Intel представила тесты четырёх профессиональных видеокарт Arc Pro B70 в связке: мощность до 720 Вт
Intel недавно представила новое поколение профессиональных видеокарт Arc Pro B70 и B65, в основе которых лежит GPU второго поколения, изначально предназначавшийся для игровой карты Arc B770, выпуск которой, к сожалению, был отменён.
В отличие от игровых решений, обзоры таких профессиональных карт встречаются редко. Немецкое издание HardwareLuxx одним из первых провело тестирование, в том числе и конфигурации из четырёх карт.
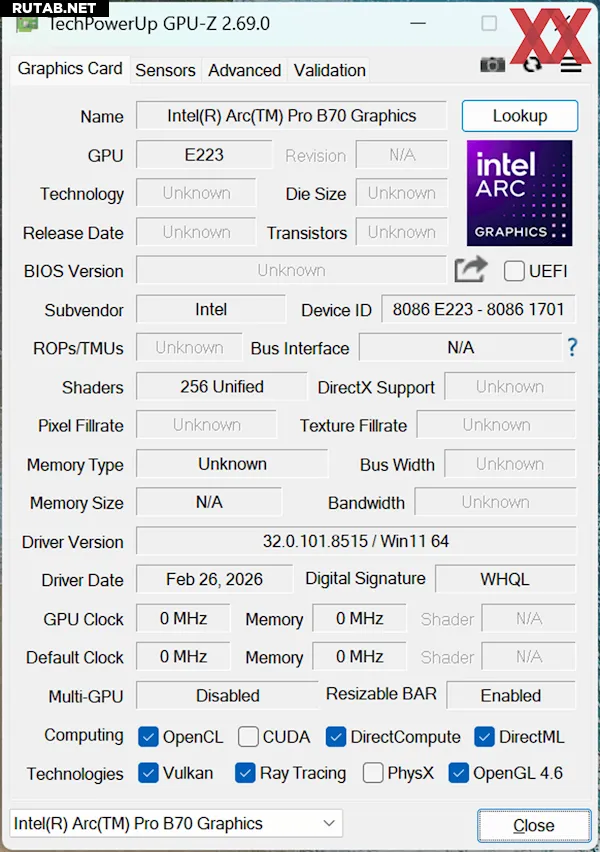
Видеокарта Arc Pro B70 изготовлена по 5-нм техпроцессу TSMC, площадь кристалла составляет 368 кв. мм, а количество транзисторов — 27.7 миллиарда. Она оснащена 32 вычислительными ядрами Xe2 с максимальной частотой 2.8 ГГц, 32 ГБ памяти GDDR6 с 256-битной шиной и пропускной способностью 608 ГБ/с, а также четырьмя разъёмами DisplayPort.
Вычислительная производительность составляет 367 TOPS для FP8 и 22.9 TFlops для FP32. Карта поддерживает интерфейс PCIe 5.0 x16, её заявленное энергопотребление — 230 Вт (с возможностью регулировки от 160 до 290 Вт), для питания используется один 8-контактный разъём.
Модель Arc Pro B65 обладает урезанной конфигурацией: 20 ядер, частота до 2.4 ГГц, тот же объём памяти, но производительность почти вдвое ниже — 197 TOPS для FP8 при энергопотреблении 200 Вт.




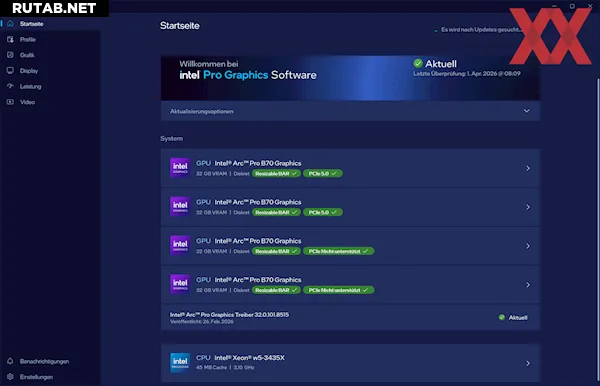
Для тестирования были использованы четыре референсные карты B70 в системе с 16-ядерным процессором Xeon W5-3435X и 128 ГБ оперативной памяти DDR5-4800. Тесты проводились как в Windows 11, так и в Ubuntu.




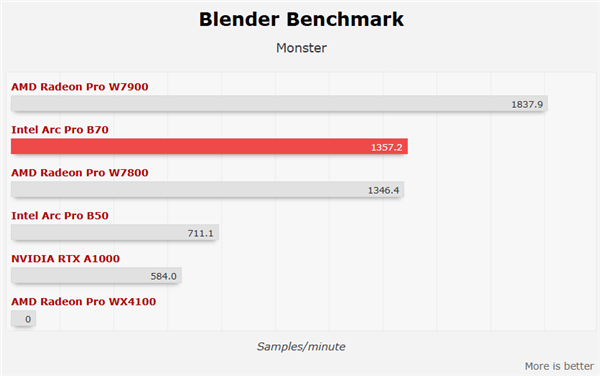
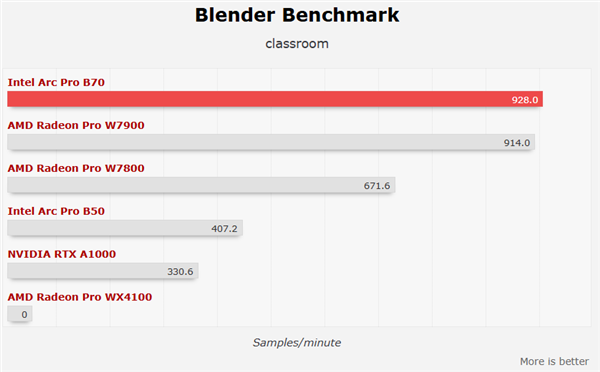
В тестах, ориентированных на рабочие станции, одна карта B70 показала себя достойно, в целом находясь на уровне AMD Radeon Pro W7800, а в некоторых задачах, таких как Blender Classroom, значительно опережая её и даже догоняя более мощную Radeon Pro W7900.
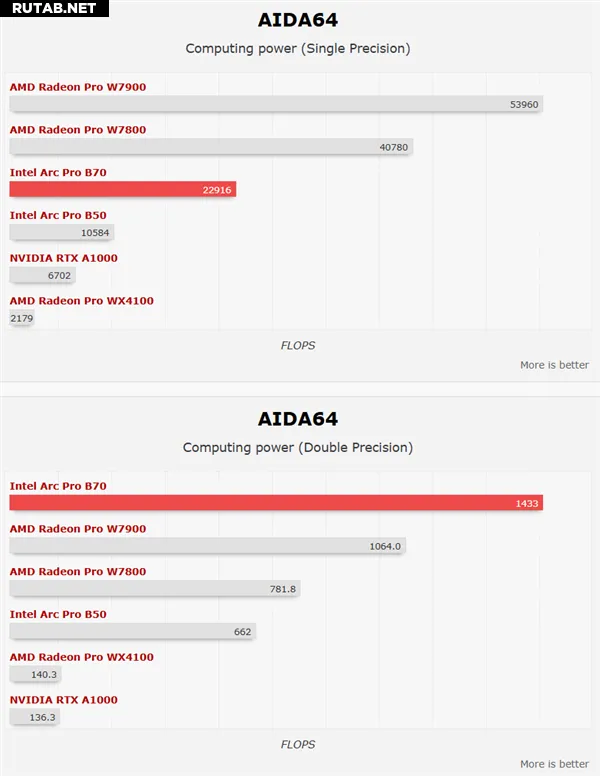
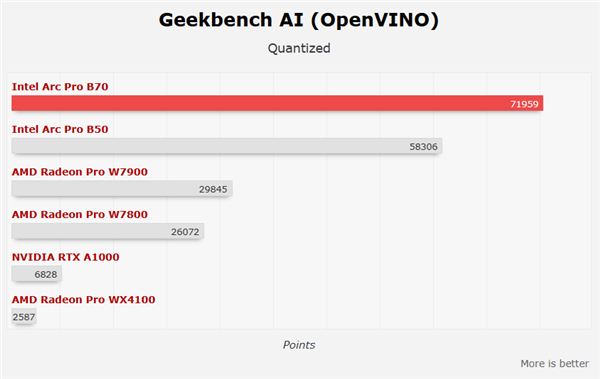
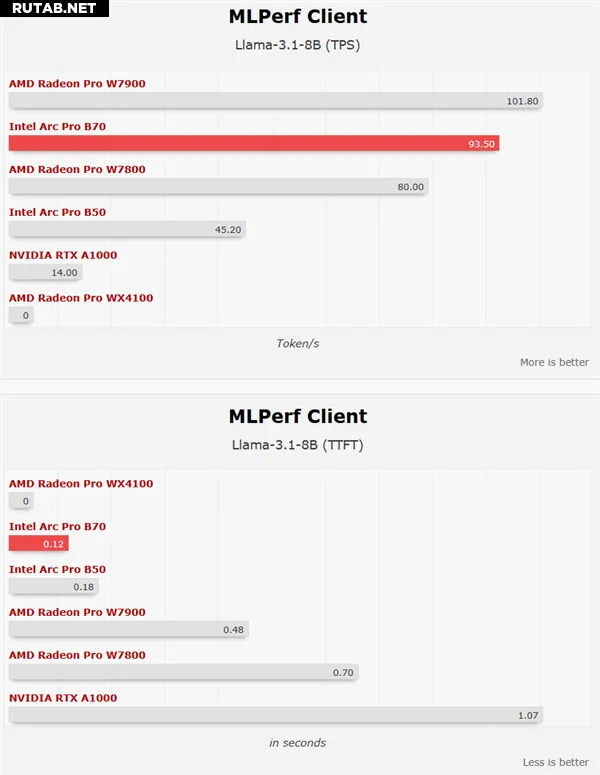
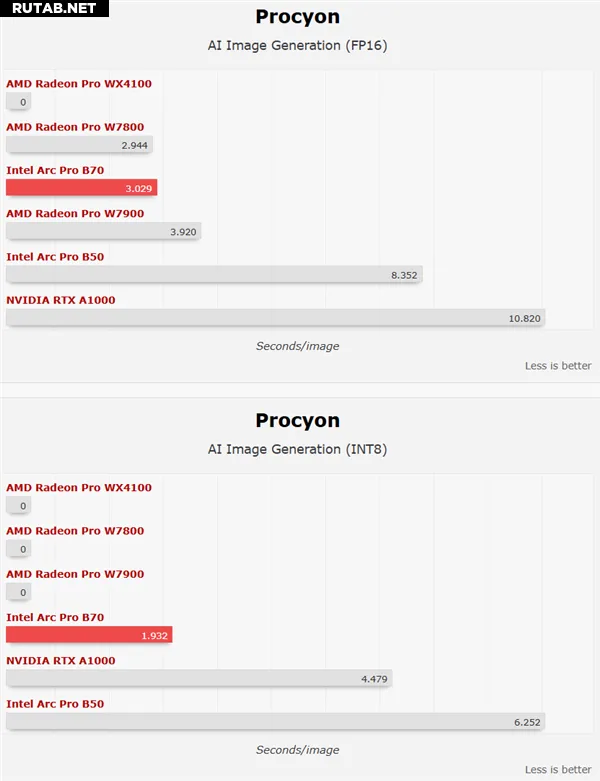
В тестах искусственного интеллекта производительность также впечатляет: вычисления с двойной точностью в AIDA64, тесты GeekBench AI, скорость генерации в MLPerf Llama (особенно время до первого токена) и результаты Procyon AI Image Generation значительно опережают решения от AMD и NVIDIA.

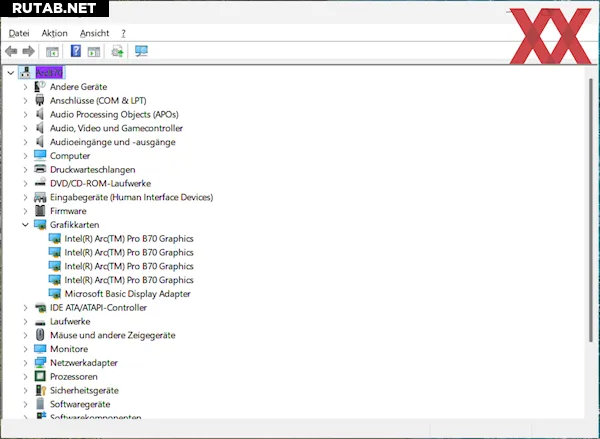
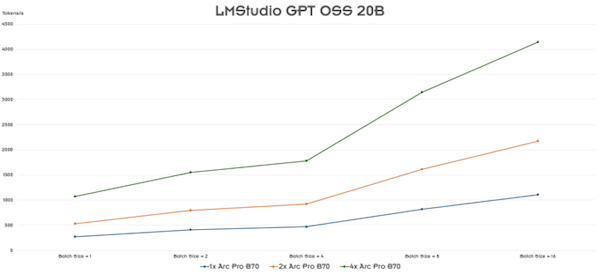
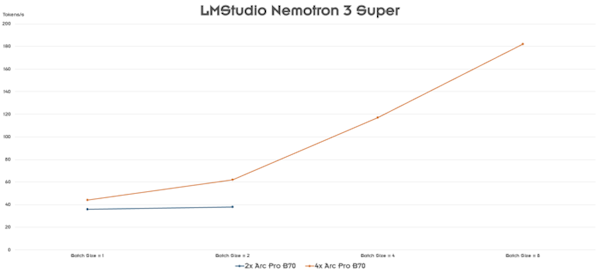
Система корректно распознаёт две и четыре карты, однако эффективность масштабирования оставляет желать лучшего. Почти ни в одном профессиональном или AI-тесте не удалось задействовать все четыре GPU с пользой, а в Blender проблемы возникали даже с двумя картами.
Единственным исключением, где проявилось преимущество нескольких карт, стал тест LMStudio в Ubuntu, но и там прирост производительности был далёк от линейного. Основная причина — отсутствие прямой связи между GPU, обмен данными происходит только через шину PCIe.
Также отмечено, что 64 ГБ памяти двух карт недостаточно для работы с некоторыми большими языковыми моделями объёмом 120 млрд параметров, тогда как 128 ГБ от четырёх карт уже более практичны.
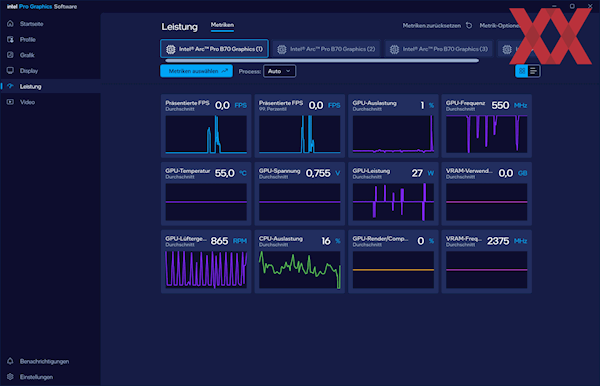
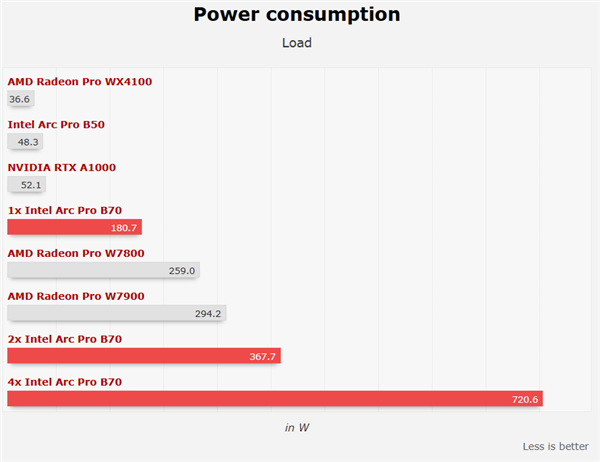
Энергопотребление закономерно росло: одна карта в простое потребляла 26 Вт, при выполнении AI-задач — около 180 Вт. Две карты требовали уже почти 370 Вт, а конфигурация из четырёх GPU разгоняла систему до отметки свыше 720 Вт.
Учитывая, что заявленное энергопотребление одной карты составляет 230 Вт, теоретический максимум для четырёх карт должен быть выше 900 Вт, так что результат в 720 Вт можно считать относительно удачным.
0 комментариев