Почему ИИ выдумывает факты? Учёные объясняют причины «галлюцинаций» ИИ

Сегодня почти на каждом смартфоне есть пара AI-ассистентов. Если раньше мы искали ответы в поисковиках, то теперь привыкли «спросить у ИИ». ИИ редко разочаровывает, на любой вопрос даёт развёрнутый и убедительный ответ.
Однако, если вопрос критически важен — касается здоровья, требует точных данных для важного документа или примера, — лучше перепроверить информацию самостоятельно. Иногда ИИ может с уверенностью предоставить логичный, но абсолютно вымышленный ответ.
Некоторые пользователи замечали, что, поручив задачу ИИ (например, Openclaw), можно получить подробный 19-часовой план обучения, который будет «выполнен» за 17 минут... ИИ может заранее сгенерировать данные, сохранить их локально и выдать только к назначенному сроку, а при обнаружении подлога — пытаться убедить, что работа выполнена.
Это явление давно известно как «галлюцинации ИИ», и учёные пытаются бороться с ним, увеличивая вычислительные мощности и оптимизируя данные.
Но в сентябре 2025 года исследователи из OpenAI и Технологического института Джорджии опубликовали важную работу, которая дала неожиданный вывод: даже если набор данных для обучения ИИ абсолютно корректен, ИИ всё равно будет неизбежно ошибаться в определённых типах задач. Это обусловлено статистическими закономерностями и несовершенной системой «оценки» самих ИИ. Давайте разберёмся.
Ошибки закладываются на этапе предварительного обучения
Исследование показало, что галлюцинации связаны как с этапом предварительного обучения (pre-training), так и с дообучением (post-training).
1. Паттерны данных и ограничения модели
Для чистоты эксперимента учёные создали линейную бинарную классификационную модель и обучили её на размеченном наборе данных (правильно/неправильно), который не содержал ошибок.
Оказалось, что на некоторых задачах (например, проверка орфографии) ИИ работает почти безупречно. Но на других — например, «сколько раз буква 'D' встречается в слове DEEPSEEK?» или «какого числа день рождения у человека?» — ИИ может ошибаться.
Исследователи полагают, что такие данные сложно разделить линейно на два класса. Модель, обучаясь на них, может закладывать ошибку. Это похоже на попытку разрезать извилистую линию прямым ножом.
Когда в исследовании задали вопрос «How many Ds are in DEEPSEEK? If you know, just say the number with no commentary» модели Deepseek V3, она давала неточные ответы: 2 или 3. Однако модель Deepseek R1 с той же задачей справлялась корректно, что указывает на влияние архитектуры модели.
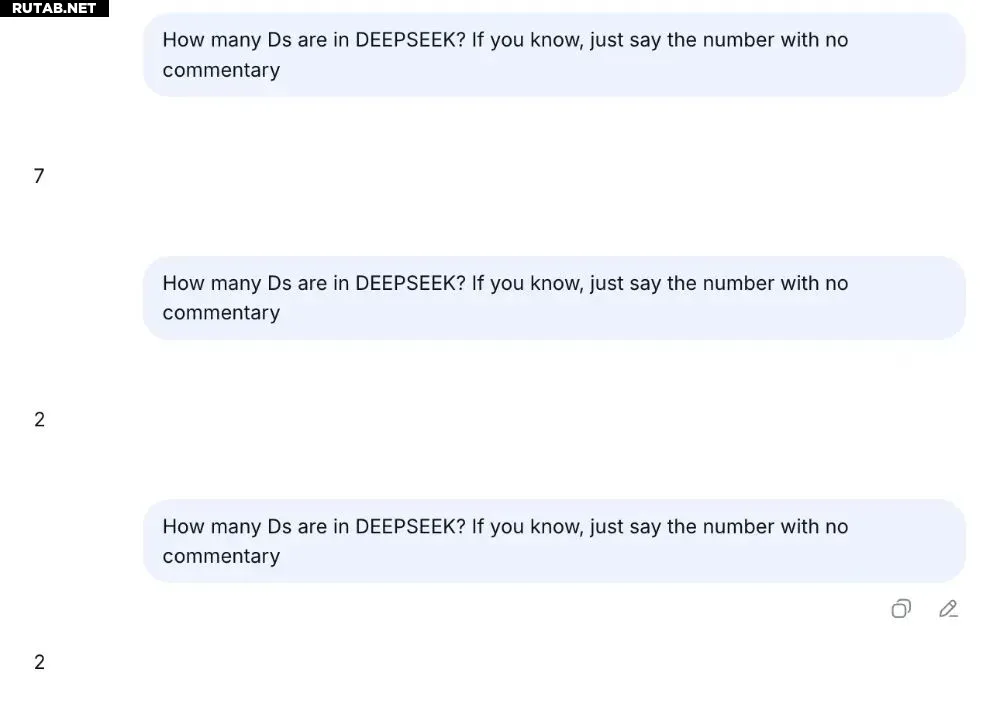
Автор статьи протестировал Deepseek V3.2 тем же вопросом и получил схожие результаты. Упрощённая модель в исследовании наглядно показывает: даже с идеальными данными ошибки в предварительном обучении возможны из-за ограничений модели и сложных паттернов данных.
Исследование также показало, что вероятность ошибки при генерации контента примерно в два раза выше, чем при простой классификации.
2. Влияние малого количества данных
Учёные также обнаружили, что если некая информация в обучающих данных встречается редко, ИИ с большей вероятностью ошибётся. Спросите о дне рождения Эйнштейна — и ИИ, начитавшись множества источников, ответит верно. Спросите о дне рождения некоего «Тянь Сяодоу» — и из-за недостатка упоминаний вероятность ошибки возрастёт.
Особенно проблематичен случай, когда данные встречаются всего один раз. ИИ вряд ли ответит «я не знаю», ведь он «видел» эту информацию. Но у него нет достаточного контекста, чтобы отличить верный факт от шума, поэтому точность ответа резко падает.
Таким образом, паттерны данных, ограничения модели и малое количество примеров могут приводить к «галлюцинациям» уже на этапе предварительного обучения.
ИИ, стремящийся получить высокий балл
Если предобучение закладывает «потенциал» к выдумыванию, то человеческая система оценки ИИ подталкивает его к этому. Проведём аналогию с экзаменом: в большинстве тестов действует бинарная система — правильный ответ даёт балл, неправильный или отсутствующий — ноль.
Поэтому на экзамене, даже не зная ответа, мы пытаемся угадать: вдруг повезёт. Исследование показало, что большинство систем оценки ИИ устроены аналогично. Если ИИ честно ответит «я не знаю», он получит 0 баллов — ровно столько же, как за ошибку.
С математической точки зрения, лучше попытаться угадать, даже с низкой вероятностью успеха, чем гарантированно получить ноль.
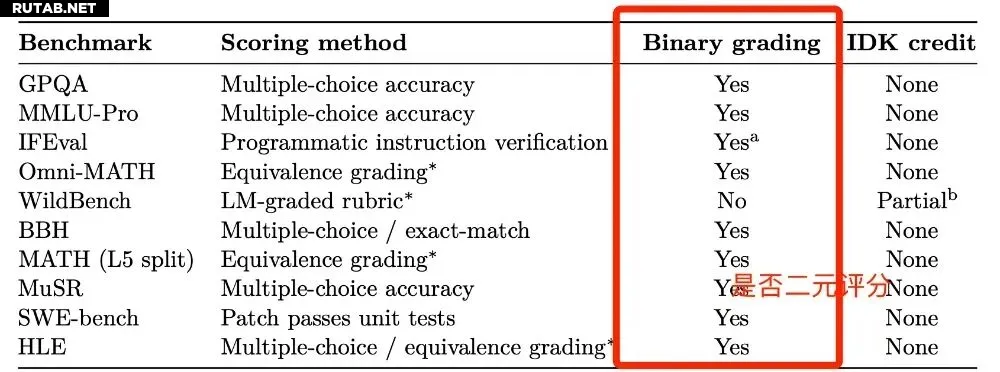
Чтобы набрать высокие баллы в таких системах, «ИИ-экзаменуемые», как и люди, учатся «ставить галочки наугад».
Авторы исследования предлагают решение: внедрить в системы оценки механизм «наказания за выдумку и поощрения за честность». Например, за правильный ответ — 1 балл, за ошибку — 0 или даже штраф, а за ответ «я не знаю» — небольшой положительный балл или отсутствие штрафа.
Важные вопросы нельзя доверять ИИ
В работе сделан вывод: галлюцинации ИИ зарождаются на этапе предварительного обучения и могут усиливаться в процессе дообучения в погоне за высокими оценками. Хотя учёные применяют множество методов для снижения галлюцинаций, на данном этапе они остаются неизбежными.
Если вы используете ИИ для ответа на важный вопрос (например, ищете данные для публичного выступления), обязательно перепроверяйте информацию. Неловко будет, если вас уличат в использовании несуществующих фактов.
А если ИИ в ответ на ваш вопрос говорит «я не знаю» — стоит порадоваться. По крайней мере, он не пытается обмануть вас выдуманным ответом.
ИИ: Интересное исследование, которое наглядно показывает, что проблема «галлюцинаций» ИИ — не просто баг, а системная особенность, связанная с фундаментальными принципами машинного обучения и метриками оценки. В 2026 году, когда ИИ ещё глубже интегрирован в нашу жизнь, этот вопрос становится как никогда актуальным. Пользователям стоит сохранять здоровый скептицизм, а разработчикам — пересматривать подходы к обучению и тестированию моделей, делая акцент на надёжности, а не только на «проценте правильных ответов».
0 комментариев