DeepSeek V4 против топовых ИИ США: отставание в 8 месяцев
24 апреля состоялся официальный релиз серии больших языковых моделей DeepSeek V4. С момента обновления DeepSeek R1 в прошлом году прошло 15 месяцев, и теперь производительность V4 стала предметом активных обсуждений как в Китае, так и за рубежом. Американские эксперты также проявляют к ней повышенный интерес.
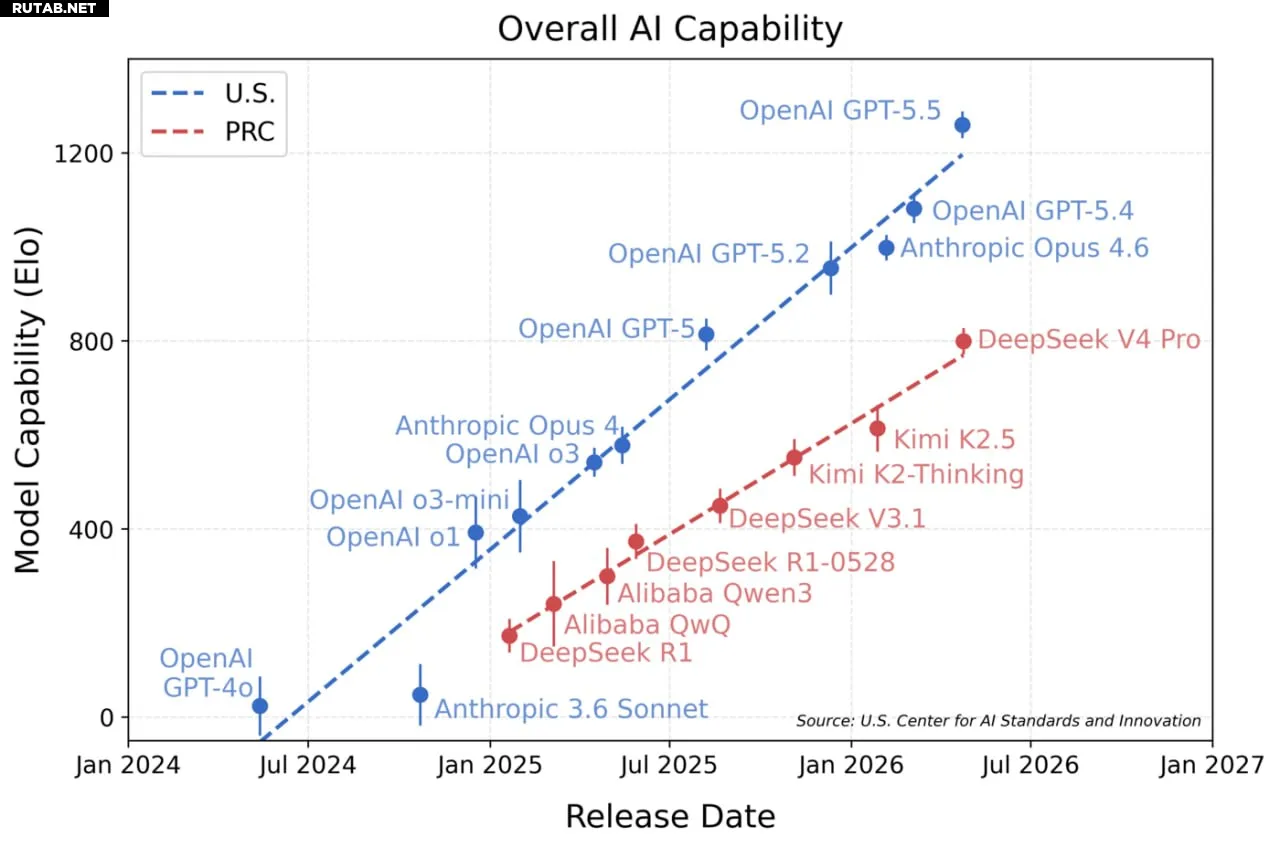
Для оценки возможностей DeepSeek V4 было проведено множество тестов. Совет по международным отношениям США (CFR) на основе исследования трёх старших аналитиков пришёл к выводу, что модель отстаёт от лучших американских аналогов примерно на 7 месяцев.
Теперь к оценке подключился Центр стандартов и инноваций в области искусственного интеллекта (CAISI) при Национальном институте стандартов и технологий США (NIST). Согласно их заключению, DeepSeek V4 отстаёт от американских моделей примерно на 8 месяцев, что в целом совпадает с предыдущими оценками.
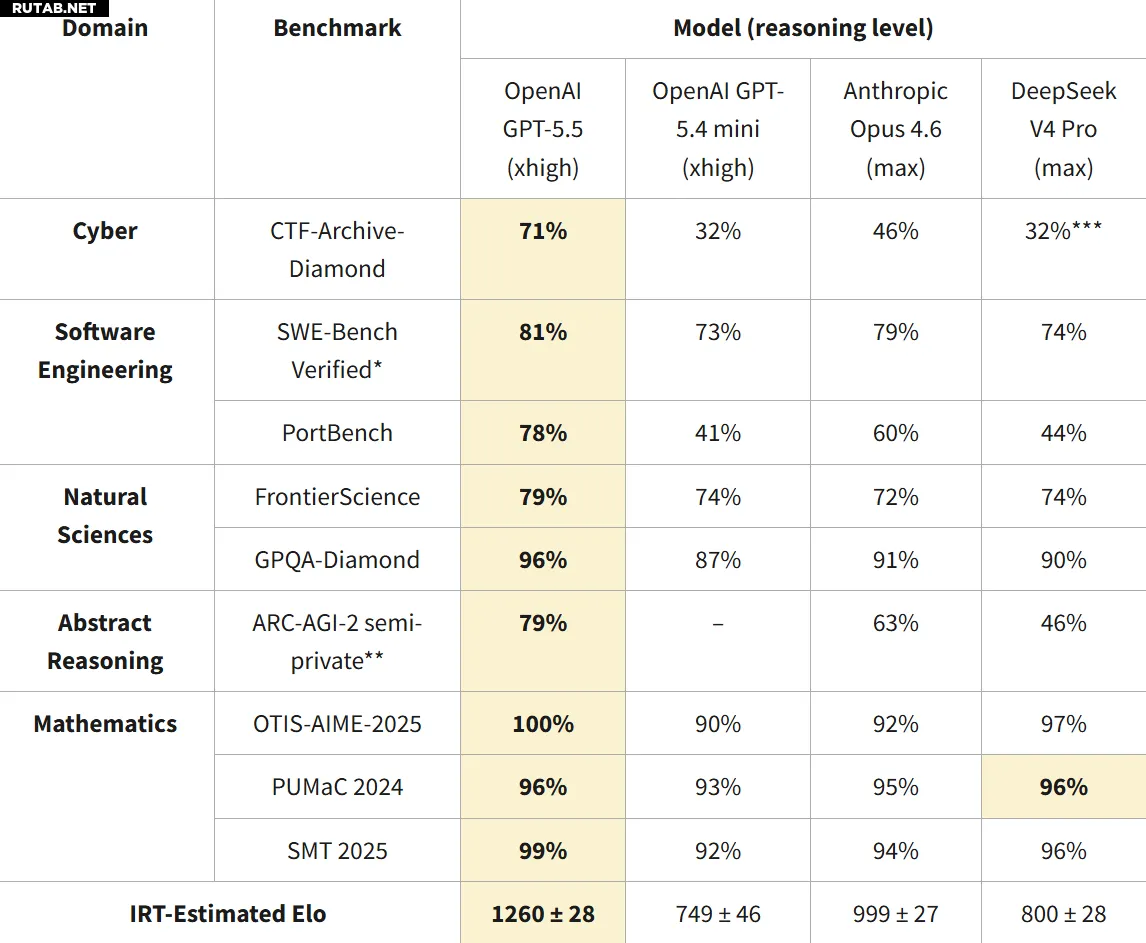
В результатах оценки возможностей ИИ DeepSeek V4 набрал 800 баллов, тогда как текущий лидер GPT-5.5 превышает 1200 баллов. Модели GPT-5.4 и Opus 4.6 также находятся на уровне выше 1000 баллов.
Общая производительность DeepSeek V4 сопоставима с GPT-5 образца 8-месячной давности. При этом ранее в официальном отчёте DeepSeek заявлялось, что их модель близка по возможностям к GPT-5.4.
Тем не менее, в CAISI признали DeepSeek V4 сильнейшей китайской большой языковой моделью из всех, что они тестировали. Модель демонстрирует высокие результаты в девяти тестах по пяти направлениям: работа в сети, программная инженерия, естественные науки, абстрактное мышление и математика.
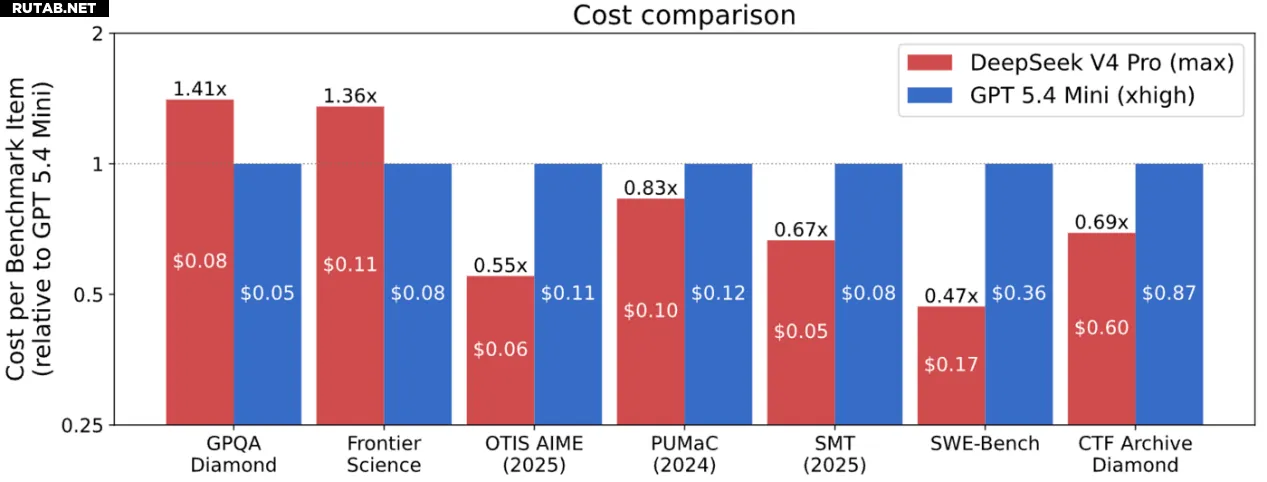
Что ещё более важно, DeepSeek V4 отличается выдающейся экономической эффективностью. Даже в сравнении с самой рентабельной американской моделью GPT-5.4 mini, DeepSeek V4 в 4 из 7 базовых тестов демонстрирует более низкую стоимость при сопоставимых результатах — преимущество составляет от 41% до 53%.






0 комментариев