Moore Threads выпустила инструмент симуляции для обучения больших языковых моделей с точностью до 1%
Китайская компания Moore Threads официально выпустила и открыла исходный код инструмента симуляции распределённого обучения SimuMax v1.0 для больших языковых моделей. Инструмент демонстрирует прорыв в точности симуляции использования видеопамяти и производительности, одновременно предлагая новые ключевые функции для улучшения совместимости и гибкости моделей.
SimuMax — это специализированный инструмент моделирования, разработанный для распределённых рабочих нагрузок обучения больших языковых моделей (LLM), обеспечивающий поддержку симуляции от одной видеокарты до кластеров из десятков тысяч карт.
Инструмент позволяет с высокой точностью имитировать использование видеопамяти и производительность во время обучения без необходимости запуска полного процесса тренировки модели. Это помогает пользователям заранее оценить эффективность обучения и оптимизировать вычислительную производительность.
Основанный на статической аналитической модели, собственной разработке Moore Threads, SimuMax сочетает стоимостную модель, модель памяти и «крышевидную» модель (roofline model) для достижения точной симуляции процесса обучения.

Инструмент поддерживает множество основных стратегий распределённого параллелизма и технологий оптимизации, подходя для следующих сценариев применения:
1. Стратегии параллелизма:
Распределение данных (DP), тензорный параллелизм (TP), последовательный параллелизм (SP), конвейерный параллелизм (PP), параллелизм экспертов (EP).
2. Технологии оптимизации:
ZeRO-1, полный пересчёт, выборочный пересчёт, объединённые ядра и другие.
3. Для кого предназначен:
Пользователи, желающие найти оптимальную стратегию обучения для повышения эффективности;
Инженеры, занимающиеся разработкой фреймворков или алгоритмов больших моделей, для оптимизации и отладки;
Производители чипов, для прогнозирования производительности и помощи в проектировании аппаратного обеспечения.
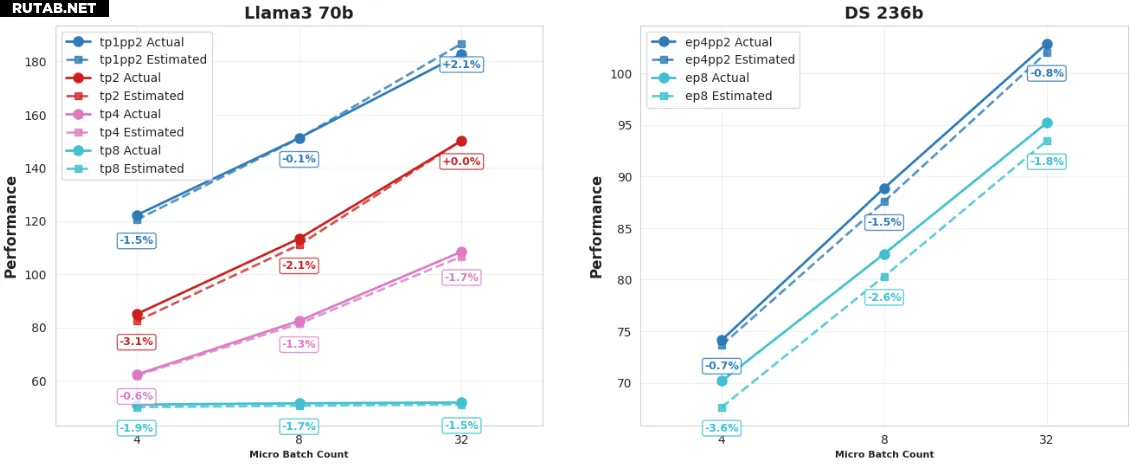
Наиболее значимым обновлением SimuMax 1.0 является существенное повышение точности симуляции, что предоставляет пользователям более надёжные аналитические результаты.
Для плотных (Dense) и MoE (Mixture of Experts, смесь экспертов) моделей ошибка оценки использования видеопамяти стабильно составляет менее 1%.
Согласно тестированию, на нескольких основных GPU ошибка оценки пиковой производительности стабильно остаётся ниже 4%.
Кроме того, SimuMax 1.0 представил ряд новых функций, поддерживающих более широкий спектр архитектур моделей и потребностей в эффективном обучении:
Поддержка MLA: Добавлена поддержка архитектуры моделей MLA.
Улучшение конвейерного параллелизма (PP): Поддержка детального контроля слоёв на начальной и конечной стадиях, оптимизация стратегий шардинга модели.
Повышение гибкости MoE: В моделях «смеси экспертов» (MoE) добавлена поддержка пользовательских плотных (Dense) слоёв, что предоставляет большую гибкость в проектировании моделей.
Совместимость с Megatron: Предоставлен упрощённый процесс миграции моделей, позволяющий легко конвертировать и анализировать модели, основанные на фреймворке Megatron, улучшая взаимодействие с существующей экосистемой.
Оптимизация стратегий пересчёта: Реализован более детальный выборочный пересчёт, поддерживающий более точный баланс между памятью и вычислительными ресурсами.
Всесторонний анализ эффективности: Добавлена функция оценки вычислительной эффективности и утилизации при различных формах тензоров и расположениях памяти.
0 комментариев