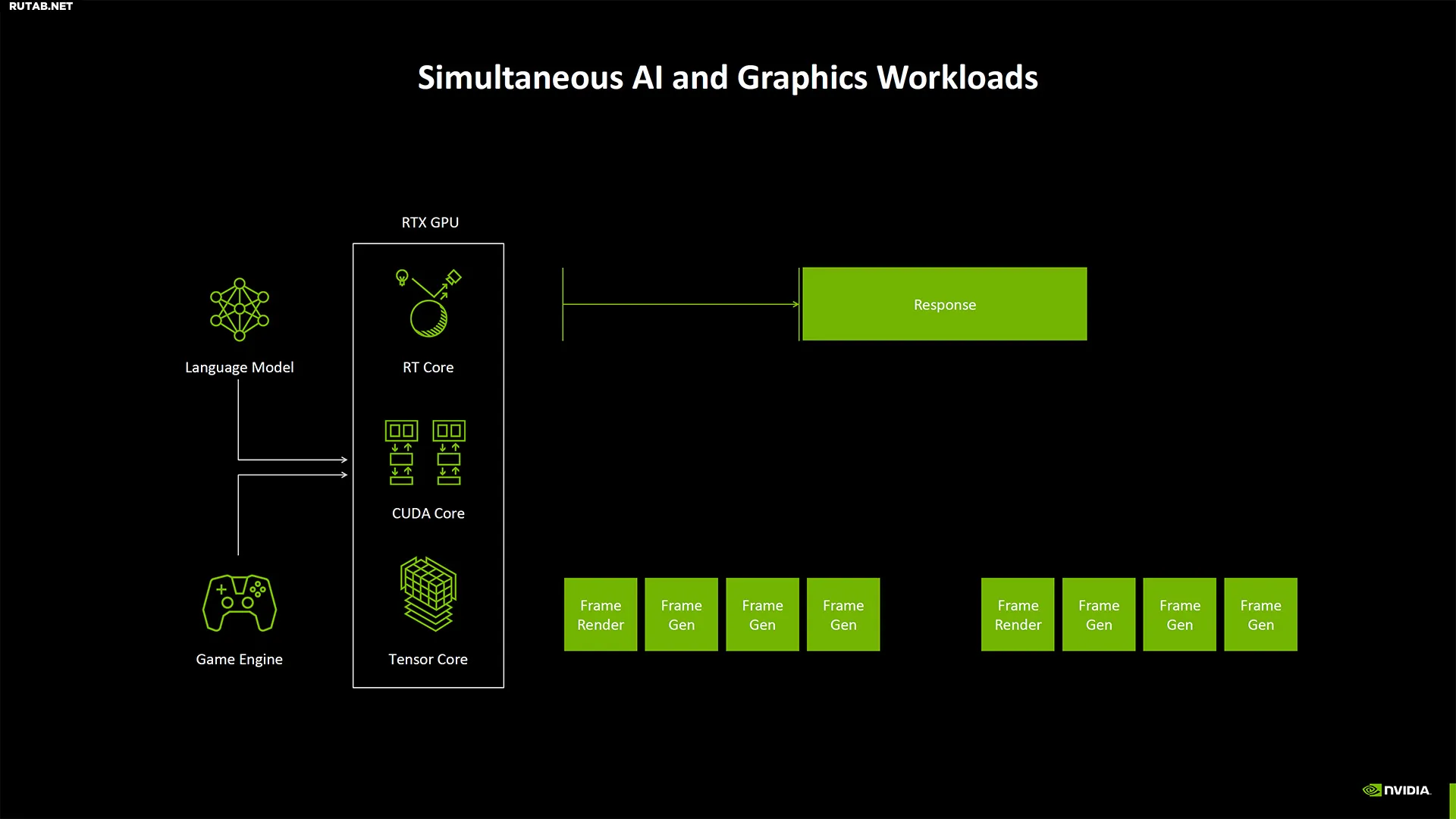
(Изображение предоставлено: Nvidia)
(Изображение предоставлено: Nvidia)

(Изображение предоставлено: Nvidia)

(Изображение предоставлено: Nvidia)
(Изображение предоставлено: Nvidia)
(Изображение предоставлено: Nvidia)
(Изображение предоставлено: Nvidia)

(Изображение предоставлено: Nvidia)
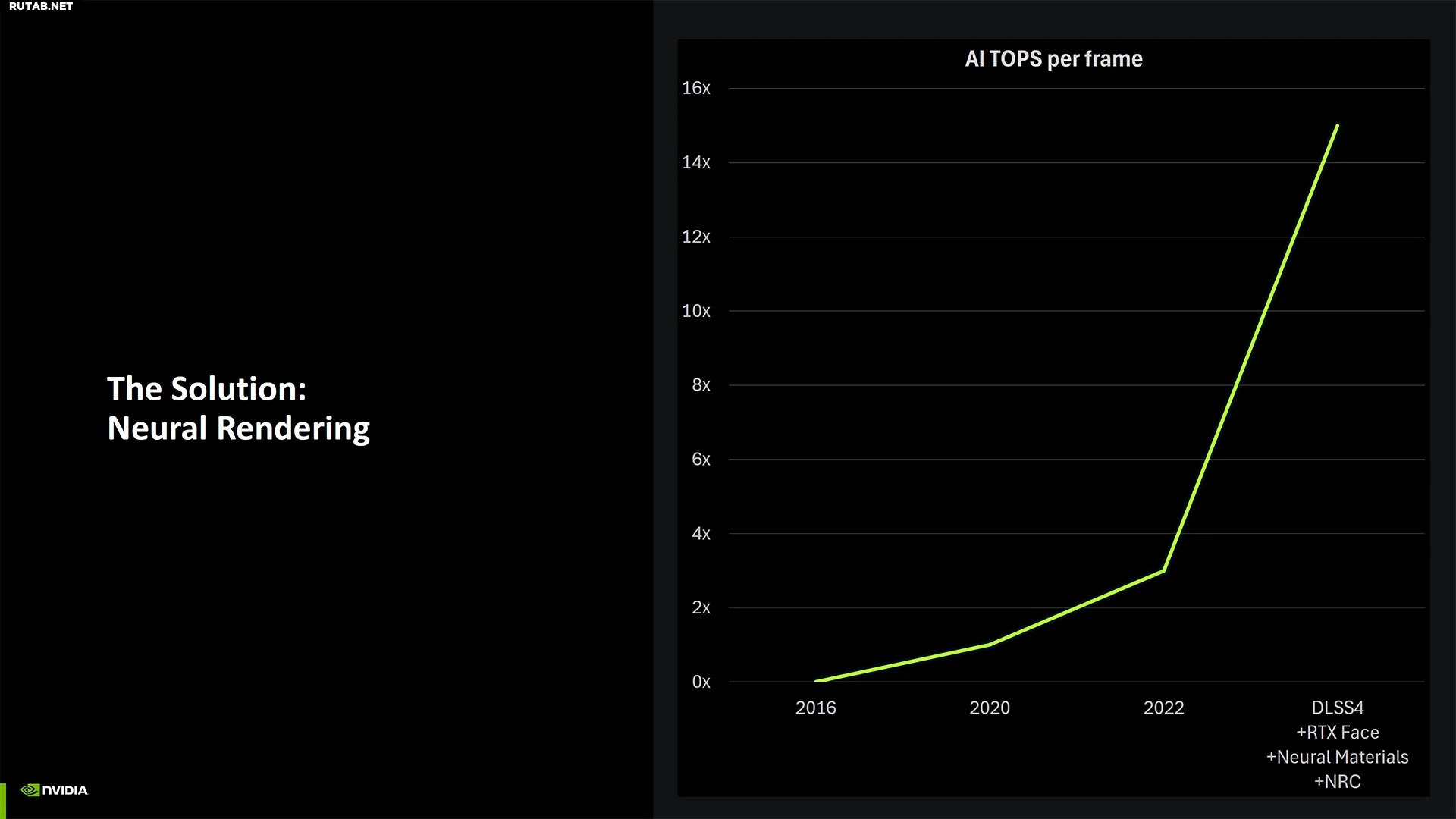
Вот полный набор слайдов для сессии архитектуры Blackwell. Он... не такой длинный, как вы могли ожидать. Nvidia не предоставила тонны подробностей о некоторых аспектах новой архитектуры, но с точки зрения высокого уровня, есть много вещей, которые, похоже, не сильно изменились по сравнению с архитектурой Ada Lovelace серии RTX 40. Большинство обновлений и улучшений, как правило, связаны с ИИ и различными технологиями нейронного рендеринга — мы более подробно рассмотрим их в отдельной статье.
Четвертый слайд показывает цели для Blackwell: оптимизация для новых нейронных рабочих нагрузок, сокращение объема памяти, новые возможности качества обслуживания и энергоэффективность. Все это звучит как хорошие вещи, но за пределами RTX 5090 с его значительно большим кристаллом GPU — 744 мм2 по сравнению с 608 мм2 у 4090 — многие обновления кажутся более постепенными.
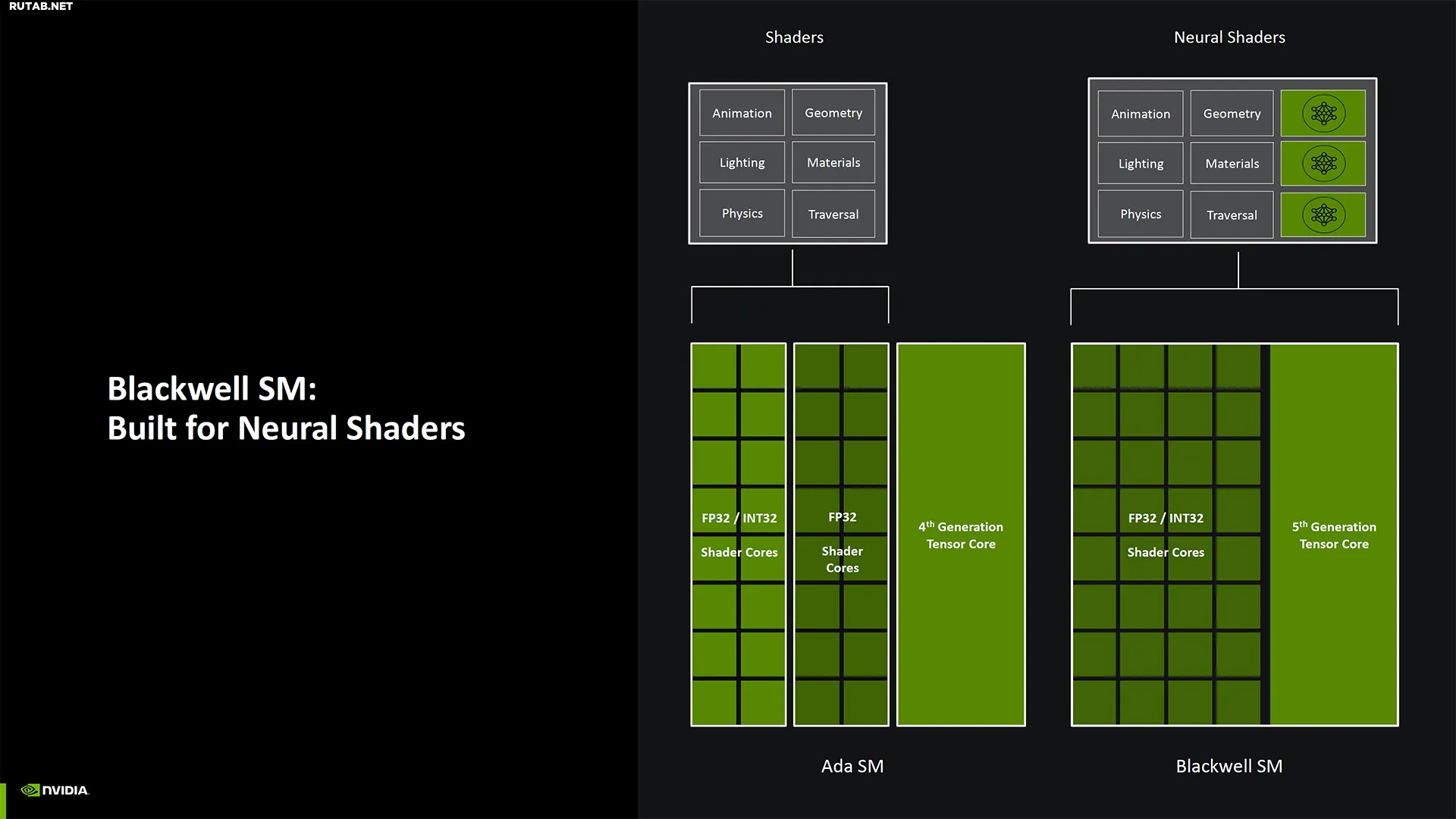
Это не значит, что ничего не изменилось. Ядра RT 4-го поколения имеют вдвое большую скорость пересечения треугольников лучей, чем Ada. Они также созданы для Mega Geometry, что может помочь будущим играм Unreal Engine 5 работать лучше. Шейдеры GPU также улучшены для Neural Shaders, и есть некоторые другие новые дополнения.
 Графический процессор (англ. graphics processing unit, GPU) — отдельное устройство персонального компьютера или игровой приставки, выполняющее графический рендеринг; в начале 2000-х годов графические процессоры стали массово применяться и в других устройствах: планшетные компьютеры, встраиваемые системы, цифровые телевизоры.
Современные графические процессоры очень эффективно обрабатывают и отображают компьютерную графику, благодаря специализированной конвейерной архитектуре они намного эффективнее в обработке графической информации, чем типичный центральный процессор.
Графический процессор в современных видеокартах (видеоадаптерах) применяется в качестве ускорителя трёхмерной графики. Википедия
Графический процессор (англ. graphics processing unit, GPU) — отдельное устройство персонального компьютера или игровой приставки, выполняющее графический рендеринг; в начале 2000-х годов графические процессоры стали массово применяться и в других устройствах: планшетные компьютеры, встраиваемые системы, цифровые телевизоры.
Современные графические процессоры очень эффективно обрабатывают и отображают компьютерную графику, благодаря специализированной конвейерной архитектуре они намного эффективнее в обработке графической информации, чем типичный центральный процессор.
Графический процессор в современных видеокартах (видеоадаптерах) применяется в качестве ускорителя трёхмерной графики. Википедия
Изображение: Nvidia
Возвращаясь к цифрам, если взять «до 4000 ИИ TOPS» (триллионов операций в секунду), то это масштабируется до 3400 TOPS на 5090 (3352, если быть точным). Затем вы обнаружите, что большая часть прироста происходит за счет собственной поддержки FP4. Так что если сравнивать сопоставимо, RTX 5090 имеет 1676 TFLOPS FP8, тогда как RTX 4090 предлагает 1321 TFLOPS FP8. Это всего лишь 27% прирост — все еще значительный, но не огромный.
Аналогичное масштабирование применяется и в других местах, например, в вычислении шейдеров FP32. 5090 обеспечивает до 104,8 TFLOPS FP32 по сравнению с 82,6 TFLOPS у RTX 4090. Опять же, это улучшение на 27%. Давайте посмотрим на это в перспективе. RTX 4090 обеспечил колоссальный прирост в 132% в TFLOPS GPU по сравнению с RTX 3090. Вот это обновление, от которого можно было в восторге!
5090, без сомнения, будет быстрее и лучше, чем 4090, но он не уничтожит полностью предыдущее поколение — по крайней мере, если вы не хотите учитывать Multi Frame Generation, от которого мы в восторге гораздо меньше, чем от маркетингового отдела Nvidia. Кстати, кристалл 5090 также на 22% больше, с на 21% большим количеством транзисторов, на том же узле процесса TSMC 4N.
Изображение: Nvidia
С точки зрения архитектуры, есть и другие примечательные изменения. С ростом использования ИИ и целочисленного использования для таких рабочих нагрузок, Nvidia сделала все ядра шейдеров в Blackwell полностью совместимыми с FP32/INT32. Так, в Ampere (RTX 30-й серии) Nvidia удвоила количество ядер CUDA FP32, но половина из них была только для FP32, в то время как другая половина могла делать FP32 и INT32 — INT32 часто используется для вычислений указателей памяти. Ada сохранила это, и теперь Blackwell снова делает все ядра CUDA однородными, просто с вдвое большим количеством, чем в Turing.
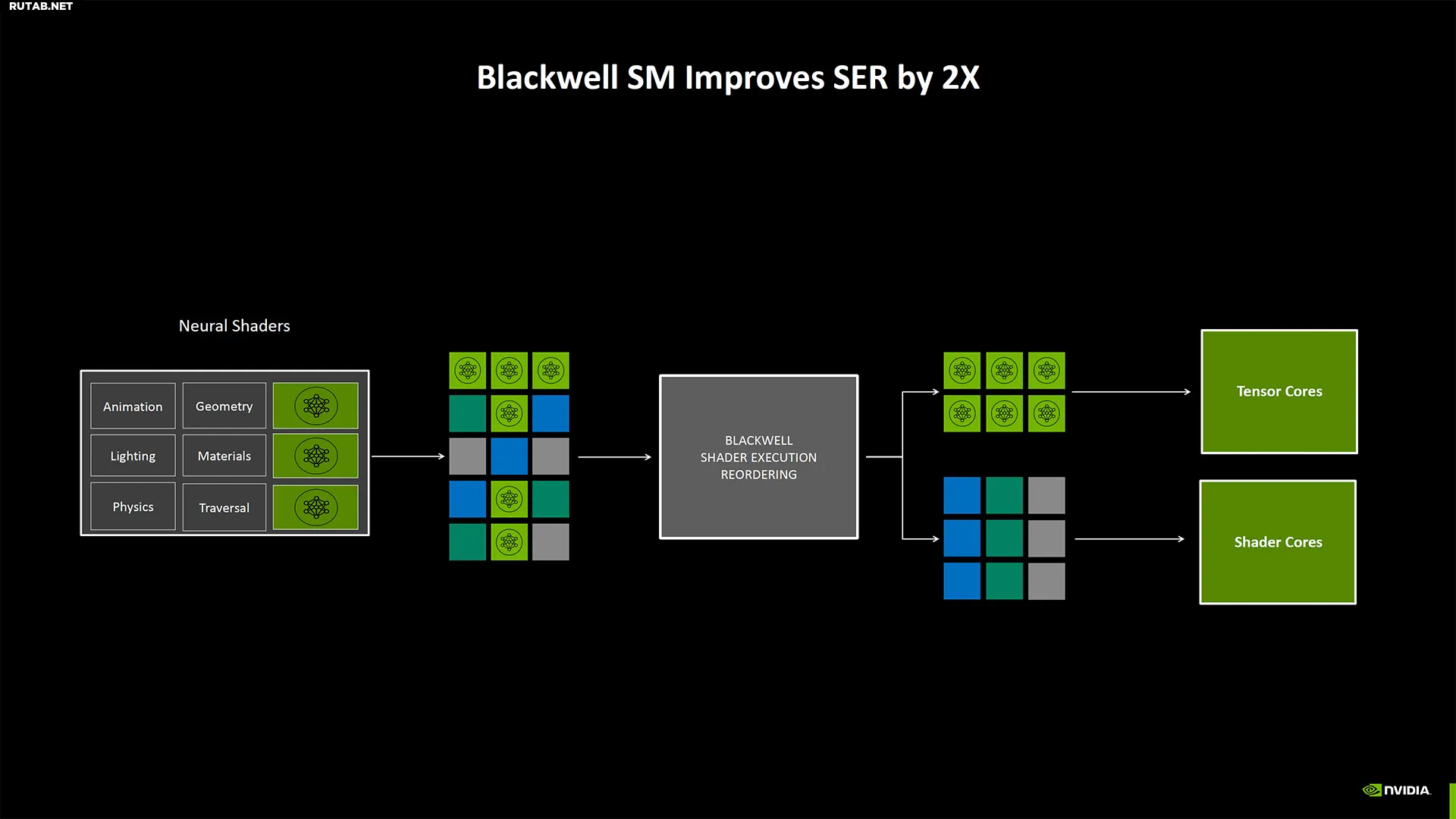
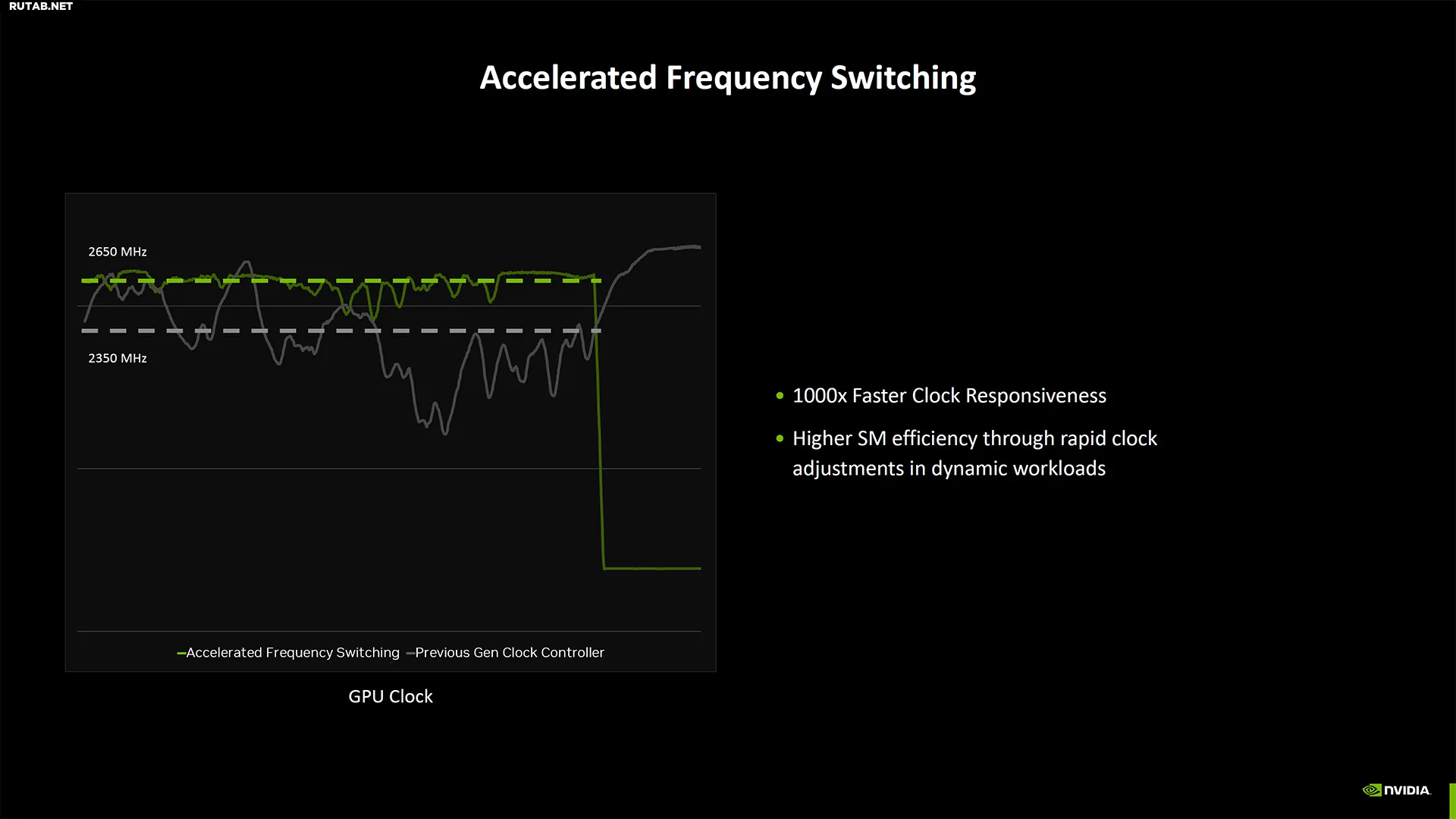
Nvidia также изменила некоторые вещи в конвейерах рендеринга шейдеров, чтобы обеспечить лучшее смешивание операций шейдеров и тензорных ядер. Она классифицирует это как нейронные шейдеры, и хотя кажется, что другие поколения RTX все еще могут выполнять эти рабочие нагрузки, они будут пропорционально медленнее, чем графические процессоры Blackwell. Похоже, это отчасти благодаря улучшениям SER (Shader Execution Reordering), который в два раза быстрее на Blackwell, чем на Ada.
Изображение: Nvidia
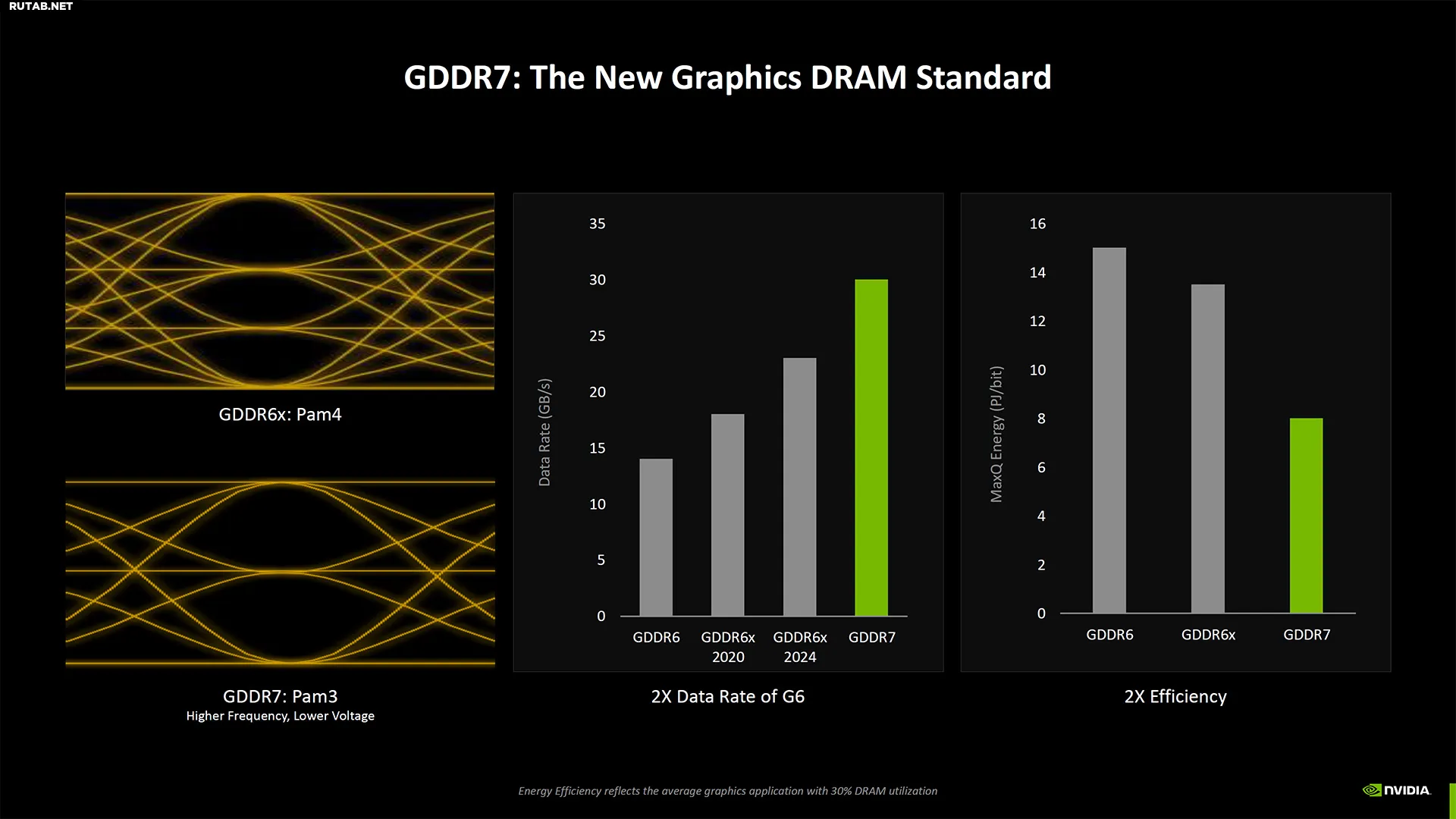
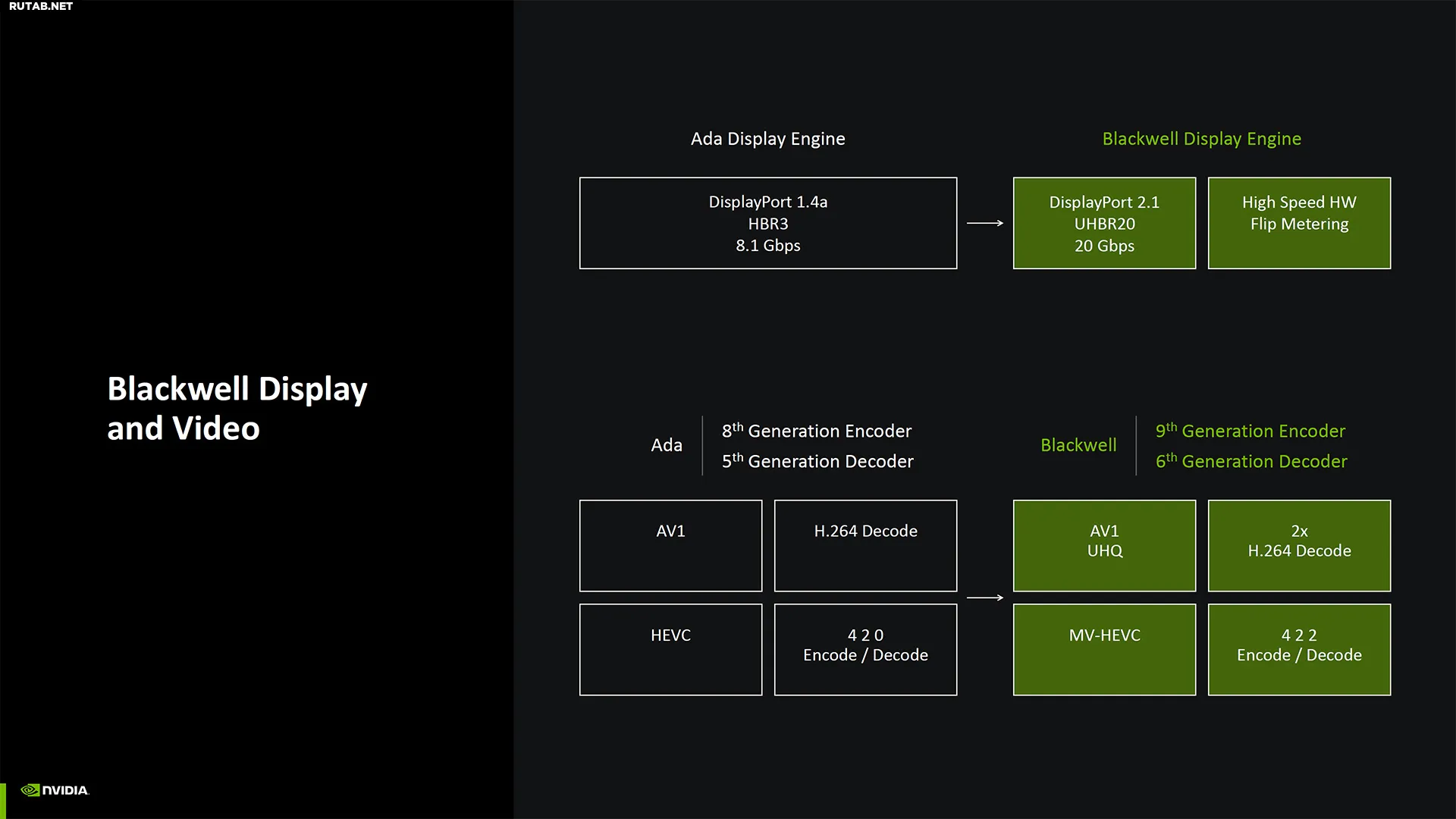
GDDR7 SDRAM (Graphics Double Data Rate 7 Synchronous Dynamic Random-Access Memory) — тип памяти графической карты (SGRAM), указанный в стандарте памяти JEDEC с высокой пропускной способностью, интерфейсом с "двойной скоростью передачи данных", предназначенным для использования в видеокартах, игровых консолях и высокопроизводительных вычислениях. Это тип GDDR SDRAM (графическая DDR SDRAM), преемник GDDR6(X/W). Википедия
Читайте также:Видеокарта NVIDIA RTX 5090 с 32 ГБ памяти GDDR7 «утекла» до CESNVIDIA GeForce RTX 5090 на базе кремния "GB202", 512-битная GDDR7, ASIC на фотоNVIDIA GeForce RTX 5080 выделяется памятью GDDR7 на 30 Гбит/с, другие модели остаются на 28 Гбит/сZotac случайно раскрыла видеокарты RTX 5000-й серииSamsung и SK hynix расскажут о GDDR7 со скоростью передачи данных до 42,5 ГТ/с
Большинство графических процессоров Blackwell RTX 50-й серии будут работать на GDDR7 со скоростью 28 Гбит/с, что вдвое быстрее оригинальных чипов GDDR6, но всего на 33% быстрее чипов GDDR6X со скоростью 21 Гбит/с, используемых во многих графических процессорах RTX 40-й серии с более высокими характеристиками. RTX 5080 получает ускорение до 30 Гбит/с GDDR7, что почти вдвое быстрее памяти 2080 Super со скоростью 15,5 Гбит/с.
Ширина интерфейса памяти не меняется, за исключением RTX 5090. Она получит огромный 512-битный интерфейс с 32 ГБ памяти GDDR7 на старте. Будущие чипы GDDR6 на 3 ГБ оставляют дверь открытой для потенциального обновления на 48 ГБ позже в цикле продукта или для профессиональных/центровых графических процессоров с объемом до 96 ГБ в режиме раскладушки, но Nvidia пока не будет официально комментировать или объявлять о таких вещах.
RTX 5080 по-прежнему имеет 256-битный интерфейс и 16 ГБ, поэтому, хотя он получает на 30% больше пропускной способности, чем RTX 4080 Super, емкость остается неизменной. То же самое касается 5070 Ti (против 5070 Ti Super) и 5070 (против 4070), за исключением того, что они получают на 33% больше пропускной способности — 28 Гбит/с против 21 Гбит/с.
Изображение: Nvidia
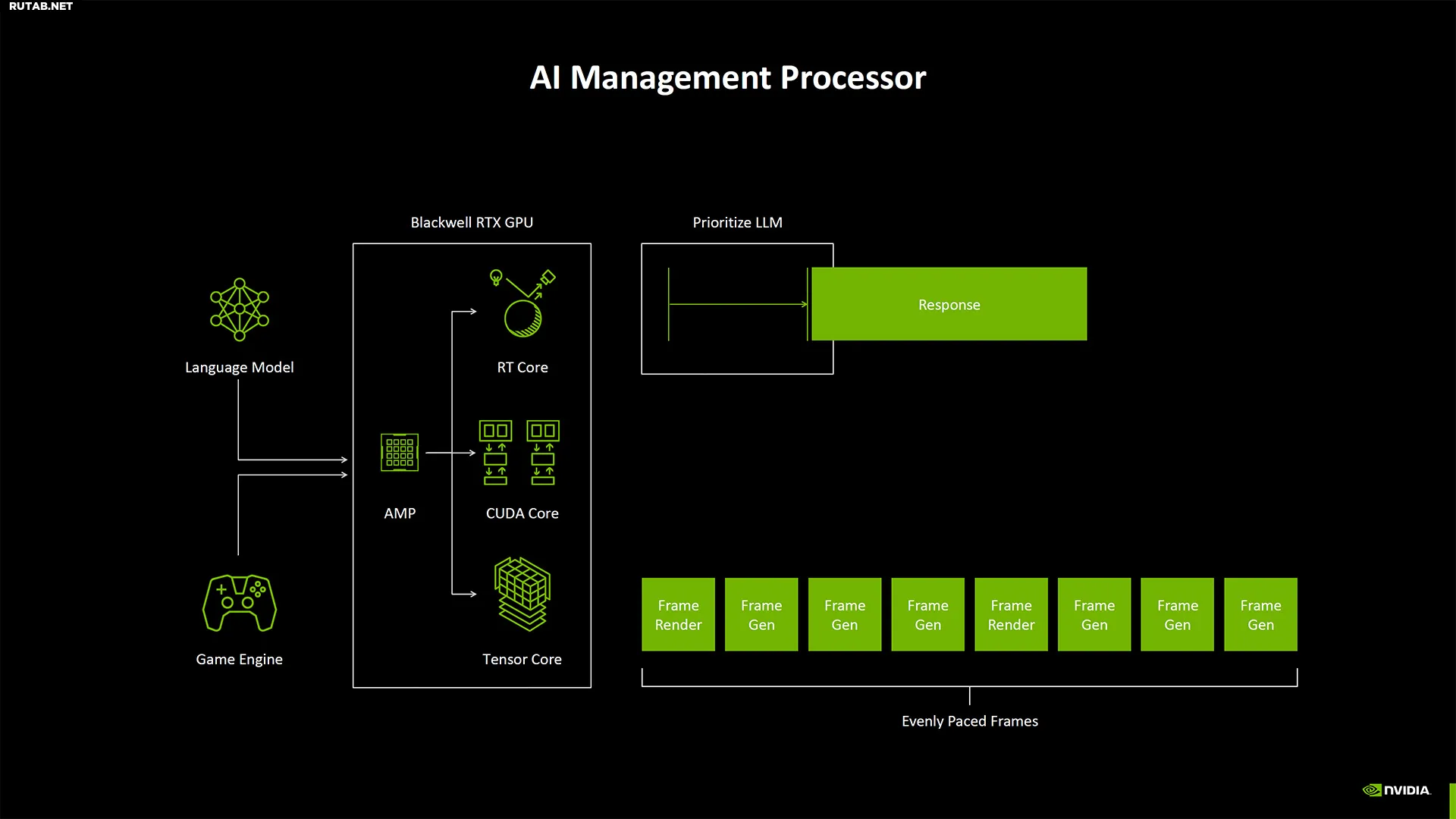
С ростом сложности рабочих нагрузок ИИ и потенциалом для большего количества моделей ИИ, работающих одновременно — представьте себе игру, выполняющую масштабирование, нейронные текстуры, генерацию кадров и ИИ NPC — Nvidia захотела лучше планировать ресурсы. Процессор управления ИИ нацелен на это и, по-видимому, может получать подсказки о том, какая рабочая нагрузка выполняется и какую нужно завершить в первую очередь. Таким образом, LLM, выполняющий генерацию текста, может немного задержаться, чтобы сначала выполнить MFG (многокадровую генерацию).
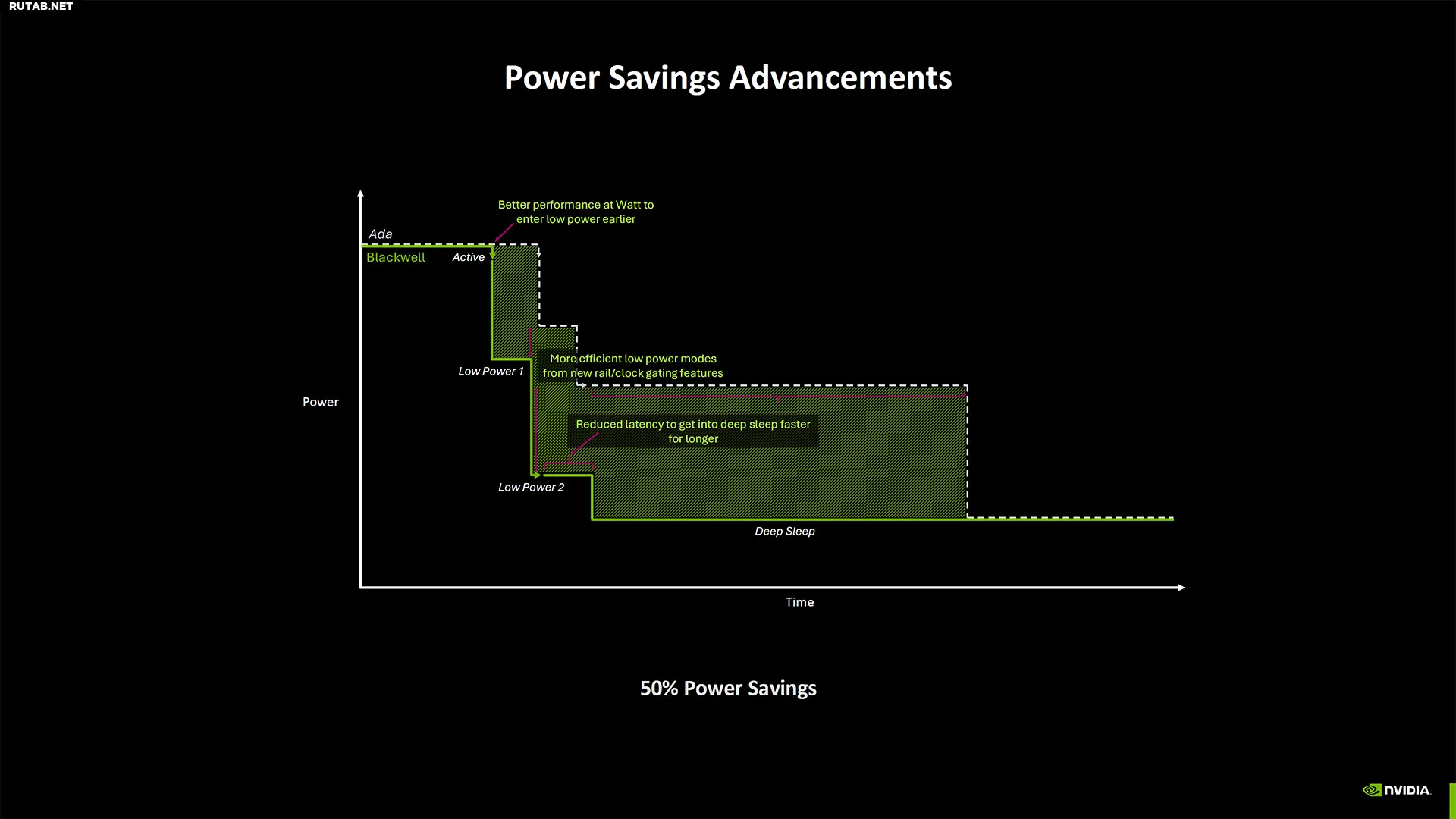
Blackwell также оснащен усовершенствованными функциями управления питанием и энергопотреблением, что позволяет входить в режимы глубокого сна и выходить из них быстрее, чем у предыдущих поколений.
И это все для глубокого погружения в архитектуру Blackwell. По общему признанию, многое из этого было рассмотрено более подробно в некоторых других сессиях, например, разделы Neural Rendering и AI. Проверьте полную презентацию слайдов вверху для дополнительных подробностей.
Источник: Tomshardware.com
0 комментариев