DeepSeek представила модель, которая преобразует текст в изображения для экономии ресурсов

Китайские разработчики компании Deepseek AI выпустили новую модель, которая использует мультимодальные возможности для повышения эффективности обработки сложных документов и больших объемов текста, предварительно преобразуя их в изображения. Визуальные энкодеры смогли преобразовать большие объемы текста в изображения, которые при последующем доступе требовали в 7-20 раз меньше токенов, сохраняя при этом впечатляющий уровень точности.
Deepseek — это китайская разработка в области искусственного интеллекта, которая произвела фурор в начале 2025 года, продемонстрировав возможности, аналогичные OpenAI ChatGPT или Google Gemini, несмотря на значительно меньшие затраты на разработку. Создатели продолжали работать над повышением эффективности ИИ, и с последним релизом, известным как DeepSeek-OCR (оптическое распознавание символов), ИИ может демонстрировать впечатляющее понимание больших объемов текстовых данных без обычных затрат токенов.
«С помощью DeepSeek-OCR мы продемонстрировали, что визуально-текстовое сжатие может достичь значительного сокращения токенов — в 7-20 раз — для различных этапов исторического контекста, предлагая многообещающее направление» для обработки длинных контекстных вычислений, — заявили разработчики.
Новая модель состоит из двух компонентов: DeepEncoder и DeepSeek3B-MoE-A570M, который выступает в роли декодера. Энкодер может преобразовывать большие объемы текстовых данных в изображения высокого разрешения, в то время как декодер особенно хорошо справляется с пониманием текстового контекста в этих изображениях, требуя при этом меньше токенов, чем при прямой подаче текста в ИИ. Это достигается за счет разделения каждой задачи на отдельные подсети и использования специальных экспертов-агентов ИИ для работы с каждым подмножеством данных.
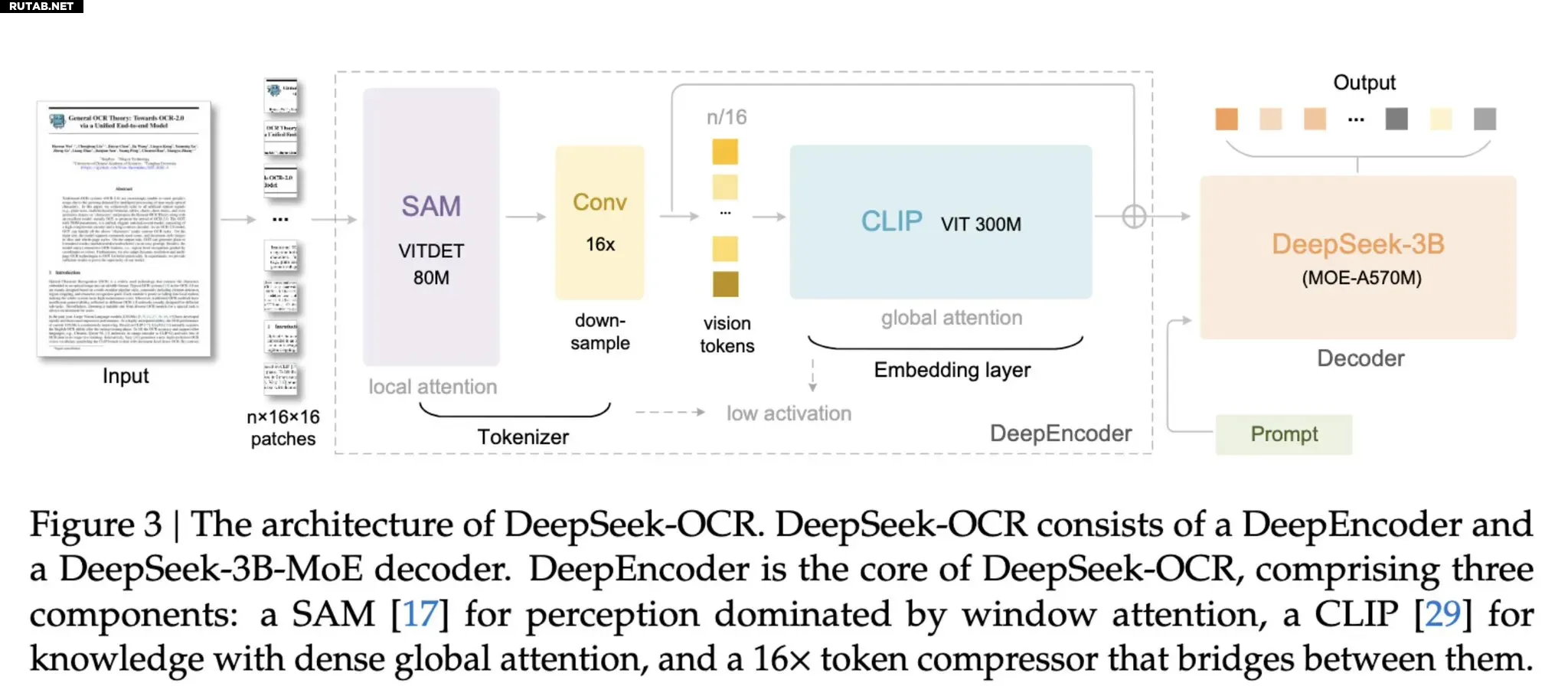
Изображение: Deepseek/AI Engineering/Medium
Этот подход особенно хорошо работает с табличными данными, графиками и другими визуальными представлениями информации. Разработчики предполагают, что технология может найти особое применение в финансах, науке и медицине.
По заявлениям разработчиков, при тестировании при сокращении количества токенов менее чем в 10 раз DeepSeek-OCR может сохранять 97% точности декодирования информации. Если коэффициент сжатия увеличивается до 20 раз, точность падает до 60%. Это менее желательно и показывает, что у технологии есть эффект снижения отдачи, но даже при коэффициенте сжатия 1-2x с точностью, близкой к 100%, это может существенно повлиять на стоимость работы многих современных моделей ИИ.
Технология также позиционируется как способ создания обучающих данных для будущих моделей, хотя внесение ошибок на этом этапе, даже в размере нескольких процентов, кажется не самой лучшей идеей.
Для желающих поэкспериментировать с моделью самостоятельно, она доступна через онлайн-платформы для разработчиков Hugging Face и GitHub.
Интересный факт: Deepseek продолжает удивлять AI-сообщество своими инновациями — всего несколько месяцев назад их модель показала результаты, сопоставимые с GPT-4, но при этом была в 10 раз более эффективной с точки зрения вычислительных ресурсов.
0 комментариев