AMD представила ускоритель ИИ MI350P с 144 ГБ HBM3E — до 40% быстрее Nvidia H200 NVL

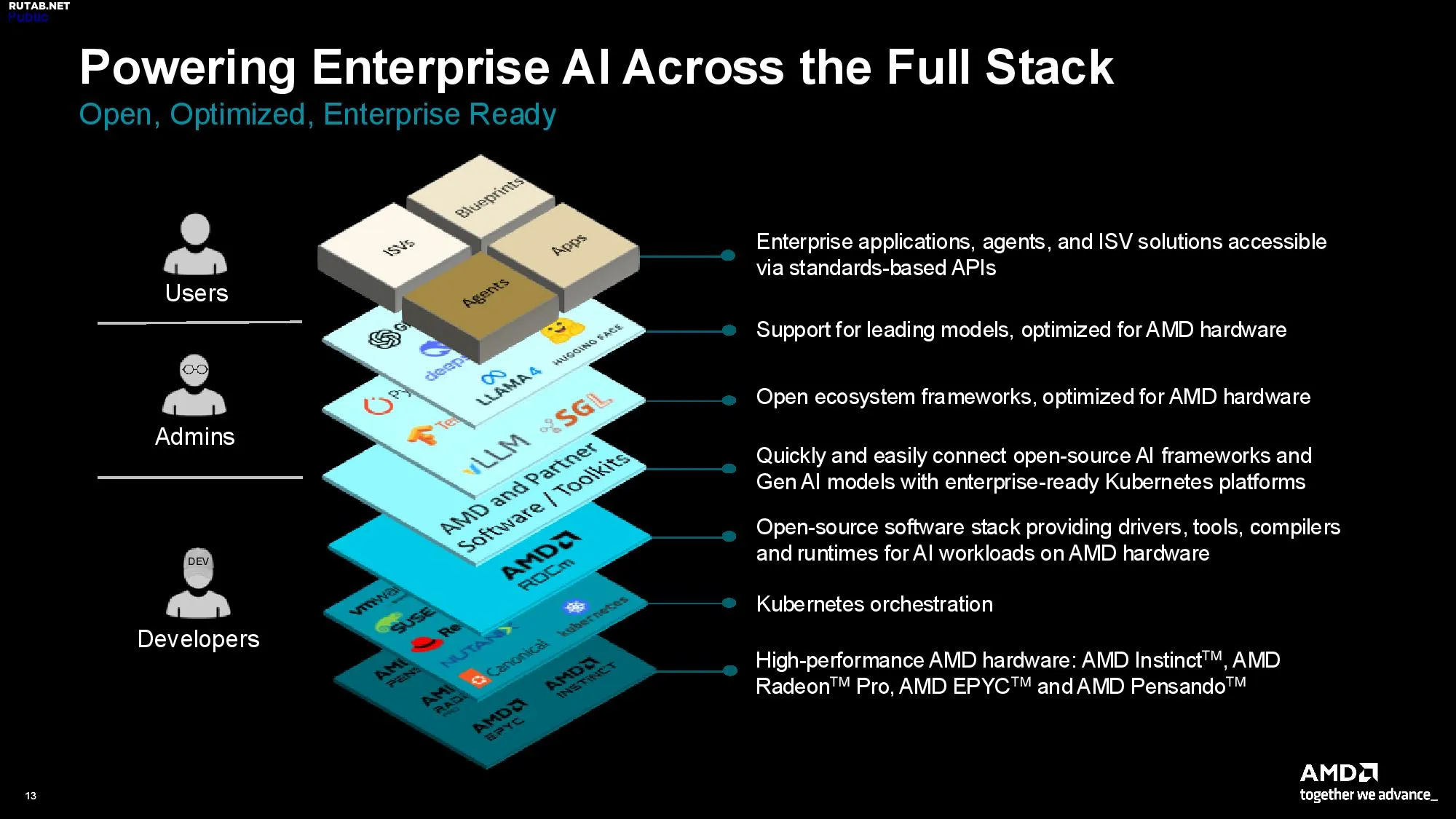
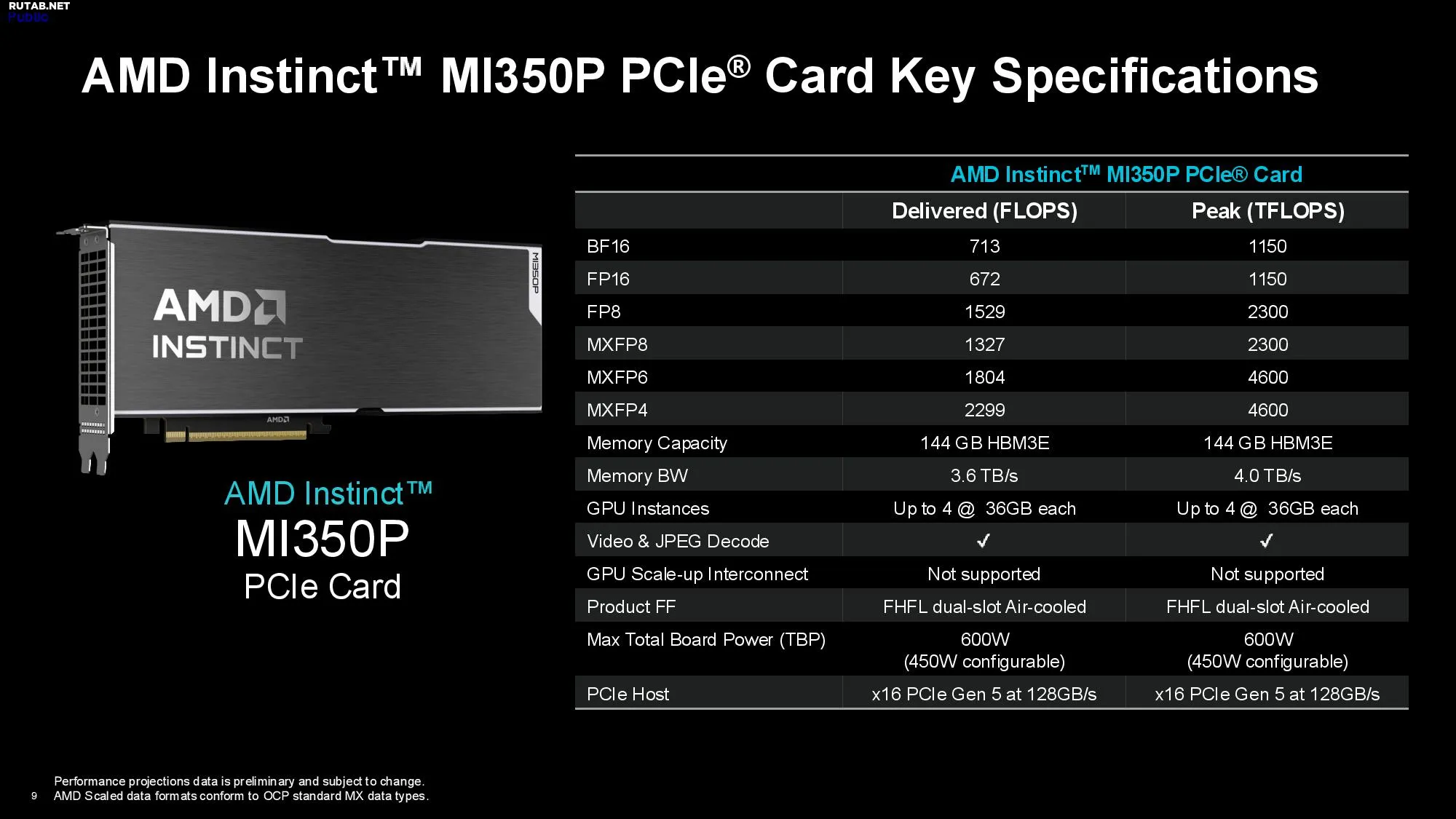
Компания AMD представила новую модель из серии MI350, выполненную в форм-факторе PCIe. Новый ускоритель Instinct MI350P оснащён 128 вычислительными блоками (CU) и 144 ГБ памяти HBM3E. Он разработан как решение для модернизации существующих серверов с воздушным охлаждением, устанавливаемое без доработок.

Изображение: TSMC
MI350P выполнен в виде двухслотовой карты формата 10,5 дюйма с пассивной системой охлаждения, рассчитанной на тепловыделение в 600 Вт (охлаждение обеспечивается вентиляторами корпуса в стоечном сервере). Карта может быть настроена на работу при пониженном энергопотреблении в 450 Вт для совместимости с шасси, имеющими ограничения по тепловыделению или питанию.
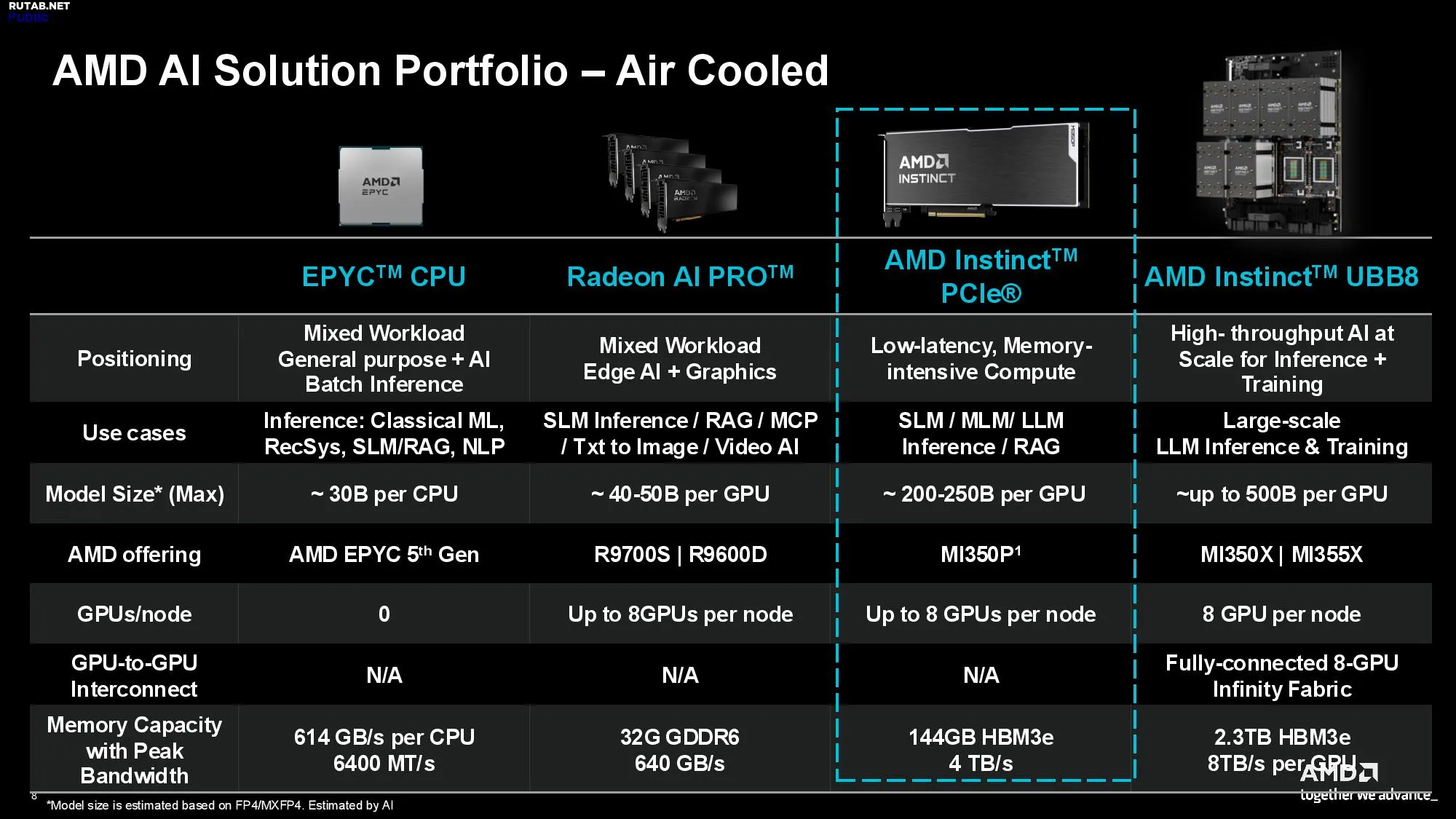
| Характеристики (ПИКОВЫЕ ТЕОРЕТИЧЕСКИЕ) | AMD Instinct MI350P GPU | AMD Instinct MI325X GPU | AMD INSTINCT MI350X GPU | ПЛАТФОРМА AMD INSTINCT MI350X | AMD INSTINCT MI355X GPU | ПЛАТФОРМА AMD INSTINCT MI355X |
|---|---|---|---|---|---|---|
| GPU | Instinct MI350P PCIe | Instinct MI325X OAM | Instinct MI350X OAM | 8 x Instinct MI350X OAM | Instinct MI355X OAM | 8 x Instinct MI355X OAM |
| Архитектура GPU | CDNA 4 | CDNA 3 | CDNA 4 | CDNA 4 | CDNA 4 | CDNA 4 |
| Объём выделенной памяти | 144 ГБ HBM3E | 256 ГБ HBM3E | 288 ГБ HBM3E | 2.3 ТБ HBM3E | 288 ГБ HBM3E | 2.3 ТБ HBM3E |
| Пропускная способность памяти | 4 ТБ/с | 6 ТБ/с | 8 ТБ/с | 8 ТБ/с на OAM | 8 ТБ/с | 8 ТБ/с на OAM |
| Производительность FP64 | 36 TFLOPs | Строка 4 - Ячейка 2 | 72 TFLOPs | 577 TFLOPs | 78.6 TFLOPS | 628.8 TFLOPs |
| Производительность FP16 | 2.3 PFLOPS | 2.61 PFLOPS | 4.6 PFLOPS | 36.8 PFLOPS | 5 PFLOPS | 40.2 PFLOPS |
| Производительность FP8 | 4.6 PFLOPS | 5.22 PFLOPS | 9.2 PFLOPs | 73.82 PFLOPs | 10.1 PFLOPs | 80.5 PFLOPs |
| Производительность FP6 | Строка 7 - Ячейка 1 | Строка 7 - Ячейка 2 | 18.45 PFLOPS | 147.6 PFLOPS | 20.1 PFLOPS | 161 PFLOPS |
| Производительность FP4* | Строка 8 - Ячейка 1 | Строка 8 - Ячейка 2 | 18.45 PFLOPS | 147.6 PFLOPS | 20.1 PFLOPS | 161 PFLOPS |
Характеристики карты ровно вдвое уступают флагманским AI-ускорителям AMD MI350X и MI355X. MI350P работает на архитектуре AMD CDNA4 и производится по техпроцессам TSMC 3 нм и 6 нм FinFET. GPU оснащён 8192 ядрами, 128 вычислительными блоками, 512 матричными ядрами и имеет максимальную тактовую частоту 2,2 ГГц. Карта оснащена 144 ГБ памяти HBM3E с пропускной способностью 4 ТБ/с и 128 МБ кеш-памяти последнего уровня.
Как и MI350X с MI355X, MI350P поддерживает вычисления с пониженной точностью MXFP6 и MXFP4 для ускорения работы больших языковых моделей (LLM). В одной системе можно объединить до восьми карт MI350P, что позволяет центрам обработки данных масштабировать производительность в зависимости от количества используемых ускорителей. MI350P ориентирован на задачи ИИ малого, среднего и крупного масштаба, связанные с выводами (инференсом) и конвейерами RAG. AMD утверждает, что этот GPU является самым быстрым корпоративным PCIe-ускорителем, достигая пиковой производительности в 2299 TFLOPs и 4600 TFLOPs при использовании MXFP4.
Появление MI350P наконец даёт AMD достойного конкурента самому быстрому PCIe-ускорителю Nvidia, которым на данный момент является H200 NVL. MI350P, основанный на более новой архитектуре, превосходит H200 NVL по производительности: на 20% лучше в FP64, на 43% лучше в FP16 и на 39% лучше в теоретических вычислениях FP8.

(Источник изображения: AMD)

(Источник изображения: AMD)
(Источник изображения: AMD)

(Источник изображения: AMD)
(Источник изображения: AMD)

(Источник изображения: AMD)

(Источник изображения: AMD)
(Источник изображения: AMD)
(Источник изображения: AMD)

(Источник изображения: AMD)

(Источник изображения: AMD)

(Источник изображения: AMD)

(Источник изображения: AMD)

(Источник изображения: AMD)

(Источник изображения: AMD)

(Источник изображения: AMD)

(Источник изображения: AMD)
Nvidia пока не анонсировала PCIe-версию своих новейших GPU Blackwell B200 с памятью HBM, так что на данный момент AMD будет предлагать самый передовой AI-ускоритель в форм-факторе PCIe. Насколько широко будет востребована новая карта AMD, пока неясно, учитывая доминирование Nvidia на рынке с её экосистемой CUDA. Однако AMD активно работает над улучшением своего конкурирующего программного стека ROCm, о чём производитель GPU рассказал нам на выставке CES 2026.
Источник: Tomshardware.com
0 комментариев