Искусственный интеллект AlphaProof от Google DeepMind решил олимпиадные задачи по математике со 100% точностью
На Международной математической олимпиаде (IMO) 2024 года один участник показал результат, которого хватило бы для серебряной медали, если бы не одно «но»: этим участником была система искусственного интеллекта. Это первый случай в истории конкурса, когда ИИ показал результат, достойный медали. В статье, опубликованной в журнале Nature, исследователи подробно описывают технологию, стоящую за этим выдающимся достижением.
Речь идет об AlphaProof — сложной программе, разработанной Google DeepMind, которая обучается решению сложных математических задач. Успех на IMO сам по себе впечатляет, но настоящая особенность AlphaProof — его способность находить и исправлять ошибки. В то время как большие языковые модели (LLM) могут решать математические задачи, они часто не могут гарантировать точность своих решений — в их рассуждениях могут скрываться незаметные изъяны.
AlphaProof отличается тем, что его ответы всегда на 100% верны. Это достигается благодаря использованию специализированной программной среды Lean (первоначально разработанной Microsoft Research), которая действует как строгий учитель, проверяющий каждый логический шаг. Это означает, что компьютер сам проверяет ответы, поэтому его выводы заслуживают доверия.
Трехэтапный процесс обучения
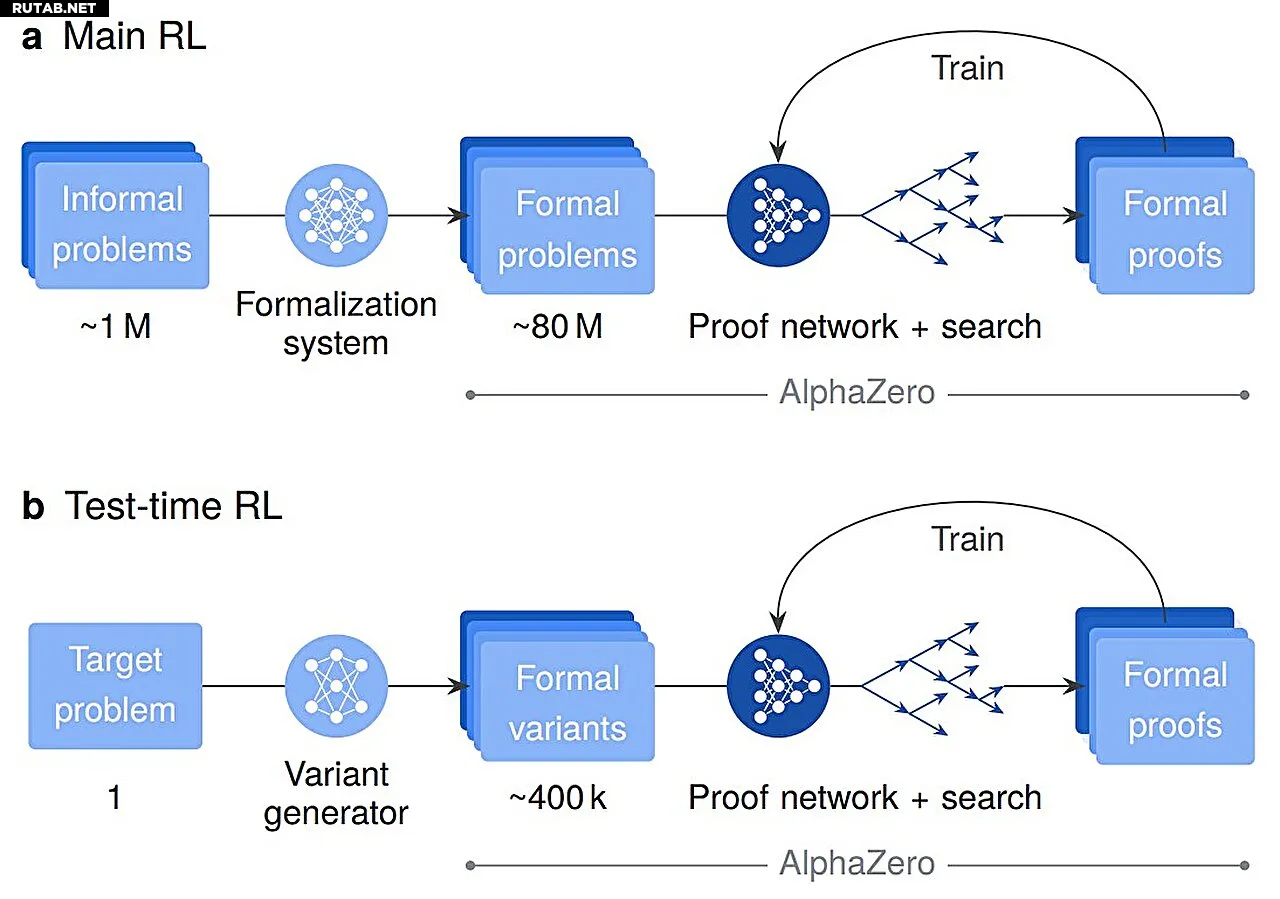
Обучение этой мощной системы рассуждению на элитном уровне включало три различных этапа. Сначала исследователи познакомили AlphaProof примерно с 300 миллиардами токенов общего кода и математических текстов, чтобы дать ему широкое понимание таких концепций, как логика, математический язык и структура программирования. Затем ему предоставили 300 000 математических доказательств, написанных экспертами и уже находящихся в среде Lean.
Финальный этап — это где система научилась решать задачи самостоятельно. Ей дали масштабное «домашнее задание» — решить 80 миллионов формальных математических задач. Используя обучение с подкреплением (Reinforcement Learning, RL), основанное на методе проб и ошибок, AlphaProof получал «вознаграждение» за каждое успешное доказательство. Решая математические задачи в таком огромном масштабе, система сама научилась новым и сложным стратегиям рассуждения, выходящим за рамки простого копирования человеческих примеров.
Для решения самых сложных задач AlphaProof использовал метод, разработанный исследователями, под названием Test-Time RL (TTRL). Он создает и решает миллионы упрощенных версий целевой задачи, пока не найдет решение.
«Наша работа демонстрирует, что масштабное обучение на основе практического опыта создает агентов со сложными стратегиями математических рассуждений, прокладывая путь для создания надежного инструмента ИИ в области решения сложных математических задач», — написали исследователи в своей статье.
Помимо решения, казалось бы, неразрешимых математических задач, AlphaProof также может использоваться математиками для проверки своей работы и помощи в разработке новых теорий.
Системы искусственного интеллекта, способные к формальным рассуждениям, открывают новые горизонты не только в математике, но и в таких областях, как верификация программного обеспечения и криптография, где абсолютная точность имеет критическое значение.



0 комментариев