Хакер сократил наихудшую задержку памяти на 93% с помощью метода TailSlayer

Исследователь и ютубер Лори (LaurieWired) разработала метод TailSlayer, который позволяет значительно снизить наихудшую задержку доступа к оперативной памяти (DRAM) для узкого круга задач, критичных к «хвостовой задержке». Метод борется с задержками, вызванными циклами обновления DRAM — процессом, необходимым для сохранения данных в ячейках памяти.
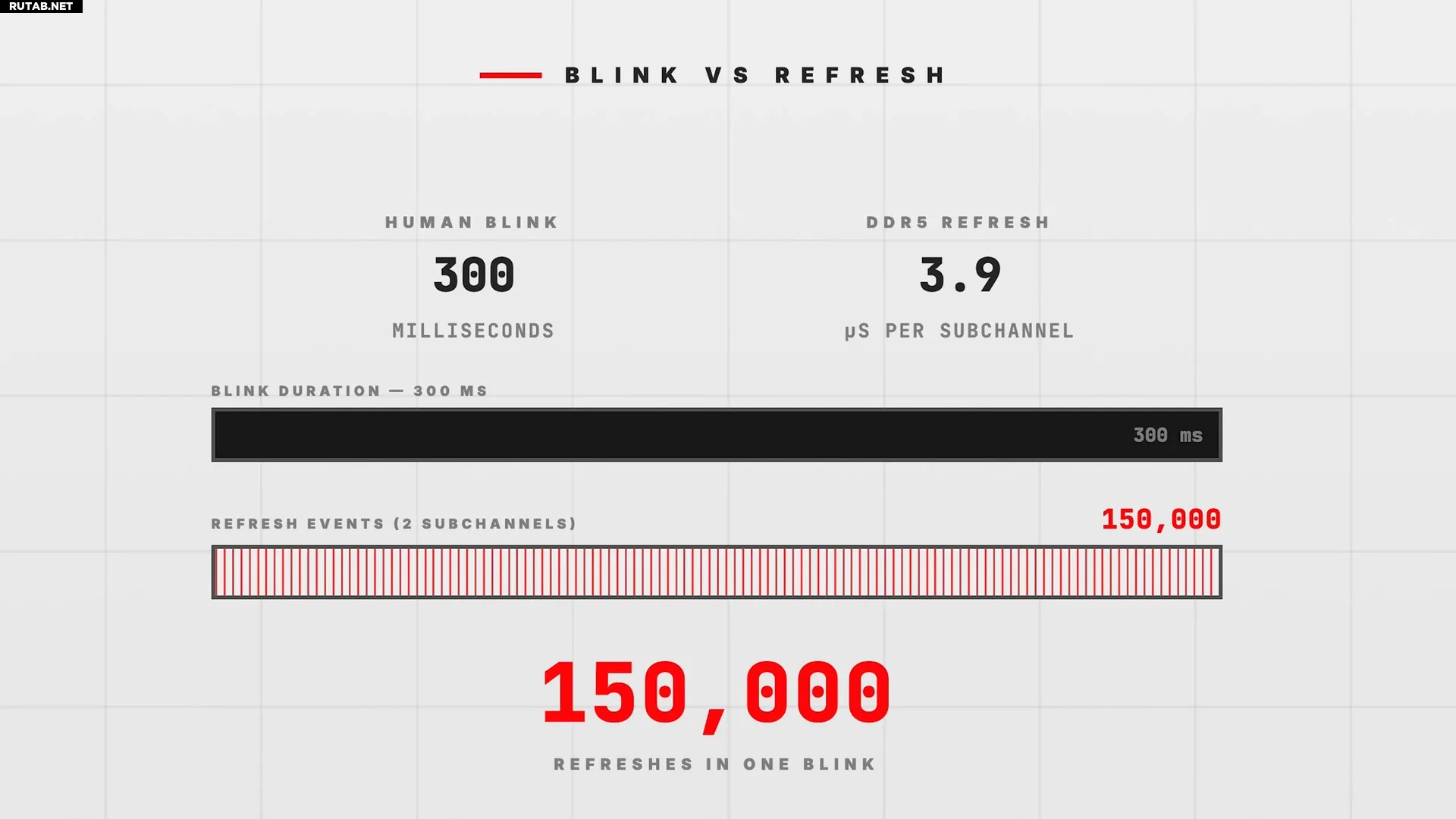
Когда система пытается получить доступ к памяти во время её обновления, запрос «зависает» на сотни наносекунд. Для большинства задач это не проблема, но для таких сфер, как высокочастотный трейдинг (HFT), где важна каждая наносекунда, подобные задержки могут стоить миллионов.
Суть метода TailSlayer заключается в хеджировании обращений к памяти. Рабочий набор данных полностью дублируется на разных физических каналах памяти. Затем операции одновременно выполняются на разных ядрах CPU, каждое из которых обращается к своему каналу. Система просто берёт результат от того ядра, которое завершило работу первым. Вероятность того, что оба ядра одновременно попадут на цикл обновления DRAM, крайне мала.
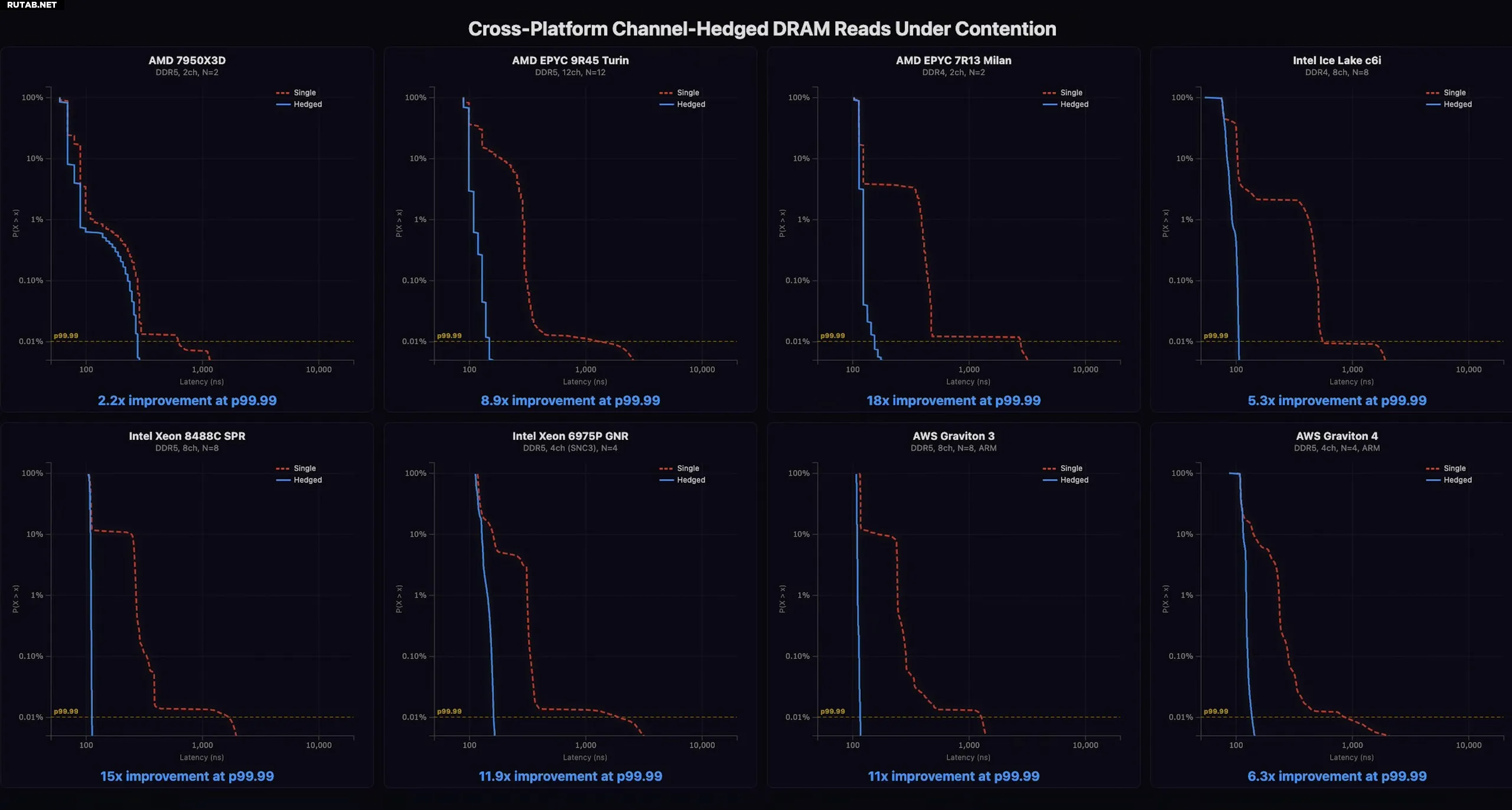
На потребительской системе с Ryzen метод позволил сократить хвостовую задержку более чем вдвое. Тесты на серверных процессорах Amazon AWS показали ещё более впечатляющие результаты благодаря большему количеству каналов памяти. На 12-канальном процессоре AMD EPYC Turin задержка сократилась на 89%. На Intel Xeon (Sapphire Rapids и Diamond Rapids) удалось достичь сокращения на 93,3%, снизив p99.99 задержку с 1697 нс до 113 нс.

Главный недостаток метода — огромные накладные расходы на память. Требуется полное дублирование рабочего набора данных для каждого используемого канала памяти, что умножает потребление памяти. Для HFT, где объёмы данных невелики, а выигрыш в скорости критичен, это приемлемо. Для большинства других задач — нет.
Лори подробно рассказывает о своей работе в 54-минутном видео, где также объясняет, как ей удалось адаптировать метод для Arm-процессоров Amazon Graviton. Исходный код демо-проекта доступен на GitHub.
0 комментариев