Qwen 3.5-4B: компактная модель от Alibaba превзошла GPT-4o в тестах
В этом году, в канун католического Рождества (25 декабря), Alibaba представила серию больших языковых моделей Qwen 3.5. После выпуска флагманских версий компания анонсировала четыре компактные модели: Qwen3.5-0.8B, 2B, 4B и 9B.
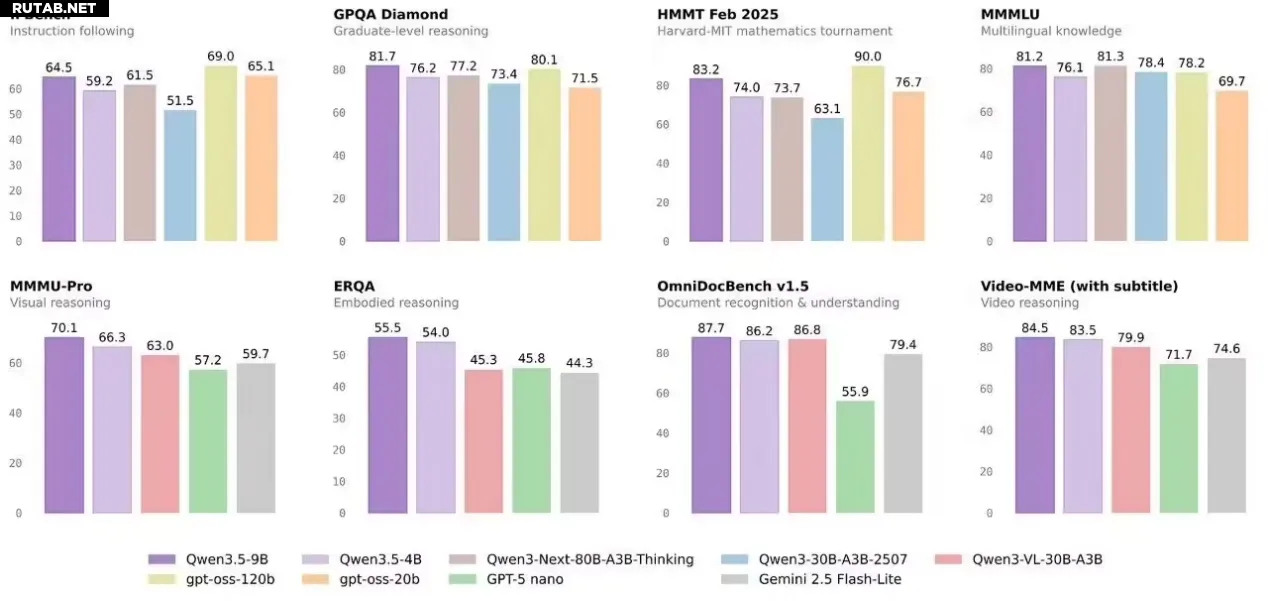
Как отмечают пользователи, именно небольшие модели являются «душой» Qwen, а возможность их локального развертывания обладает неоспоримой привлекательностью. Новая серия Qwen 3.5 не только компактна, но и демонстрирует высокую производительность. Например, версия 9B по своим возможностям сопоставима с моделью gpt-oss-120B.
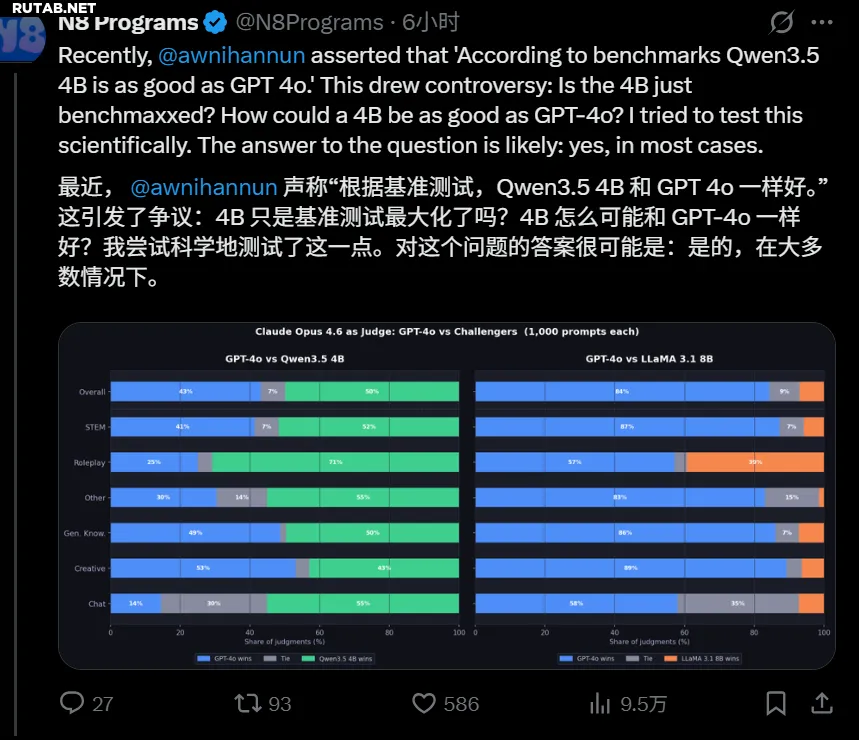
Реальные результаты могут быть ещё более впечатляющими. Пользователь N8 Programs провел практическое тестирование, чтобы проверить заявление разработчиков о том, что модель Qwen 3.5-4B работает так же хорошо, как и GPT-4o.
Итог таков: в большинстве случаев это действительно так. В проведенном тесте Qwen 3.5-4B опередила основную модель GPT-4o.
Для проверки было использовано 1000 случайных вопросов из набора данных WildChat. Ответы обеих моделей оценивались с помощью самой мощной на данный момент модели Opus 4.6. В итоге Qwen 3.5-4B выиграла в 499 случаях из 1000, проиграла в 431 и свела вничью 70 раундов. Это подтверждает, что заявления разработчиков Qwen соответствуют действительности.
Примечательно, что Qwen 3.5-4B — это компактная модель с 4 миллиардами параметров, в то время как GPT-4o, которую многие используют как основную, по данным исследовательской работы Microsoft, имеет около 200 миллиардов параметров (точное число OpenAI не раскрывает). Таким образом, Qwen 3.5-4B, используя всего 2% параметров от GPT-4o, демонстрирует сопоставимую, а в тесте — даже немного лучшую производительность.
Конечно, эти компактные модели Qwen 3.5 не превосходят топовые решения во всем, но они идеально подходят для локального развертывания. Теоретически для запуска 4B-модели достаточно видеокарты с 8 ГБ видеопамяти, хотя на практике рекомендуется 16 ГБ. Дополнительную оптимизацию можно провести с помощью квантования, руководства по которому широко доступны в сети.

Ниже представлено описание и сравнение производительности моделей Qwen на момент их выпуска:
0.8B / 2B: Максимально легкие, идеальный выбор для устройств.
Особенности: Крайне малый размер, высочайшая скорость вывода.
Сценарии использования: Идеально подходят для мобильных устройств, IoT и сценариев, требующих минимальной задержки.
4B: Мощная основа для легковесных агентов.
Особенности: Высокая производительность, мультимодальная базовая модель, подходит для создания агентов.
Сценарии использования: Отлично подходит в качестве «мозга» для легковесных интеллектуальных агентов, идеально балансируя производительность и потребление ресурсов.
9B: Компактный размер, производительность более высокого класса.
Особенности: Компактная архитектура, но производительность сопоставима с gpt-oss-120B, что впечатляет.
Сценарии использования: Подходит для серверного развертывания, где требуется высокий уровень интеллекта, но ресурсы видеопамяти ограничены. Это модель с исключительно высокой ценностью.
0 комментариев