Производительность AMD MI300X по сравнению с Nvidia H100 в низкоуровневых тестах и тестах вывода

Advanced Micro Devices, Inc. (AMD, дословный перевод с англ. — «передовые микроустройства») — производитель интегральной микросхемной электроники. Второй по объему производства и продаж производитель процессоров архитектуры x86 c долей рынка 16,9 %▲(2014), а также один из крупнейших производителей графических процессоров (после приобретения ATI Technologies в 2006 году), чипсетов для материнских плат и флеш-памяти. Компания с 2009 года не имеет собственного производства и размещает заказы на мощностях других компаний. Википедия
Читайте также:AMD MI300X — самый быстрый результат в истории Geekbench 6 OpenCLAMD: суперкомпьютер с 1,2 млн GPU составит конкуренцию NvidiaAMD Ryzen AI 9 HX 370 превосходит лучший мобильный чип компанииAMD Strix Halo тестируется со 128 ГБ оперативной памятиРанние тесты процессоров Zen 5 подтверждают заявления AMD о IPC
NVIDIA Corporation (NASDAQ: NVDA) — американская компания, один из крупнейших разработчиков графических ускорителей и процессоров, а также наборов системной логики. На рынке продукция компании известна под такими торговыми марками как GeForce, nForce, Quadro, Tesla, ION и Tegra. Компания была основана в 1993 году. По состоянию на август 2006 года в корпорации насчитывалось более 8 тысяч сотрудников, работающих в 40 офисах по всему миру. Википедия
Читайте также:Nvidia RTX 4070 Ti Super с кремниевыми поверхностями AD102AMD: суперкомпьютер с 1,2 млн GPU составит конкуренцию NvidiaNvidia только что потеряла 500 миллиардов долларов за три дня, но это ничего не значитNvidia продаст процессоры ИИ странам Ближнего ВостокаDLSS следующего поколения от Nvidia может использовать искусственный интеллект
Однако, прежде чем мы начнем, стоит упомянуть множество предостережений. В статье Chips and Cheese не упоминается, какой уровень настройки был выполнен в различных тестовых системах, а программное обеспечение может оказать серьезное влияние на производительность — например, Nvidia заявляет, что с момента запуска удвоила производительность вывода H100 за счет обновлений программного обеспечения. Chips and Cheese также упоминает о конкретной помощи со стороны AMD при тестировании, но, похоже, не получила аналогичной информации от Nvidia, поэтому в результатах тестов может быть некоторая предвзятость. Chips and Cheese также сравнивает MI300X в первую очередь с PCIe-версией H100, которая является самой слабой версией H100 с самыми низкими характеристиками.
Если оставить в стороне предостережения, то низкоуровневые тесты Chips and Cheese показывают, что MI300X, построенный на новейшей архитектуре AMD CDNA 3, представляет собой хороший дизайн с аппаратной точки зрения. Производительность кэширования чипа выглядит просто впечатляющей благодаря сочетанию в общей сложности четырех кэшей, включая кэш L1 объемом 32 КБ, скалярный кэш объемом 16 КБ, кэш L2 объемом 4 МБ и массивный кэш Infinity объемом 256 МБ (который служит кэшем L3). CDNA 3 — это первая архитектура, унаследовавшая Infinity Cache, которая впервые была представлена на RDNA 2 (игровая графическая архитектура AMD второго поколения, используемая в серии RX 6000).
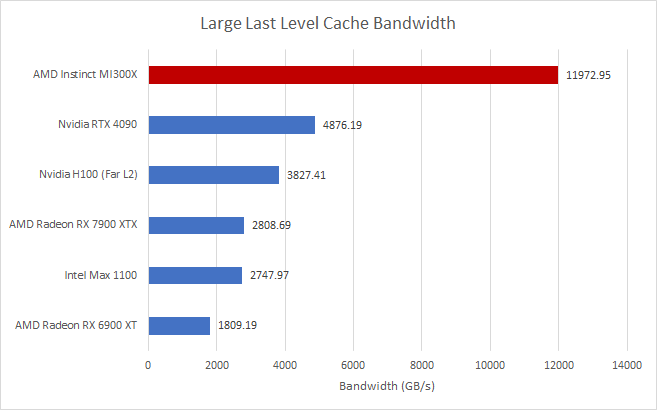
Изображение: Чипсы и сыр
Пропускная способность — метрическая характеристика, показывающая соотношение предельного количества проходящих единиц (информации, предметов, объёма) в единицу времени через канал, систему, узел. Используется в различных сферах: в связи и информатике П. С. — предельно достижимое количество проходящей информации; в транспорте П. С. — количество единиц транспорта; в машиностроении — объём проходящего воздуха (масла, смазки); в электромагнетизме (оптике, акустике) — отношение потока энергии, прошедшего сквозь тело к потоку, который падает на это тело. Сумма пропускной способности, поглотительной способности и отражательной способности равна единице (см. также Прозрачность среды). Википедия
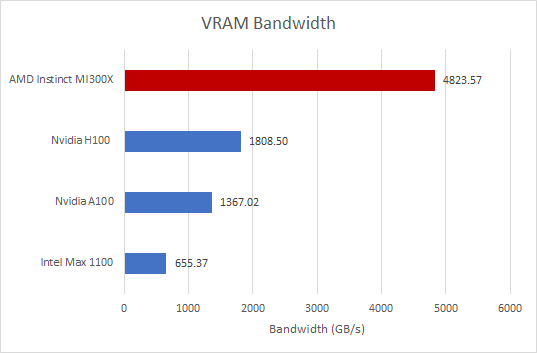
Изображение: Чипсы и сыр
Подобные преимущества также распространены в производительности видеопамяти и локальной памяти MI300X (т. е. скалярного кэша). Графический процессор AMD имеет в 2,72 раза больше локальной памяти HBM3 и в 2,66 раза большую пропускную способность видеопамяти, чем H100. Единственная область в тестах памяти, где графический процессор AMD проигрывает, — это результаты по задержке памяти, где H100 на 57% быстрее.
Имейте в виду, что опять же речь идет о карте H100 PCIe самой низкой спецификации с 80 ГБ HBM2E. Более поздние версии, такие как H200, включают до 141 ГБ HBM3E с пропускной способностью до 4,8 ТБ/с. Вариант H100 SXM также имеет значительно более быстрый HBM, обеспечивающий пропускную способность до 3,35 ТБ/с, поэтому использование карты Chips and Cheese с пропускной способностью 1,8 ТБ/с явно снижает производительность.
Двигаясь дальше, производительность вычислений — это еще одна категория, в которой Chips and Cheese увидели, что MI300X доминирует над графическим процессором Nvidia H100. Пропускная способность инструкций смехотворно высока в пользу чипа AMD. Иногда MI300X был в 5 раз быстрее, чем H100, а в худшем случае — примерно на 40 % быстрее. Результаты производительности инструкций Chips and Cheese учитывают вычисления INT32, FP32, FP16 и INT8.
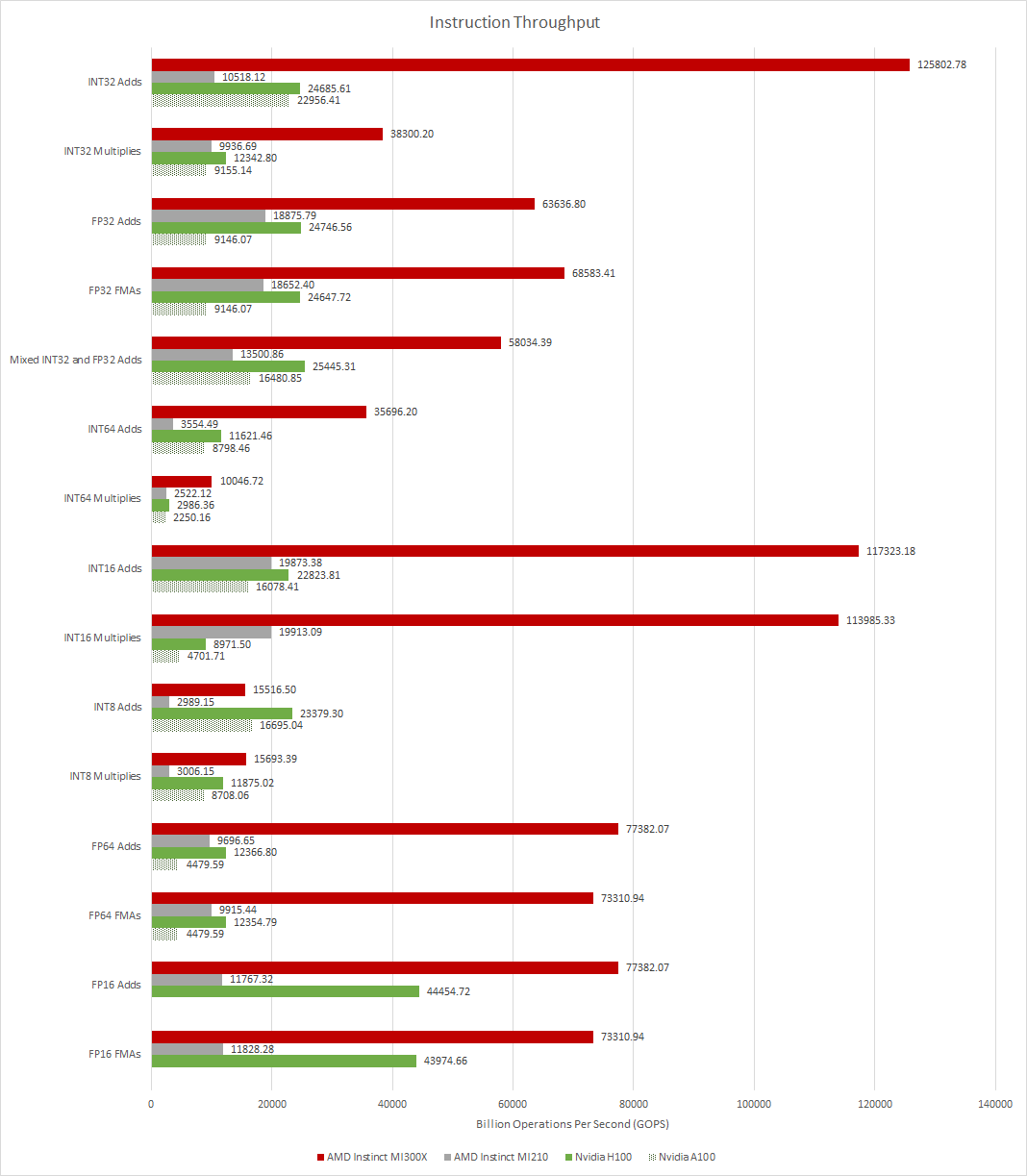
(Изображение предоставлено: Чипсы и сыр)
(Изображение предоставлено: Чипсы и сыр)
(Изображение предоставлено: Чипсы и сыр)
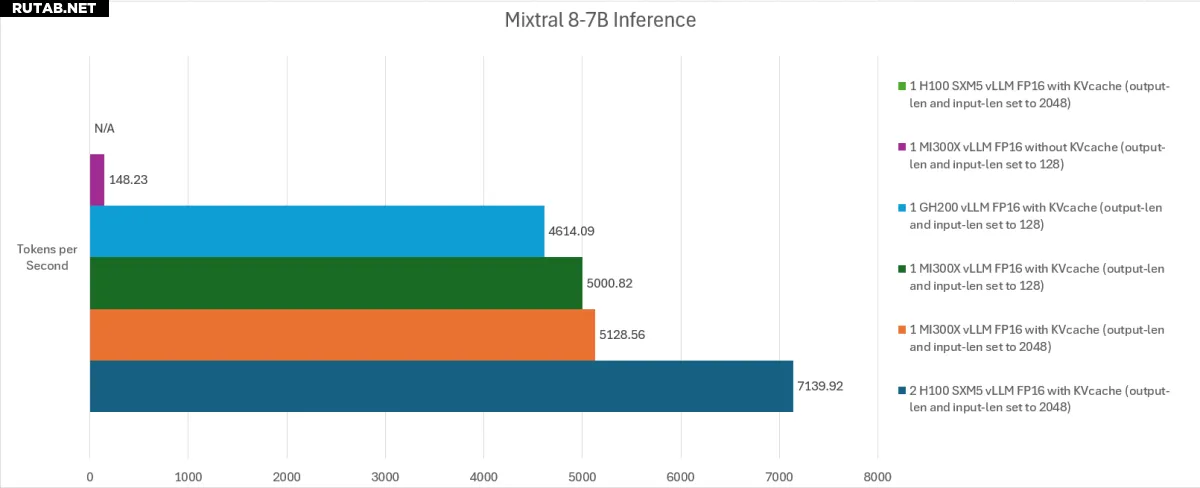
Одним из последних и, вероятно, наиболее важных тестов, проведенных Chips and Cheese, было тестирование искусственного интеллекта не только с MI300X и H100, но и с GH200 (для одного из тестов). Компания Chips and Cheese's провела два теста с использованием Mixtral 8-7B и LLaMA3-70B. Любопытно, что аппаратные конфигурации здесь начинают становиться более разнообразными и противоречивыми.
Результаты Mixtral показывают, как различные варианты конфигурации могут иметь большое значение — например, на одной карте H100 емкостью 80 ГБ не хватает памяти, в то время как MI300X без KVcache также работает плохо. GH200 работает намного лучше, хотя MI300X по-прежнему лидирует, а два графических процессора H100 SXM5 достигают производительности примерно на 40 % выше. (Два графических процессора H100 были необходимы даже для того, чтобы попытаться запустить модель с выбранными настройками.)
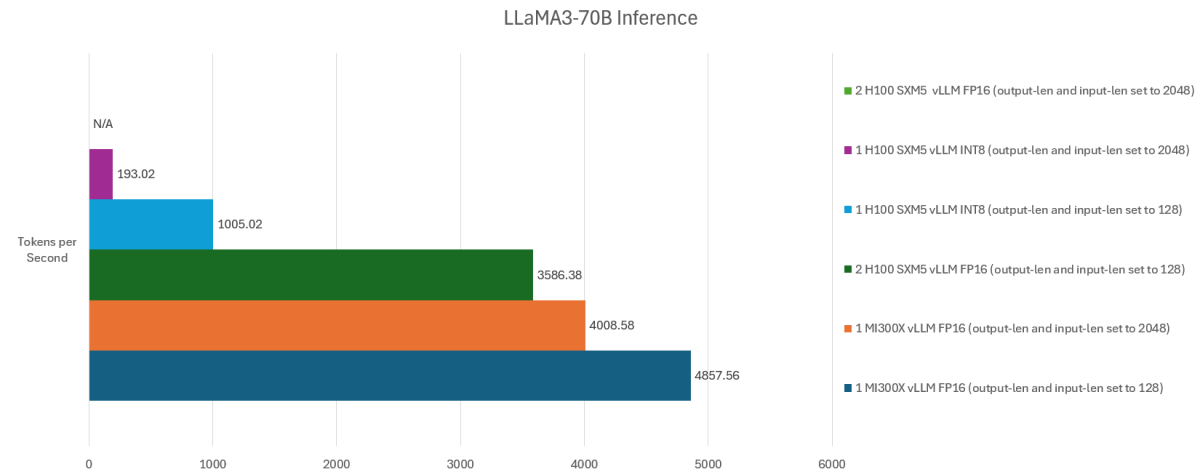
Переходя к результатам LLaMA3-70B, мы получаем другой набор оборудования. На этот раз даже два графических процессора H100 не смогли запустить модель из-за нехватки памяти (с длиной ввода и вывода, установленной на 2048, и использованием FP16). H100 с INT8 также работал довольно плохо при той же настройке длины ввода/вывода 2048. Уменьшение длины до 128 значительно улучшило производительность, хотя она все еще сильно отставала от MI300X. Два графических процессора H100 с длиной ввода/вывода 128, использующие INT8, наконец-то начинают выглядеть хотя бы в некоторой степени конкурентоспособными.
MI300X с его огромной памятью в 192 ГБ мог работать как с длиной 2048, так и с длиной 128, используя FP16, причем последний обеспечивал лучший результат - 4858. Любопытно, что H200 от Nvidia был исключен из этого тестирования, что потенциально могло бы дать лучшие результаты. чем то, что было показано, но не было предоставлено никаких подробностей о том, почему использовались тесты и настройки.
Отнеситесь к этим результатам скептически.
Хотя результаты вычислений и производительности кэша показывают, насколько мощным может быть процессор AMD MI300X, тесты ИИ ясно демонстрируют, что настройка вывода ИИ может стать разницей между продуктом с ужасной производительностью и продуктом, ведущим в своем классе. Самая большая проблема, с которой мы сейчас сталкиваемся в отношении результатов ИИ в целом, заключается в том, что мы не знаем, насколько оптимизирован стек программного обеспечения для каждого графического процессора.
Во введении говорится: «Мы также хотели бы поблагодарить Элио из NScale, который помог нам оптимизировать наши прогоны LLM, а также нескольких людей из AMD, которые помогли убедиться, что наши результаты воспроизводимы на других системах MI300X». Никаких упоминаний о каких-либо консультациях с представителями Nvidia не упоминается, а это говорит о том, что это скорее взгляд на MI300X, спонсируемый AMD.
Заключение начинается со слов «Заключительные слова: атака на аппаратное доминирование NVIDIA». Это определенно намерение AMD, а архитектура CDNA 3 и MI300X — шаг в правильном направлении. Однако, как мы видели на многих других тестах оборудования искусственного интеллекта для центров обработки данных, и как утверждает сам сайт, «дьявол кроется в деталях». От использования явно более медленной карты PCIe H100 для большинства тестов до выборочных результатов, явно есть некоторые вопросы относительно особенностей тестирования. Мы видели, как Nvidia подвергала сомнению ранее опубликованные данные о производительности AMD и Intel, например, указывая на использование неоптимальных настроек.
Результаты необработанного кэша, пропускной способности и вычислений MI300X выглядят очень хорошо. Но эти графические процессоры также специально созданы для горизонтального масштабирования и больших установок, поэтому даже если один MI300X явно превосходит одиночный H100 (или H200, если на то пошло), это не говорит о том, как картина может измениться с десятками, сотнями или даже тысячами. графических процессоров, работающих в тандеме. Программное обеспечение и экосистема также важны, и в прошлом Nvidia удерживала лидерство с CUDA. Низкоуровневые тесты такого оборудования могут быть интересными, и эти результаты показывают, что происходит, когда вашему графическому процессору не хватает видеопамяти для конкретной модели. Но мы подозреваем, что это далеко не последнее слово в отношении AMD MI300X и Nvidia H100.
Источник: Tomshardware.com
0 комментариев