Вершина эволюции CPU: AMD Zen7 получит 1.4 нм техпроцесс и рекордные 448 МБ кэша 3D V-Cache
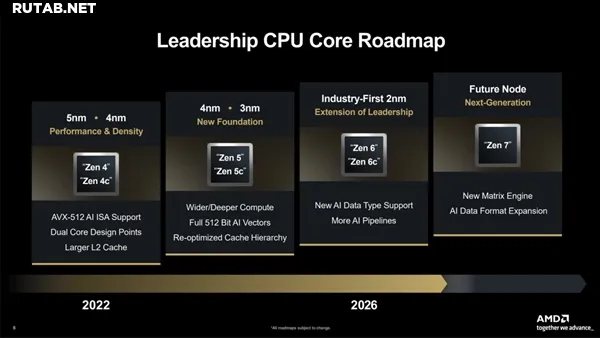
Еще до выхода Zen6 компания AMD уже приоткрыла завесу тайны над архитектурой следующего поколения Zen7. Согласно последним данным из цепочек поставок, Zen7 не только перейдет на техпроцесс 1.4 нм от TSMC, но и получит беспрецедентно большой объем кэш-памяти. Все это указывает на одну тенденцию: центральные процессоры возвращают себе лидирующие позиции в центрах обработки данных.
Ключевой модуль CCD для Zen7, носящий кодовое имя «Grimlock» (в честь персонажа-динобота из «Трансформеров»), будет производиться с использованием нового техпроцесса TSMC N14A. Это не просто промежуточный этап, а полноценное новое поколение, интегрирующее второе поколение транзисторов GAAFET (Gate-All-Around FET) с нанолистовыми каналами и архитектуру стандартных ячеек NanoFlex Pro.
По сравнению с текущим 2-нм техпроцессом N2, новый техпроцесс обещает повышение производительности на 10-15% при том же энергопотреблении или снижение энергопотребления на 25-30% при той же производительности, а также увеличение плотности логических транзисторов до 23%.
Согласно дорожной карте, пробное производство по техпроцессу TSMC N14A начнется в 2027 году, а массовое — в 2028-м, что идеально синхронизируется с графиком выхода Zen7. Для сравнения, аналогичный техпроцесс Intel 14A появится на год позже, его массовое производство ожидается только в 2029 году.
Главным нововведением станет кэш-память. Один CCD в Zen7 будет иметь 16 ядер — вдвое больше, чем в текущем Zen5. В сочетании с новой технологией 3D V-Cache общий объем кэша на одном CCD достигнет 224 МБ. Это означает, что настольный процессор Ryzen с двумя CCD сможет похвастаться 32 ядрами и 448 МБ кэша, что значительно снизит задержки при доступе к данным и ускорит выполнение задач ИИ-инференса и обработку больших массивов информации.
Кроме того, AMD изучает возможность использования технологии FOPLP (Fan-Out Panel Level Packaging) от компании Powertech Technology Inc. (力成科技). Ее ключевая особенность — использование больших квадратных панелей (вместо круглых пластин) в качестве подложки, а также технология перераспределения слоев (RDL) для межсоединений и интеграции чипов. Данная технология обеспечивает высокий коэффициент использования площади (>95%), высокую эффективность производства и значительное снижение затрат.
В настоящее время высокопроизводительные чипы для ИИ используют упаковку CoWoS, но по мере увеличения объема HBM и кэша размеры чипов растут, что приводит к росту затрат на охлаждение и общую стоимость. Технология FOPLP позволяет упаковывать чипы на больших панелях с лучшим отводом тепла и, вероятно, станет новым направлением в упаковке чипов для ИИ.
Столь серьезные инвестиции AMD отражают фундаментальные изменения в архитектуре центров обработки данных для ИИ. Раньше в ИИ-серверах доминировали GPU, а соотношение важности CPU и GPU составляло примерно 4:1. Однако с развитием ИИ-агентов, мультиагентных систем и векторных баз данных нагрузка на CPU резко возросла, и это соотношение постепенно смещается к 1:1.
Тройной удар Zen7 — по техпроцессу, кэшу и упаковке — это новый стандарт, который AMD устанавливает для процессоров в эпоху искусственного интеллекта.

0 комментариев