Прорыв китайской компании в области искусственного интеллекта в области модели подчеркивает ограничения санкций США

Ме́та — многозначный термин. Википедия
Читайте также:Релиз Hitman: World of Assassination для PlayStation VR2 состоится в декабреШутер для виртуальной реальности Metro: Awakening выйдет 7 ноябряРелиз версии Hitman 3 VR Reloaded для шлемов виртуальной реальности состоится 5 сентябряОбъявлено окно релиза Batman: Arkham Shadow для VR: игра выйдет в октябреВышел трейлер Hitman 3 VR Reloaded для Quest 3
Санкции США (в том числе экстерриториальные) в отношении третьих стран: Санкции США против Кубы Санкции США против Ирана Санкции США против России (см. Американо-российские отношения, Санкции против Российской Федерации: Список Магнитского, Санкции против России (2014), Северный поток — 2#Санкции США против проекта) Санкции США против КНР (см. Американо-китайские отношения#Экономическое партнерство, Торговая война между США и Китаем (с 2018)) Санкции США против Сирии (см. Американо-сирийские отношения) Санкции США против Турции (с октября 2019 года, из-за ситуации в Северной Сирии) Санкции США против Венесуэлы (также, Санкции против Венесуэлы В 2021 г. Википедия
Deepseek обучил свою языковую модель DeepSeek-V3 Mixture-of-Experts (MoE) с 671 миллиардом параметров, используя кластер, содержащий 2048 графических процессоров Nvidia H800, всего за два месяца, что означает 2,8 миллиона часов работы GPU, согласно его статье. Для сравнения, Meta потребовалось в 11 раз больше вычислительной мощности ( 30,8 миллиона часов работы GPU), чтобы обучить Llama 3 с 405 миллиардами параметров, используя кластер, содержащий 16 384 графических процессора H100, в течение 54 дней.
DeepSeek утверждает, что ей удалось значительно сократить требования к вычислениям и памяти, обычно требуемые для моделей такого масштаба, используя передовые конвейерные алгоритмы, оптимизированную коммуникационную структуру и низкоточные вычисления FP8, а также коммуникацию.
Компания использовала кластер из 2048 графических процессоров Nvidia H800, каждый из которых был оснащен межсоединениями NVLink для GPU-GPU и межсоединениями InfiniBand для коммуникаций между узлами. В таких конфигурациях коммуникации между GPU довольно быстрые, но коммуникации между узлами — нет, поэтому оптимизация является ключом к производительности и эффективности. Хотя DeepSeek реализовал десятки методов оптимизации для снижения вычислительных требований своего DeepSeek-v3, несколько ключевых технологий позволили добиться впечатляющих результатов.
DeepSeek использовал алгоритм DualPipe для перекрытия фаз вычислений и коммуникации внутри и между прямыми и обратными микропакетами и, таким образом, снизил неэффективность конвейера. В частности, операции отправки (маршрутизации токенов экспертам) и объединения (агрегации результатов) обрабатывались параллельно с вычислениями с использованием настраиваемых инструкций PTX (Parallel Thread Execution), что означает написание низкоуровневого специализированного кода, который предназначен для взаимодействия с графическими процессорами Nvidia CUDA и оптимизации их операций. Алгоритм DualPipe минимизировал узкие места обучения, особенно для экспертного параллелизма между узлами, требуемого архитектурой MoE, и эта оптимизация позволила кластеру обработать 14,8 триллиона токенов во время предварительного обучения с почти нулевыми издержками на связь, согласно DeepSeek.
В дополнение к внедрению DualPipe, DeepSeek ограничил каждый токен максимум четырьмя узлами, чтобы ограничить количество узлов, участвующих в коммуникации. Это сократило трафик и гарантировало, что коммуникация и вычисления могут эффективно перекрываться.
Критически важным элементом снижения вычислительных и коммуникационных требований стало принятие методов обучения с низкой точностью. DeepSeek использовал смешанную структуру точности FP8, что позволило ускорить вычисления и сократить использование памяти без ущерба для числовой стабильности. Ключевые операции, такие как умножение матриц, проводились в FP8, в то время как чувствительные компоненты, такие как встраивания и слои нормализации, сохраняли более высокую точность (BF16 или FP32) для обеспечения точности. Такой подход снизил требования к памяти, сохранив при этом надежную точность, при этом относительная ошибка потери обучения постоянно была ниже 0,25%.
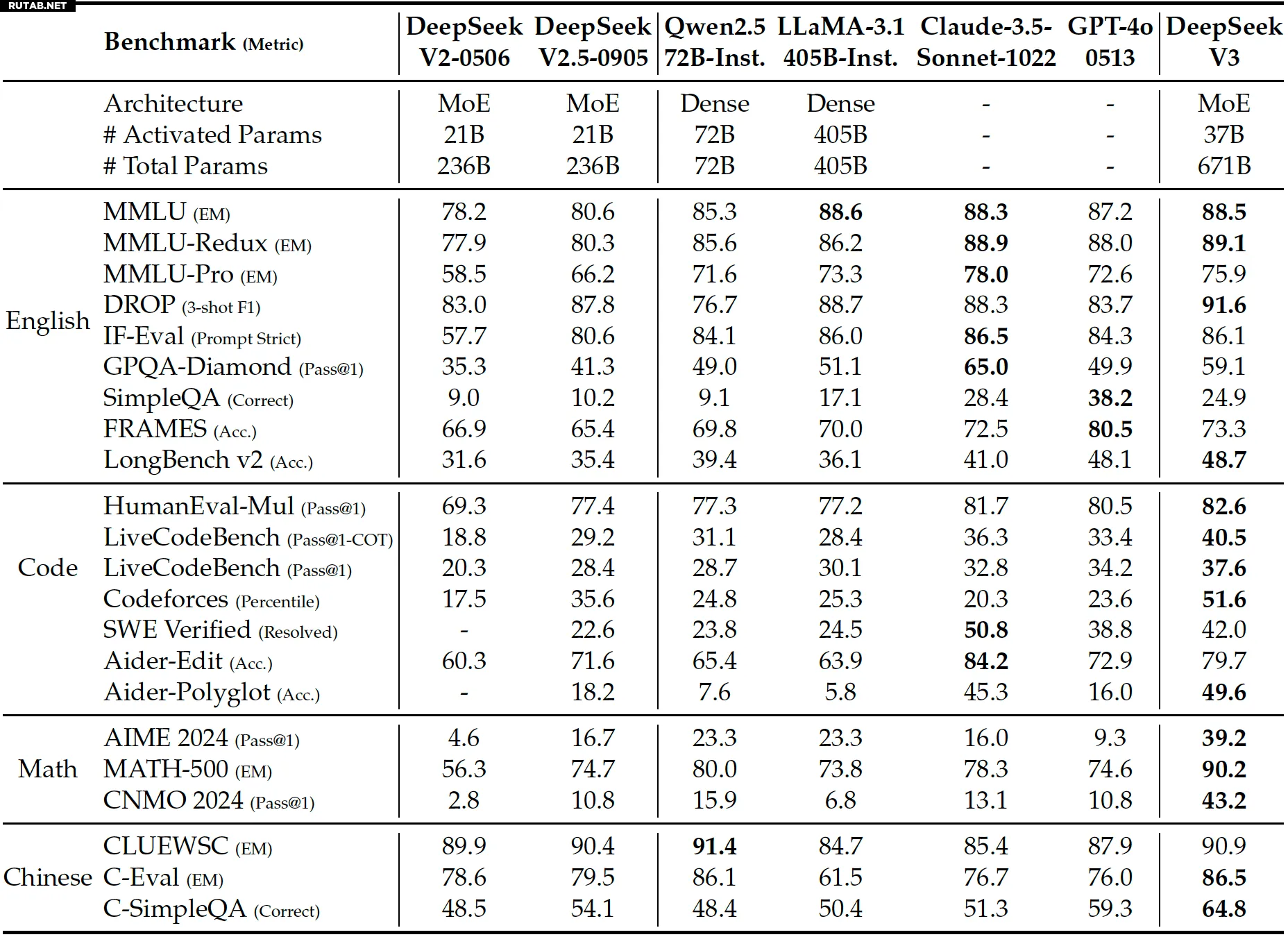
Что касается производительности, компания утверждает, что языковая модель DeepSeek-v3 MoE сопоставима или превосходит GPT-4x, Claude-3.5-Sonnet и LLlama-3.1, в зависимости от бенчмарка. Естественно, нам придется увидеть, как это доказано сторонними бенчмарками. Компания открыла исходный код модели и весов, поэтому можно ожидать, что тестирование появится скоро.
Изображение: DeepSeek
Хотя DeepSeek-V3 может отставать от передовых моделей, таких как GPT-4o или o3, с точки зрения количества параметров или возможностей рассуждения, достижения DeepSeek указывают на то, что возможно обучить продвинутую языковую модель MoE, используя относительно ограниченные ресурсы. Конечно, это требует множества оптимизаций и низкоуровневого программирования, но результаты кажутся на удивление хорошими.
Команда DeepSeek понимает, что для развертывания модели DeepSeek-V3 требуется современное оборудование, а также стратегия развертывания, разделяющая этапы предварительного заполнения и декодирования, что может быть недостижимо для небольших компаний из-за нехватки ресурсов.
«Признавая его высокую производительность и экономическую эффективность, мы также признаем, что DeepSeek-V3 имеет некоторые ограничения, особенно в плане развертывания», — говорится в документе компании. «Во-первых, для обеспечения эффективного вывода рекомендуемая единица развертывания для DeepSeek-V3 относительно велика, что может стать бременем для небольших команд. Во-вторых, хотя наша стратегия развертывания для DeepSeek-V3 достигла скорости генерации от начала до конца более чем в два раза выше, чем у DeepSeek-V2, все еще остается потенциал для дальнейшего улучшения. К счастью, ожидается, что эти ограничения будут естественным образом устранены с разработкой более совершенного оборудования».
Источник: Tomshardware.com
0 комментариев